大数据|结构化存储云HBase技术架构及最佳实践
全球人工智能:一家人工智能技术学习平台。旗下有:Paper学院、商业学院、科普学院,技术学院和职业学院五大业务。拥有十几万AI开发者和学习者用户,1万多名AI技术专家。我们诚邀全球的AI技术专家、AI创业者和AI投资者来Paper学院和商业学院演讲,分享您最新的技术研究成果和商业观点!
摘要: 本文中,阿里云高级专家封神带来了主题演讲《大数据时代结构化存储云HBase技术架构及最佳实践》,介绍HBase的应用选择、实战案例、技术平台解读以及后续的规划。
在10年,阿里研究HBase,是为了解决阿里容量及并发的实际问题,按照数据库要求,阿里深入HBase技术,并致力于保障稳定性和性能,目前已经有10000台规模,数百个集群,大约1亿的QPS,服务整个集团的业务。17年,把这部分能力也开放给公有云客户。本文中,阿里云高级专家封神带来了主题演讲《大数据时代结构化存储云HBase技术架构及最佳实践》,介绍HBase的应用选择、实战案例、技术平台解读以及后续的规划。
为什么应用HBase
一般而言,传统关系型数据库面临着成本、容量、QPS、分析等多方面的问题:存储成本较高;无法满足TB、PB级别的数量存储需求;QPS无法满足较高的并发要求,性能不能横向扩展;数据隔离,从而不能满足分析类的需求。
通过关系型数据库MySQL,可以解决中小数据库存储需求;通过分库分表,能够解决一定容量及并发的需求,但是其实现复杂,需要业务感知;通过以HBase为代表的分布式数据库,可以支持高到千万的并发,满足海量数据的存储。
那么怎么解决传统数据库这些问题呢?HBase给出了相应的应对方法:
LSM-Tree:写吞吐高,离线导入效率高;
存储无限扩容:计算存储分离,分布式存储可以无限扩容;
自动分区:分区自动分裂,分区自动Merge;
Hadoop生态:Phoenix满足查询需求,Spark接HBase,可以满足分析类需求。
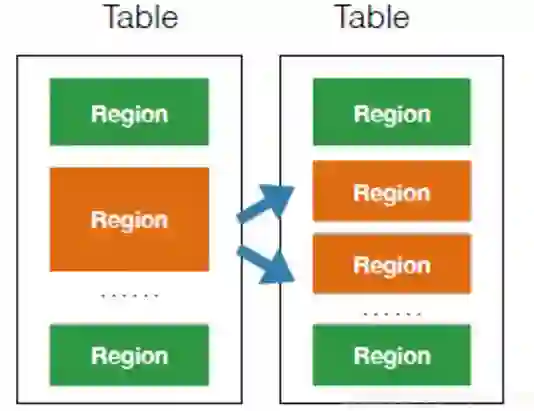
HBase除了可以满足业务较快增长的高吞吐以及大容量读取需求,还有其他传统关系型数据库和非关系型数据库所不具备的特性:比如松散表(不存数据,不占空间);实时更新、增量导入、多维删除;随机查询、范围查询。
此外,HBase还有许多其他特性:
