基于动态协同网络(DCN)的问答模型

作者:Salesforce Research
翻译:Ying wang
01
DCN模型
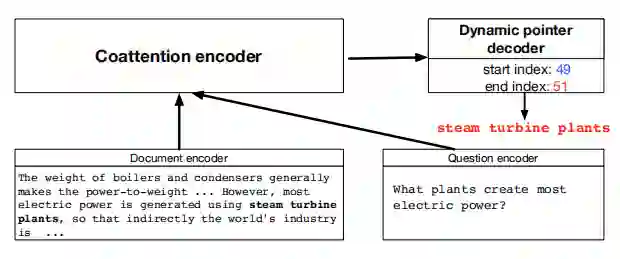
从结构图中可以看出,模型共有两部分,第一部分是编码部分,主要实现对文档-问题的语意表示,第二部分是动态解码,采用迭代方式对预测答案位置进行更新。
encoder
所谓编码,就是将输入的序列转变成一个固定长度的向量,具体实现的时候,编码器的选择不是固定不变的,可选的有CNN/RNN/GRU/LSTM等等,作者本文采用的是LSTM。
文中,作者用(x_1^Q,x_2^Q,…,x_n^Q) 表示问题中的词序列,(x_1^D,x_2^D,…,x_n^D)表示文档中的词序列。LSTM中当前时间的隐藏状态是由上一时间的状态和当前时间输入决定的,也就是d_t=LSTM_{enc}(d_{t-1},x_t^D) ,获得各个时间段的隐藏层之后,再将隐藏层的信息汇总,生成最后的文档信息编码矩阵(即文本的特征信息)D=[{d_1\quad d_2…d_m\quad d_\phi}]
对于question中的定义,换汤不换药,同样采用LSTM网络,q_t=LSTM_{enc}(q_{t-1},x_t^Q) ,并将隐藏层信息矩阵Q'=[{q_1\quad q_2…d_m\quad q_\phi}]定义为一个中间量,这样做是为了使问题的encode space能够变换成文本的encode space,并对 Q'作一个非线性变换,问题信息编码矩阵最后表示为
Q=tanh(W^{(Q)}Q'+b^{(Q)})
Coattention encoder
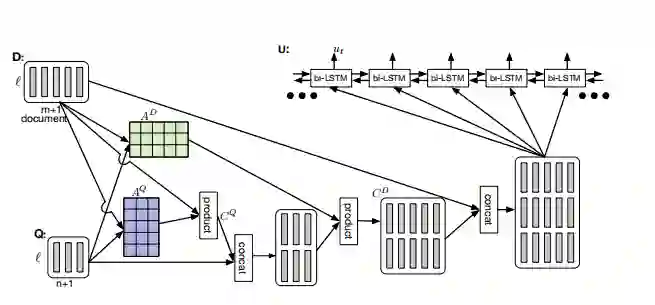
基于上述文档信息矩阵D与问题信息矩阵Q,结合两个矩阵的信息:
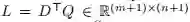
m为文档的长度,n为question的长度。对L矩阵分别按行(row-wise)和按列(column-wise)求Softmax,就可以得到对问题和文档的Attention矩阵:
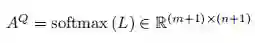
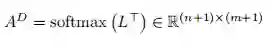
这里矩阵A^Q对于文档中的每个单词,question中的每个单词都有对应的 normalized attention,矩阵A^D同理。然后,将attention应用到问题中:
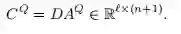
同样,将attention应用到文档中,计算QA^D 。作者在论文中提到,[Cui et al.2016]论文中的思想,将问题信息attention之后的C^Q 对文档进行attention,即C^Q A^D,又因为这两部分是平行的,并且都要与A^D相乘,因此可以将两部分写成如下形式:
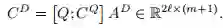
这里的是Co-attention信息结合的体现。最后,通过双向LSTM将时间融合到当前的内容中。
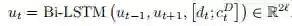
dynamic pointing decoder

