Facebook最新语言模型XLM-R:多项任务刷新SOTA,超越单语BERT

新智元报道
新智元报道
来源:Facebook AI
编辑:肖琴
【新智元导读】Facebook AI最新推出一个名为XLM-R的新模型,使用100种语言、2.5 TB文本数据进行训练,在多项跨语言理解基准测试中取得了SOTA的结果,并超越了单语言的BERT模型。代码已开源,来新智元 AI 朋友圈获取吧~
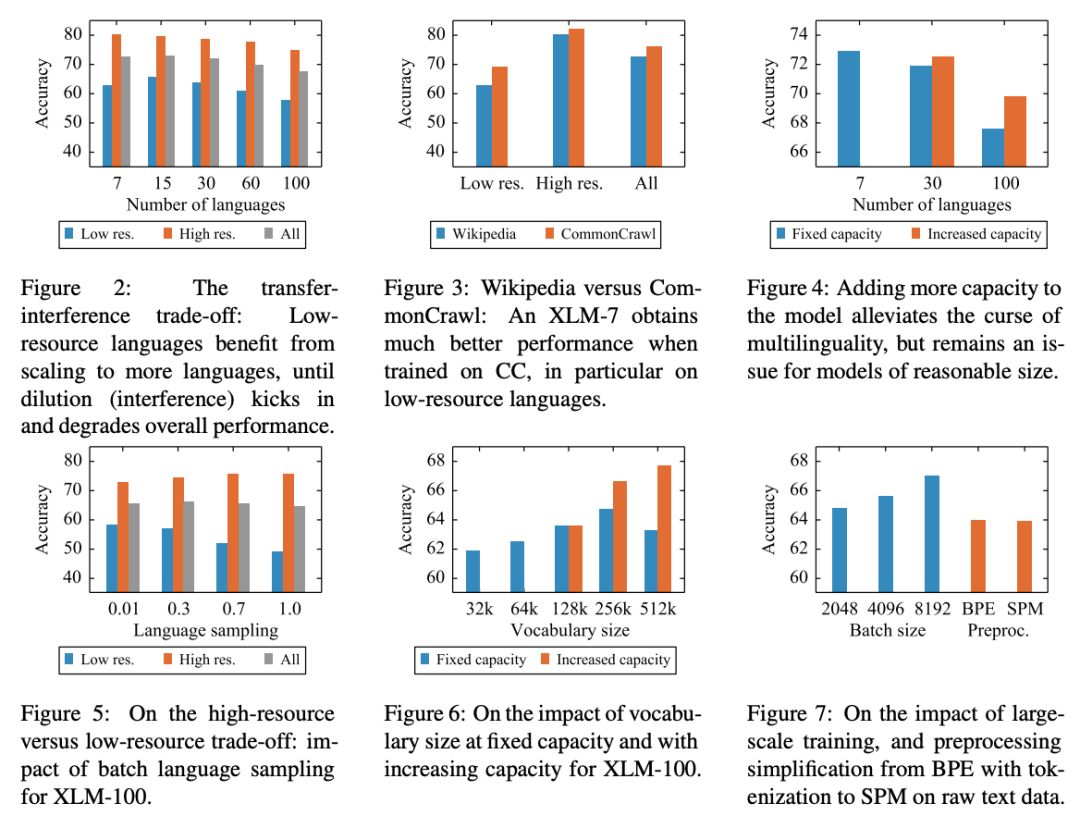
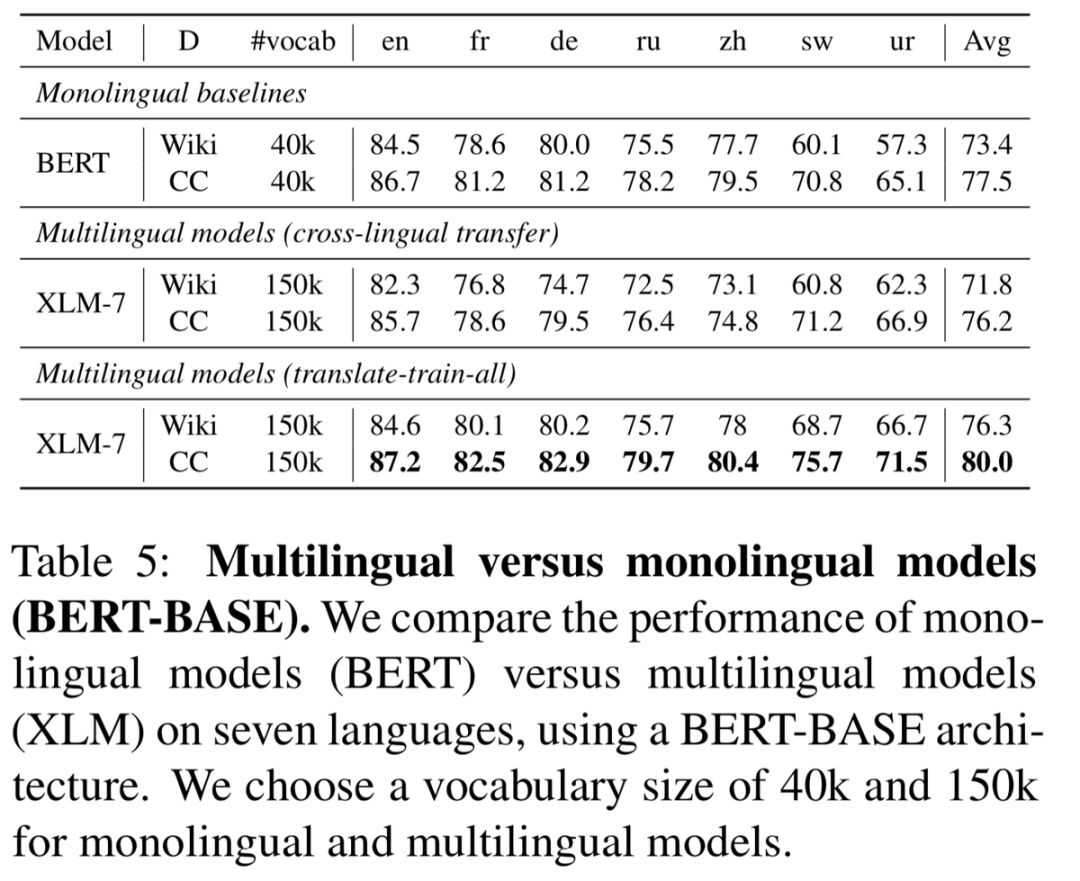
XLM-R身手不凡:多项任务刷新SOTA,超越单语BERT
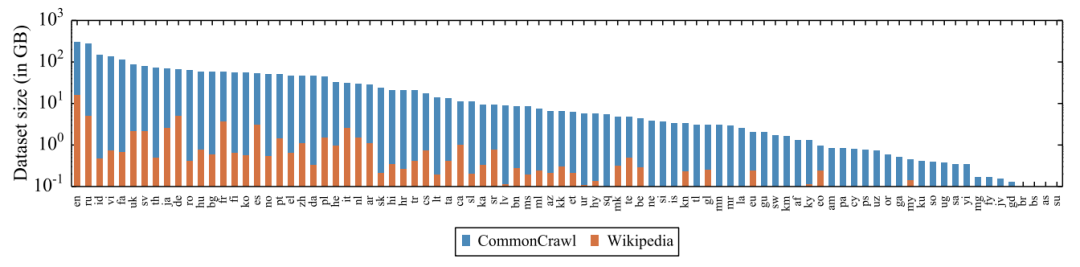