LSM树:实时写入吞吐量大,增量导入隔离性强;
TTL:数据时效性,系统自动处理;
多版本:数据的第三维度,高效删除方式;
动态列:数据发散的利器;
协处理器:满足数据高效处理;
SQL访问:二级索引;
即时查询:操作性查询,准实时。
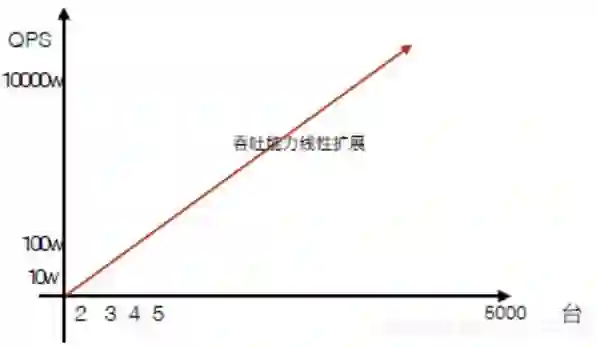
HBase的能力是完全可以线性扩展的,通过添加节点就可以线性增强计算存储能力。
应用实战
HBase具有丰富的应用场景,凭借海量的存储能力和高吞吐能力,为各种应用场景提供支持,包括报表类、时序类、日志类、消息类、推荐类、风控类、轨迹类,行业包括电子商务、物联网/车联网、聊天软件、金融、广告商、新闻、电信等等。
HBase具有庞大的生态圈,支持实时数据分析、即时分析、多维分析、时序数据库等场景。
在阿里内部,HBase的使用涉及日志、聊天、监控、订单、IOT、风控、搜索等。中国使用的公司还有京东、小米、腾讯、网易、360、知乎、中国人寿、电信......几乎所有的一定规模的公司。
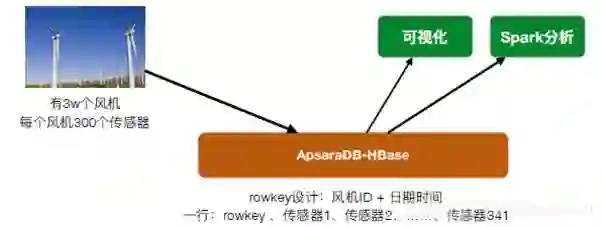
实际案例——传感器监控类
在rowkey有一定的设计规则,业务系统会做一些优化,比如把多行压成一行等等。
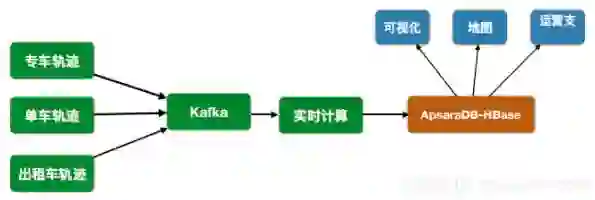
实际案例——单车/司机轨迹
轨迹类应用可以满足离线大规模的轨迹分析,满足用户、后端人员的实时查询。
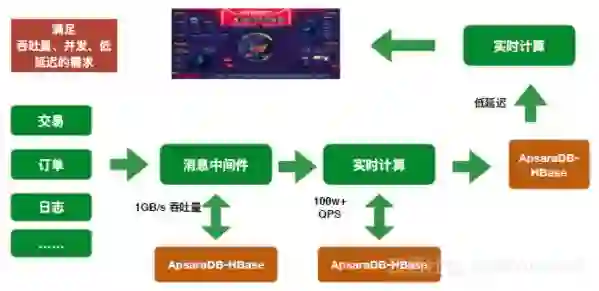
实际案例——双十一大屏
这是阿里内部非常具有代表性的场景。高吞吐、高并发、低延迟的访问需求下,对HBase应用提出了很高的要求。
实际案例——安全风控
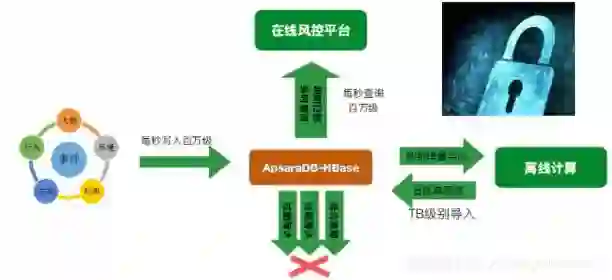
在金融的战场上,用户画像、风控一直也是核心之一,一般的数据也是存储在HBase。
实际案例——搜索
搜索是HBase最先解决的一个场景,目标是为了存储互联网,流式计算实时处理后再导入到搜索引擎。

实际案例——分析类

以上分享的场景都在阿里内部及云上的实际业务中得以使用,满足了高性能高存储量的需求。
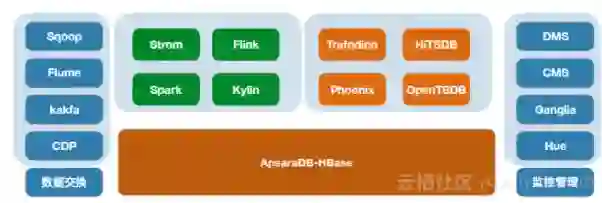
