干货 | 增强学习对于机器人运动控制的六字真言
300 + 明星创业公司,3000 + 行业人士齐聚全球人工智能与机器人峰会 GAIR 2017,一 同见证 AI 浪潮之巅!峰会抢票火热进行中。
今天特放出 5 个直减 1350 元的无条件优惠码(见文末,优惠幅度逐天减小),感谢各位读者对雷锋网的支持,点击阅读原文即可使用。
AI科技评论按:本文来自英特尔中国研究院。
五月末的人机大战让世人大开眼界,顶级围棋手柯洁落下的眼泪、微博的叹息,都是对AlphaGo这颗强劲“大脑”的赞叹。然而,让人工智能走出娱乐和游戏,真正进入人类的实际生活,通过实现机器人的自主运动来为人类提供服务同样是我们长久以来的梦想。
但是,机器人的自主运动该如何实现?随着深度学习部分解决了机器人的视听识别问题,增强学习技术有望成为突破机器人自主运动难题的一把利剑。
增强学习实际上是“试错法”这一在生活中广泛使用的技巧的理论抽象,即为了达到理想目标而不断试验,并在实际尝试中修正方案,从而逐步提高成功率。
比如在围棋程序中,盘面情况称为“状态”,落子选择称为“行为”;根据状态选择行为的方法就称为“策略”,根据当前状态和行为对输赢的预测就称为“价值”,而当前一步的输赢结果称为“回报”。增强学习就是修正策略从而实现价值最大化的过程。
在2017年《麻省理工科技评论》全球十大突破性技术榜单中,增强学习技术高居榜首,并已在棋类运动和电脑游戏领域获得突破性进展,如AlphaGo使用增强学习技术击败世界围棋冠军柯洁,基于增强学习的电脑程序在一系列Atari游戏中超过人类水平等。
那么,针对机器人的运动控制问题,增强学习技术的运用存在哪些难点?我们又可以采取哪些有效的解决方法?今天,我们为大家奉上六字真言:高、大、少;虚、先、近。
三个难点
与棋类运动和电脑游戏不同,在机器人运动控制领域运用增强学习方法主要有以下三个难点:
“高”,即状态和行为维数高。比如让机器人为我们端杯水,需要增强学习算法提供如下的最优运动控制策略:凭借具有深度、鱼眼和普通图像拍摄功能的实感TM摄像头获得图像,分析出人和杯子的方向、距离、姿态以及人的表情,并通过听觉获得人发出命令的方位和急促程度,从而控制机器人(机械腿或底盘)走到人的面前;借助机器人手获得重量、温度、滑动信息,依据人手的方位控制机器人手臂和手指各关节的实时角度。这个过程所涉及的状态和行为的维数以百万计,而对每个状态行为进行价值(如人的满意度)计算也非常困难。

机器人模型
“大”,即状态信息误差大。棋类运动中的状态(盘面)信息完全准确,但机器人所面对的状态信息,大多存在明显误差。如在递水这个场景中,我们所获得的人和杯子的方向、距离、姿态以及人的表情、动作信息都存在误差。误差可能是由机械振动或机器人运动等因素造成,也可能是因为传感器精度不够高,存在噪声,亦或是由于算法不够精确。这些误差都增加了增强学习的难度。
“少”,即样本量少。不同于人脸等图像识别任务中动辄百万的训练样本,机器人增强学习可获得的样本数量少、成本高,主要原因是:机器人在运动过程中可能出现疲劳和损坏,还可能会对目标物或环境造成破坏;机器人的参数在运动中会发生改变;机器人运动需要一定的时间;很多机器人学习任务需要人的参与配合(如上述递水场景中需要有人接水)。这些都使得获得大量训练样本十分困难。
三种解决方法