此部分主要就是找出预测文档中的片段作为最终的答案,作者提出了动态迭代的方式,通过反复迭代来预测起始位置和终止位置,从而确定最终答案。整个迭代过程就是上一次预测的结果以及encoder的信息通过LSTM获得当前时刻的预测结果,其数学表达如下:
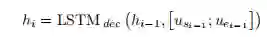
这里,h_{i-1}表示历史预测信息,下标s_{i-1},e_{i-1}分别表示上一次预测的起始位置和终止位置。作者将每次的预测结果都输入到LSTM中进行保存,得到当前的隐藏状态h_i,作者又提出采用Highway Maxout Networks(HMN)模型对文档中的每一个字,分别把它作为起始位置和终止位置两个方面进行打分获得\alpha_t,\beta_t,其数学表达如下:
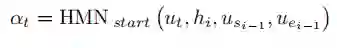
上式为起始位置的打分公式,其中u_t表示文档中第t个字的encoder信息。终止位置的计算方式跟起始位置的计算方式相似,但是用的是另外一个HMN的模型(因为起始位置的模型与终止位置模型结构相同但参数不共享)。
获得所有字的scores之后,选取得分最高的\alpha_t位置作为起始位置,得分最高的\beta_t位置为终止位置。
什么是HMN呢?
它基于Highway Network和Maxout。
Highway Network其核心思想是将网络的某一层输出,跳着连到更后面的一层作为输入。
Maxout是一种可学习的激活函数,其思想在于对每一个神经元的输出,都通过参数进行加权变换,得到的最大值作为最终输出。
下图为HMN的结构图:
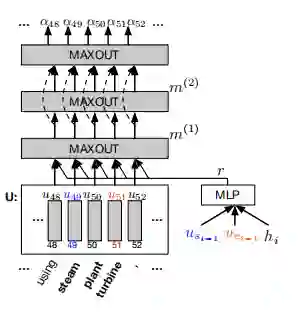
先将u_{s_{i-1}},u_{e_{i-1}},h_i拼接后通过MLP得到r,再将解码信息u_t和r拼接后通过maxout层输出m^{(1)},第二层的输出m^{(2)}是将第一层的输出作为输入并通过maxout激活,最后一层将第一层的输出与第二层的输出拼接,整个流程的公式如下:

02
实验
实验细节
实验数据集为SQuAD,使用Stanford CoreNLP标记器对语料库进行预处理,使用在840B Common Crawl语料库上预训练的GloVe词向量。将词汇量限制为Common Crawl语料库中存在的单词,并将词汇表外单词的嵌入设置为零。在训练期间使用最大序列长度600,对于所有循环单元,maxout层和线性层使用隐藏状态大小200。所有LSTM都随机初始化参数,初始状态为零。Sentinel向量在训练期间随机初始化和优化。对于动态解码器,将最大迭代次数设置为4,maxout pool大小为16,并使用ADAM优化模型,所有模型都使用Chainer。
实验结果
在数据集SQuAD上,有两个评估指标。EM计算模型预测的答案与真实答案之间确切字符串的匹配,F1计算预测答案中的单词与真实答案之间的重叠。因为一个文档-问题对可能对应几个真实答案,所以EM和F1被视为对应文档-问题对的所有真实答案中的最大值。
与其他模型相比,SQuAD数据集的DCN模型的性能如下表所示。从表中可以看出无论是单模型DCN还是整体DCN都排名第一。

DCN能够多次估计答案跨度的起点和终点,每次都以其先前的估计为条件,如下图所示的3个实例,问题1,其中模型最初有不正确的起点和正确的 。在随后的迭代中,模型调整起点,最终到达迭代3中的正确起点。类似地,模型逐渐将终点的概率质量移动到正确的单词。

作者在实验中使用2层MLP代替HMN来测试HMN maxout层的池的大小,实验数据显示(如下图)pool的大小为16时模型性能更好。

DCN的性能是如何随文档长度变化的?从下图的实验结果可以看出协同注意力编码器对于长文档很大程度上是不可知的,其性能并没有随着文档的长度呈骤降趋势。我们可以看到,答案越长,性能就会越低。
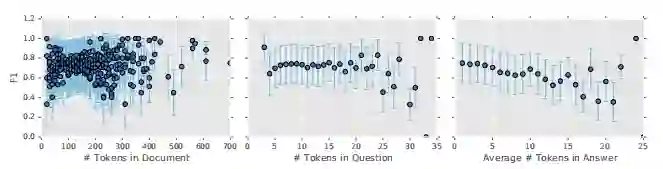
同时,作者从不同问题的角度也分析了模型性能,从下图的统计结果可以看出,DCN更擅长“when”的问题。

-END-
专 · 知
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎登录www.zhuanzhi.ai,注册登录专知,获取更多AI知识资料!
欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询技术商务合作~

专知《深度学习:算法到实战》课程全部完成!560+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程