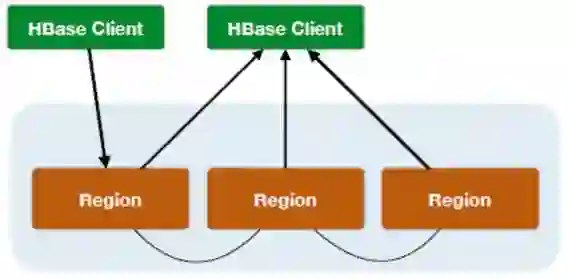
下图展示了HBase在业务中所处的位置,以及整体数据流的流向。
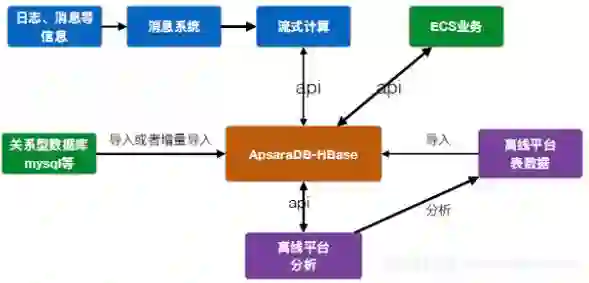
ApsaraDB for HBase平台解读
在构建过程中,HBase会面临的问题涉及:较为复杂的运维体系、安全体系、云环境、源代码有bug需要修复、数据可靠性无法保障、配置复杂、需要增加公网服务等功能、稳定性待提升等方面。ApsaraDB HBase平台能够针对性地完善这些因素,性能更佳,更加稳定可靠。
ApsaraDB HBase的基本架构图如下所示:
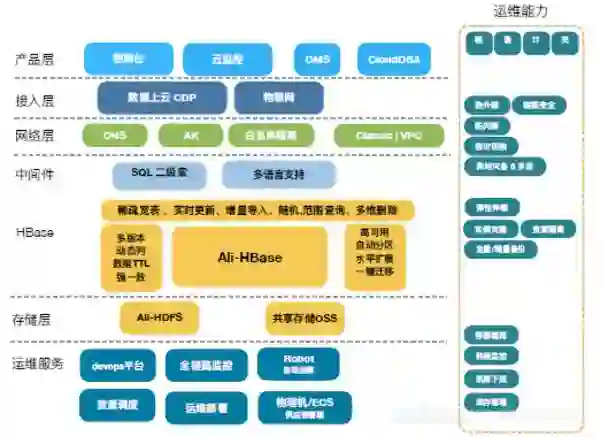
从架构层面来讲,不同层面会提供不同的服务。
产品层、接入层、网络层:提供上云方案、安全服务、公网访问、监控指标报警、方案支持等一站的DBaas服务;
中间件、HBase内核层:Apsaradb- HBase内核是基于社区 HBase1.1版本打造,目前在阿里集团内部有数千业务使用,万台机器的规模,在性能、稳定性、功能方案均有提升及改进,在历年双十一均有考验;
存储层:HBase后续会基于云端本地实例及共享存储,极大降低成本;
运维服务:实现运维自动化:15分钟内全自动部署集群,自动守护进程,可用性检测及报警,修改配置,扩容节点和磁盘,链路监控报警,指标可视化,自动升级内核等。
ApsaraDB HBase给用户承诺的保障有:数据可靠性;高性能;高可用,自动负截均衡,单节点故障时可秒级故障转移;生态完整,与Hadoop生态完美融合,支持其它组件复杂分析;易运维,全指标监控预警,在线扩容节点、磁盘及修改配置;强安全,支持网络白名单、VPC网络隔离、基于阿里云AK访问集群。
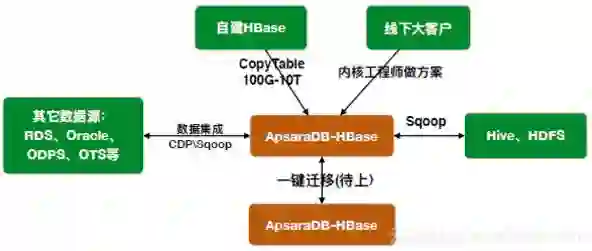
作为一款数据库类产品,ApsaraDB HBase与各个数据源间保持着非常通透的关系,方便数据导入导出。
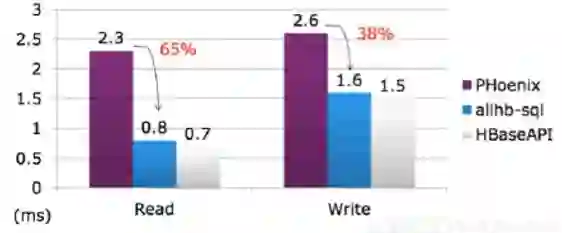
HBase API在性能上可以成倍地提升,如下图所示。

HBase SQL实现了全局二级索引:索引存储一致性同步、单列索引、索引异步构建,性能大幅度提升。
近期规划
