笨笨功能更新啦!基于BERT的FAQ语义检索
基于BERT的FAQ语义检索
我们采用的方案框架如下图所示,主要包括 Sentence-BERT 模型离线训练、语义向量离线索引、线上推理三个部分。
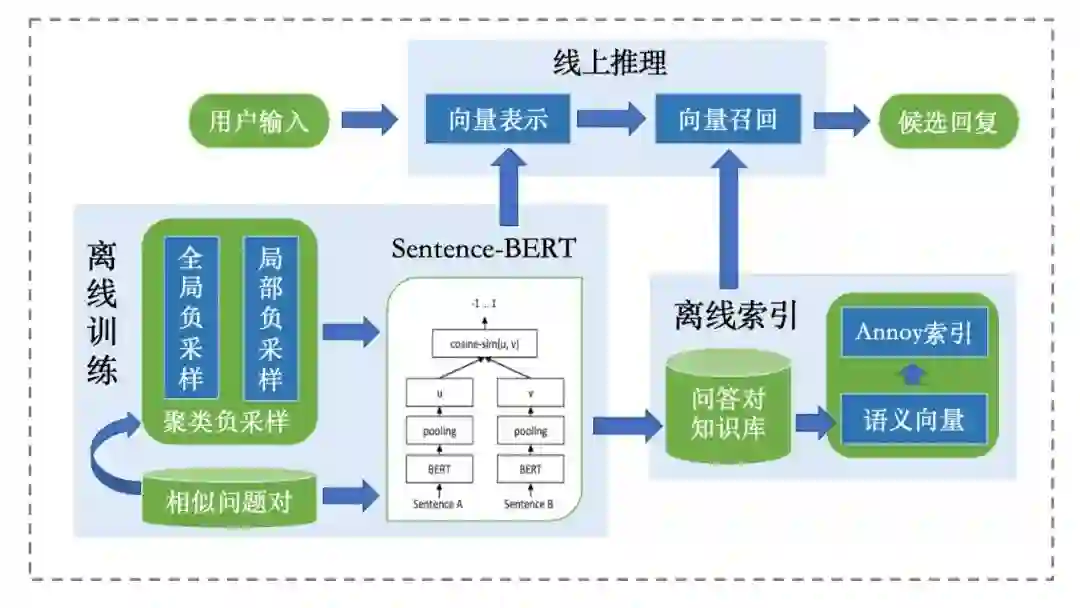
框架结构示意
借鉴经典的孪生网络结构(SiameseNetwork),我们使用 BERT 模型分别对问题对编码,然后使用池化操作得到问题向量表示,并计算问题对之间的余弦相似度,最后通过对比损失函数(Contrastive Loss)训练得到 Sentence-BERT 模型。
在训练 Sentence-BERT 模型中,我们需要构造正负样本的问题对。对于已有的大规模 FAQ 问答语料,每个问题包含多种不同的表达形式(即相似问题对),我们通过随机采样构造正样本。构造负样本的最简单方法则是根据一定的概率从所有问题中随机选择不同的问题构造全局负样本,但得到的负样本比较简单、容易区分,不利于 Sentence-BERT 学习到有用的语义信息。为了构造模型难以区分的、具有高质量的负样本,我们采用基于聚类的局部负采样方法:首先使用 BERT 模型对所有问题进行向量表示,然后通过 Kmeans 进行问题向量聚类,在每个聚类中采样具有一定相似度但属于不同问题的负样本问题对。最终我们以一定的比例混合全局和局部负样本。
通过封闭知识库召回实验得到如下表结果,可以发现我们采用的基于聚类负采样(NS)进行微调(FT)的 Sentence-BERT 模型,召回效果优于直接使用开源的 BERT 模型检索以及线上基于 Lucene 的检索系统。考虑到线上推理速度,我们采用6层模型(6L)进行线上推理,其测试召回效果略差于12层模型。
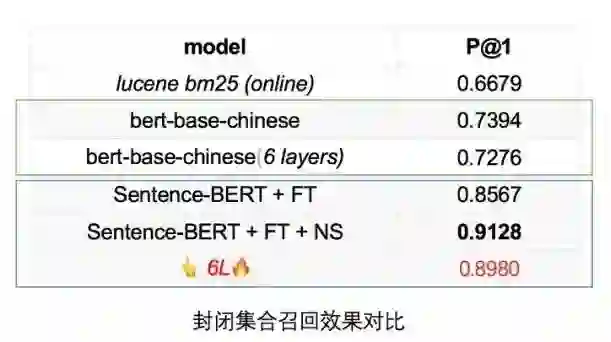

实验效果
由于知识库规模较大,为了加快线上召回速度,我们需要离线计算好所有问题的的向量表示,并结合向量检索工具 Annoy(https://github.com/spotify/annoy)进行向量索引和召回(在可接受范围内牺牲一定的精度)。如上表所示,在4核8G服务器上,100个用户并发情况下,基于 Sentence-BERT 和 Annoy 进行向量召回的速度略差于使用Lucene 的关键词倒排索引召回。最终我们将向量召回结果加入到已有模块的候选回复集合中进行回复重排序和返回。
我们将持续进行“笨笨”功能更新,欢迎大家体验、反馈和交流。
关于“笨笨”
欢迎扫描二维码关注“笨笨”微信公众号。




