华为诺亚方舟伦敦实验室推出鲁棒强化学习新算法

论文地址:https://arxiv.org/abs/1907.13196
作者 | 汪军团队
编辑 | 唐里
这是汪军教授带领的华为诺亚方舟实验室伦敦团队在安全可信AI方向上的新成果,可以广泛应用到实际场景,例如自动驾驶,企业运筹,物流等等决策领域上。据悉,UCL汪军教授已学术休假,担任华为诺亚方舟实验室决策推理首席科学家。
背景
近年来,强化学习在多项任务(如围棋,电脑游戏)中有着令人惊艳的表现。强化学习算法依赖大量采样的特性决定了其需要首先在仿真环境中进行训练再迁移到现实系统中。然而,由一般强化学习算法训练产生的策略往往容易过拟合在虚拟的仿真环境上,一旦仿真环境和现实系统无法完全匹配,策略的迁移过程将会困难重重。几个常见的例子如机器人控制问题中关节的阻尼无法被准确测量,或是自动驾驶问题中汽车和地面间的摩擦力会根据轮胎和路况而改变。希望依靠仿真环境去完全还原现实系统并针对不同的仿真环境参数去训练不同的策略显然是不现实的。这一问题严重影响了强化学习算法的实用性。
优化问题的定义
本文我们提出一种新的鲁棒强化学习算法。我们将强化学习的鲁棒性问题抽象成了一个策略和仿真模型之间的有约束的极大-极小化问题。将策略和仿真环境分别用θ和φ参数化,无约束形式的极大-极小化问题可以表达为
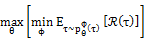
其中轨迹τ的分布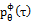
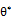
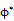
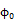
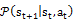
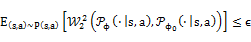
其中状态s和动作a的联合分布P(s,a)由一个均匀分布策略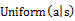
优化问题的求解
在优化问题的求解方面,我们可以选用任意的策略搜索算法去求解外层关于策略参数θ的极大化问题。我们把目标函数在当前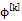
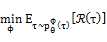
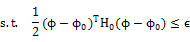
相应的φ的更新规则可通过求该QCLP问题的解析解得到
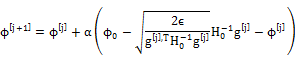
其中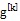
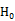
零阶优化
之前所述的优化问题的求解过程中,环境参数φ的更新建立在我们能够获得目标函数的梯度以及约束的Hessian矩阵的基础上。但在大多数应用中,该条件是难以得到满足的。例如,无模型的强化学习普遍依赖从以微分方程求解器为基础的仿真环境中获取采样,这直接导致目标函数和约束对于环境参数φ不可微。考虑到基于模型的强化学习在高维复杂的任务中表现平平,学习一个对于参数可微的环境模型去替代仿真环境并不是一个可行选择。该条件难以满足的另一个原因在于,约束中的Wasserstein距离仅在转移概率分布