关于HBase的规划,阿里已经对外开放过HBase链路优化、集群同步、强一致性等技术分享,后续将会在公网访问、服务端一键迁移、共享存储、SQL、Replica等方面继续完善。

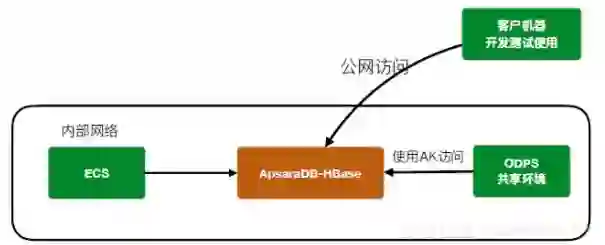
HBase公网访问&AK访问:实现在线共享环境,提供安全保障。
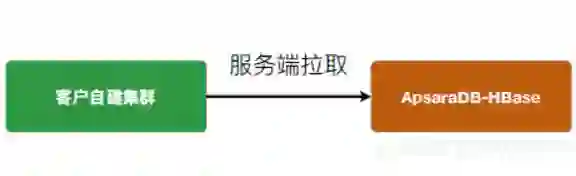
服务端一键迁移:这是团队目前正在研究的功能。
共享存储:下沉到存储层及降低存储成本。

SQL:定位非事务、schema、二级索引、轻分析。
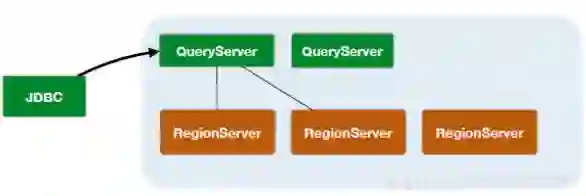
Replica:在一个Region写,再在多个Region读写访问。目前应用较少,致力于使HBase同时支持CP&AP。
HBase本身一直在发展之中,在大规模的结构化存储的场景中无疑是标准的产品,其支持的场景也在不断拓展。阿里云HBase团队也是致力于推广改进HBase及提供专业的服务。我们希望HBase发展越来越好。
《全球人工智能》开始招人啦!
一、1名中文编辑(深圳):熟悉国内AI技术媒体、企业,对AI有一定了解,有非常强烈的兴趣进入这个行业,学习能力强,负责中文类AI技术新闻采编(有经验)。待遇:8-12k
二、1名英文编译(深圳):英语水平能看懂英文的新闻,对AI有一定了解,有非常强力的兴趣进入这个行业,学习能力强,负责英文类AI技术新闻采编和兼职翻译管理(有经验)。待遇:8-12k
三、1名课程规划(深圳):计算机相关专业,对人工智能技术有浓厚兴趣,能对ai技术进行系统化梳理,对培训教育比较感兴趣,学习能力强。负责技术课程的梳理和规划(英语好懂技术)。待遇:8-12k
四、2名导师管理(深圳):沟通能力强,能善于负责人工智能技术专家的拓展、关系维护、培训沟通、课程时间协调等工作(英语好懂技术)。待遇:8-12k+提成
五、2名渠道商务(深圳):有一定渠道商务拓展或销售经验,对新生事物比较敏感,熟悉线上线下渠道拓展业务。待遇:6-10k+提成
简历发送:mike.yu@aisdk.com


一AI工程师下载200万GB色情内容,只为学习Python!
全球最火爆的人脸识别技术应用: FaceDance Challenge!