面对上述困难,我们难道就无计可施了吗?当然不是,科学家们提出了一整套解决问题的思路,主要有如下三点:
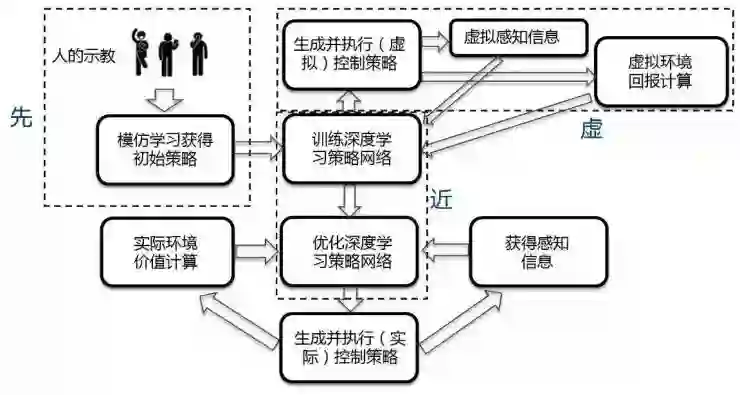
一个融合了“虚、先、近”三种策略的机器人运动控制增强学习框架
“虚”,即采用虚实结合的技术。我们可以通过程序虚拟出环境让机器人进行预训练,以克服实际采样过程中可能出现的种种难题。虚拟软件不但能模拟机器人的完整运动特性,如有几个关节、每个关节能如何运动等,还能模拟机器人和环境作用的物理模型,如重力、压力、摩擦力等。机器人可以在虚拟环境中先进行增强学习的训练,直到训练基本成功再在实际环境中进一步学习。虚实结合的增强学习主要面临两个挑战。一个是如何保证虚拟环境中的学习结果在实际中仍然有效。面对这一难题,我们可以对虚拟环境与实际环境中的差别进行随机性的建模,在虚拟环境中训练时引入一些噪声。另一个挑战是如何实时获得外部环境和目标的虚拟模型,最新的深度摄像头可以帮助我们解决这个问题。
“先”,即先验知识。引入先验知识可以大幅降低增强学习优化的难度。先验知识有很多种,但对于机器人而言,获得先验知识比较有效的途径是“学徒学习”,即让机器人模仿人的示教动作,再在应用中通过增强学习优化。由于机器人运动所面临的状态维数极高,通过手工输入知识非常困难,而人做示范则较为方便,还降低了先验知识引入的门槛,不太了解机器人技术的人也可以进行。示教主要有三类方法:一是由人拖动机器手做动作;二是使用专门的运动捕捉设备获得人的动作;三是直接使用深度摄像头获取人的动作。从长远看,第三种方法会成为以后的发展趋势。
“近”,即近似。由于机器人运动控制的状态维数高、样本少且存在误差,所以将维数高的状态近似为不丢失主要信息又能增加可训练性的函数就成为一项重要的选择。使用近似方法提高增强学习算法性能的一大热点就是将深度学习技术与增强学习相结合所形成的深度增强学习技术,此技术直接将机器人的状态(如传感器和关节状态输入)通过高层的卷积神经网络映射为机器人的动作输出,大大提高了机器人基于增强学习进行运动控制的性能。该技术在近两年来取得了突破性的进展。
上述解决方法为增强学习在机器人动作控制领域的应用打开了大门,成为机器人研究的重要方向之一,但目前还存在许多实际难题亟待解决。科研人员正在对深度增强学习、学徒学习(模仿学习)和虚实结合学习方面进行一系列探索。
CCF-GAIR 2017,100 + 优质展位,1000 + 传统供应链玩家,全球顶级技术方案商悉数亮相,帮企业实现 AI 技术方案快速对接,掘金万亿 AI 产业!高端资源、优质展位、名额有限,再不申请就没了!电话或微信联系方式:15013779392
6月6日门票直减 1350 优惠码
优惠幅度逐天减小
有效期两天,手慢无
59368ef1183bf
59368ef118135
59368ef117f3e
59368ef117d62
59368ef117b0b
点击阅读原文使用

AI科技评论招业界记者啦!
在这里,你可以密切关注海外会议的大牛演讲;可以采访国内巨头实验室的技术专家;对人工智能的动态了如指掌;更能深入剖析AI前沿的技术与未来!
如果你:
*对人工智能有一定的兴趣或了解
* 求知欲强,具备强大的学习能力
* 有AI业界报道或者媒体经验优先
简历投递:
lizongren@leiphone.com