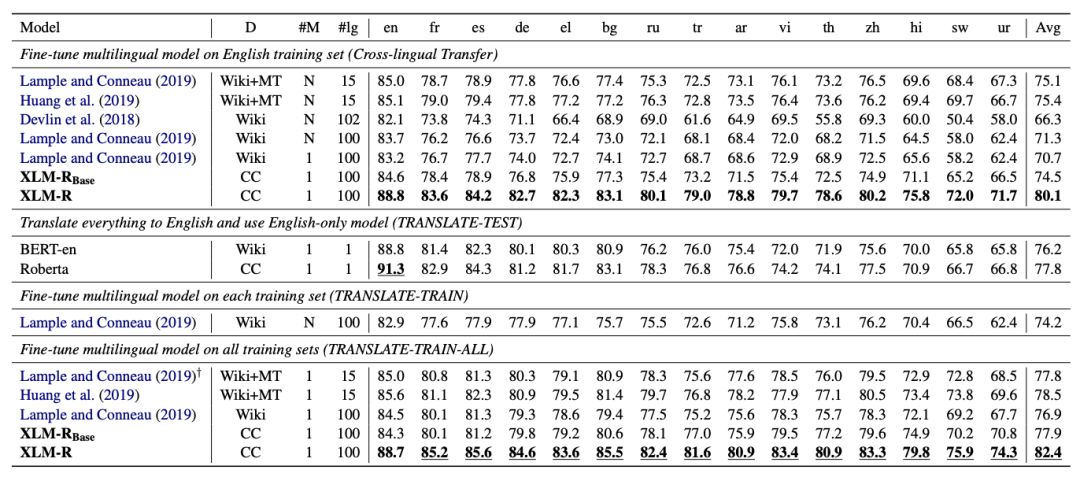
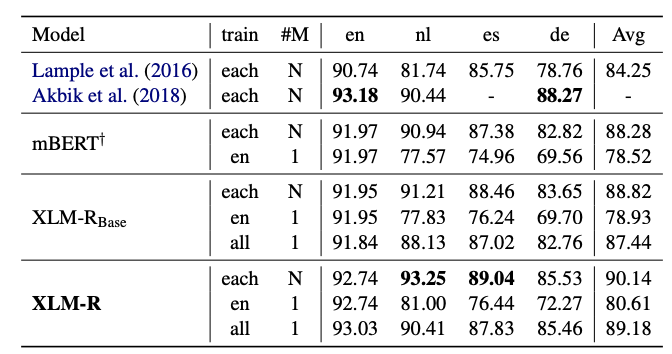
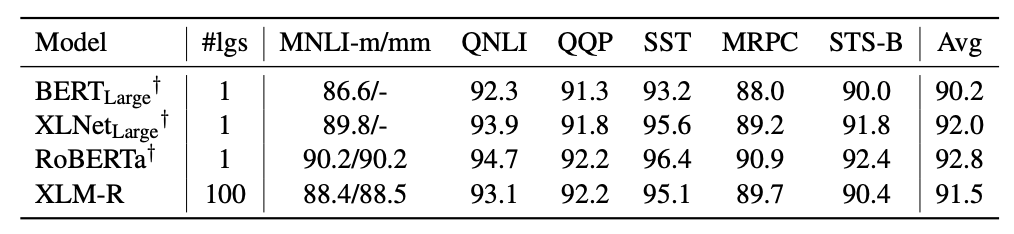
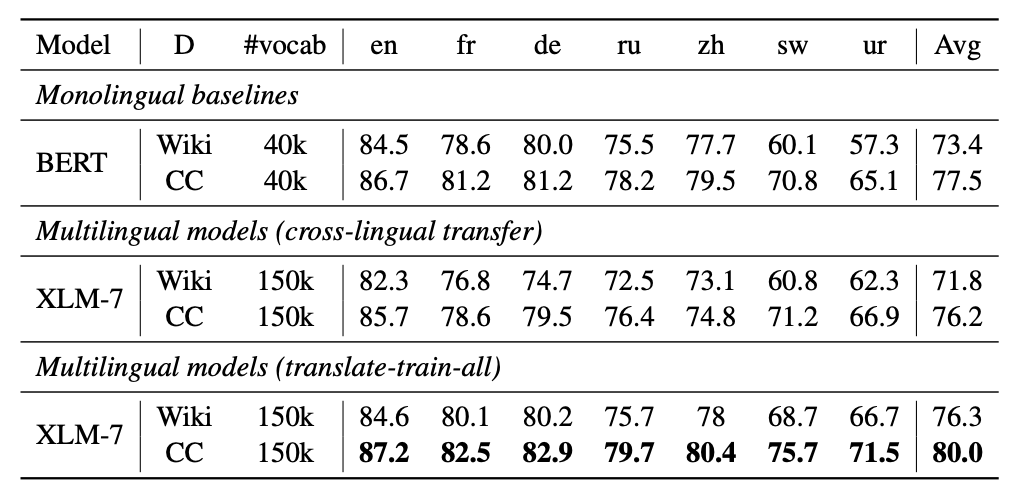
在XLM和RoBERTa中使用的跨语言方法的基础上,我们增加了新模型的语言数量和训练示例的数量,用超过2TB的已经过清理和过滤的CommonCrawl 数据以自我监督的方式训练跨语言表示。这包括为低资源语言生成新的未标记语料库,并将用于这些语言的训练数据量扩大两个数量级。
在fine-tuning期间,我们利用多语言模型的能力来使用多种语言的标记数据,以改进下游任务的性能。这使我们的模型能够在跨语言基准测试中获得state-of-the-art的结果,同时超过了单语言BERT模型在每种语言上的性能。
我们调整了模型的参数,以抵消以下不利因素:使用跨语言迁移来将模型扩展到更多的语言时限制了模型理解每种语言的能力。我们的参数更改包括在训练和词汇构建过程中对低资源语言进行上采样,生成更大的共享词汇表,以及将整体模型容量增加到5.5亿参数。


登录查看更多
相关内容
专知会员服务
27+阅读 · 2020年4月5日
Arxiv
15+阅读 · 2018年10月11日
Arxiv
3+阅读 · 2018年5月31日
相关VIP内容
专知会员服务
27+阅读 · 2020年4月5日
相关资讯