为了扩展算法的应用范围,我们提出了针对该优化问题的零阶解法,仅通过目标函数和约束的函数值来估计优化所需的梯度和Hessian矩阵。我们采用evolution strategy去估计目标函数对于φ的梯度:
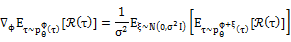
并将该方法扩展至二阶去估计约束在
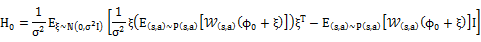
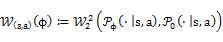
实验
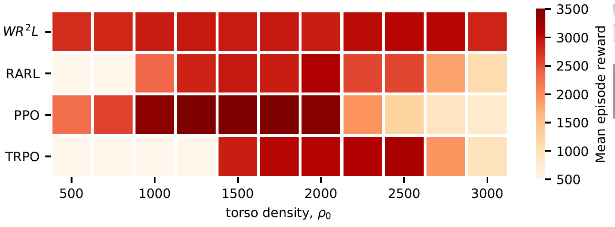
我们在Cartpole,Hopper,Walker2D和Halfcheetah四个MuJoCo机器人控制环境中测试了WR2L,并和若干基线进行了比较。作为基线的算法包含TRPO和PPO两个通用的策略搜索算法以及RARL鲁棒策略搜索算法。每个环境模型被参数化为若干物理量组成的向量,如机器人躯干密度,地面摩擦力等。通过WR2L训练的策略在所有测试任务中都显示出了很强的鲁棒性,和基线相比性能有明显的提升。
一维环境实验结果
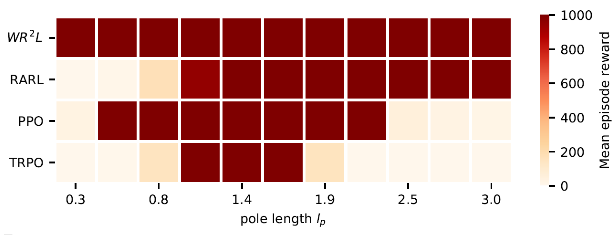
Invpendulum, reference
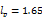
Hopper, reference
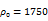
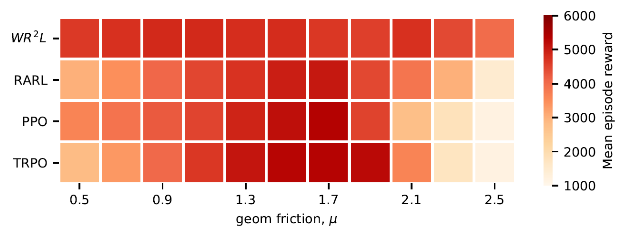
Halfcheetah, reference
Halfcheetah, reference
二维环境实验结果
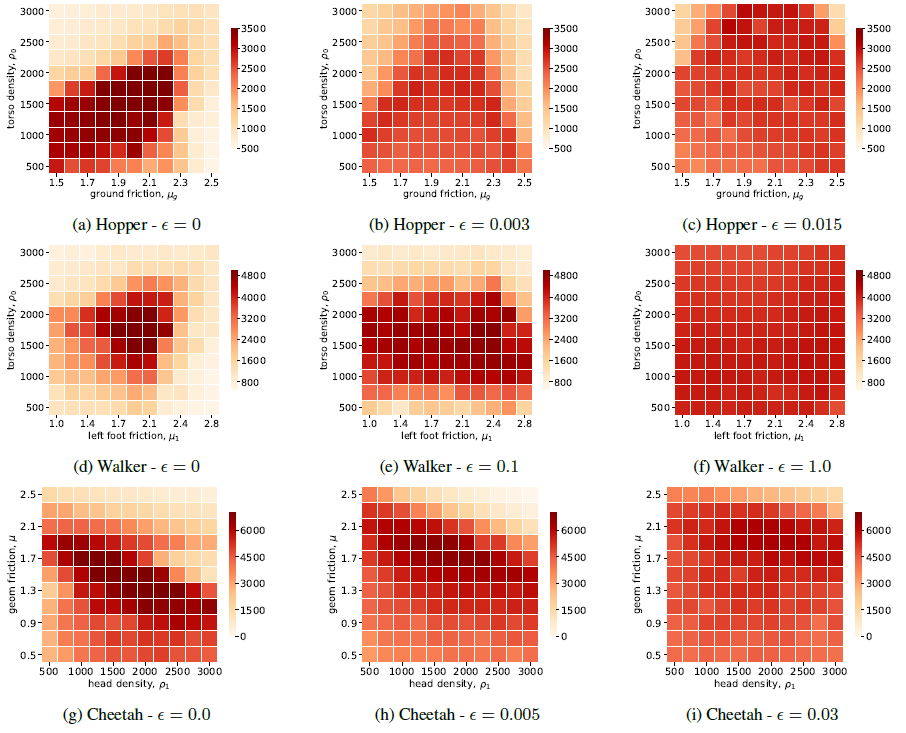
高维环境实验结果
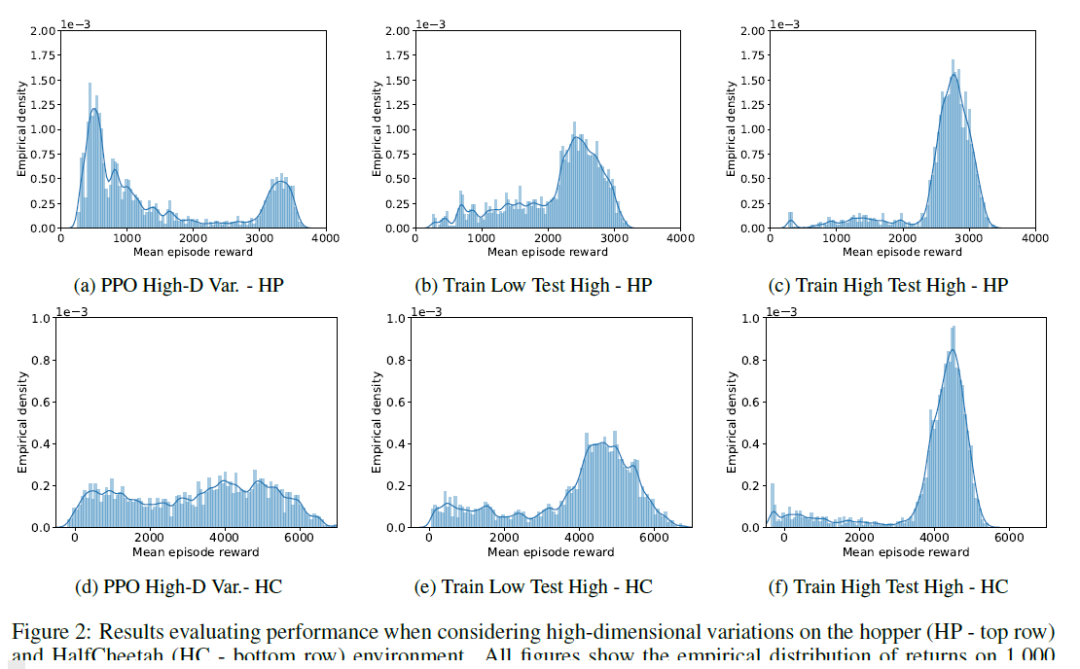
评论
汪军教授对该工作的评论:决策系统的安全鲁棒抗干扰能力一直是阻碍强化学习算法落地应用的一个大障碍。这是在安全可信AI方向上的新成果,可以广泛应用到实际场景,例如自动驾驶,企业运筹,物流等等决策领域上。
Haitham Ammar教授对该工作的评论:考虑到仿真环境和现实系统之间的不匹配,智能体测率对于环境动力学的鲁棒性是强化学习能否实用的关键因素。本文我们提出了鲁棒强化学习的新算法,并在若干个标准测试任务中取得了SOTA的表现。我们相信该算法将会推动华为在自动决策领域的进一步发展。
致谢
感谢华为伦敦研究所汪军教授, Haitham Ammar教授和杨耀东在本文写作过程中给予的支持和意见。


张钹院士:人工智能的魅力就是它永远在路上 | CCAI 2019
Facebook 自然语言处理新突破:新模型能力赶超人类 & 超难 NLP 新基准
巴赫涂鸦创作者 Anna Huang 现身上海,倾情讲解「音乐生成」两大算法

点击“阅读原文”加入强化学习论文讨论小组



