深度 | BAIR论文:通过“元学习”和“一次性学习”算法,让机器人快速掌握新技能
AI科技评论按:近日伯克利大学人工智能实验室(BAIR)Sergey Levine团队在Arxiv上发布了一篇名为《One-Shot Visual Imitation Learning via Meta-Learning》的论文,该论文将当前AI研究的两个瓶颈即元学习(Meta-Learning)和一次性学习(One-shot learning)相结合,并被CORL(Conference on Robot Learning, 2017)接收,CORL 2017将于今年11月在美国加州山景城举行。
我们都知道,深度学习是在大数据的背景下火起来的,传统的基于梯度的深度神经网络需要大量的数据学习,而绝大多数的深度学习内容否基于大数据量下的广泛迭代训练,当遇到新信息时往往会出现模型失效的情况从而需要重新进行学习。在机器人领域,深度神经网络可以是机器人展示出复杂的技能,但在实际应用中,一旦环境发生变化,从头学习技能并不可行。因此,如何让机器“一次性学习”,即在“看”了一次演示后无需事先了解新的环境场景,能在不同环境中重复工作尤为重要。
研究发现,具有增强记忆能力的架构如神经图灵机(NTMs)可以快速编码和见多新信息,从而起到消除常规模型的缺点。在本论文中,作者介绍了一种元-模拟学习(Meta-Imitation Learning,MIL)算法,使机器人可以更有效学习如何自我学习,从而在一次演示后即可学得新的技能。与之前的单次学习模拟方法不同的是,这一方法可以扩展到原始像素输入,并且需要用于学习新技能的训练数据明显减少。从在模拟平台和真实的机器人平台上的试验也表明了这一点。

目标:赋予机器人在只“看过”一次演示的情况下,学习与新物品互动的能力。
做法:
收集大量任务的Demo;
使用元-模拟学习进行训练;
在未知的新任务中进行测试。
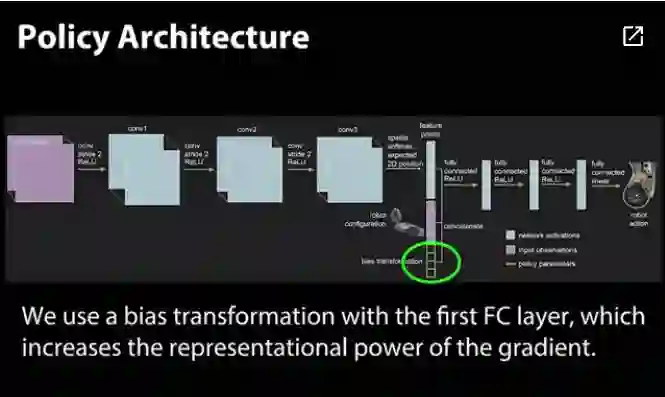
创新内容:在第一个全连接层通过偏差转换增加梯度表现。
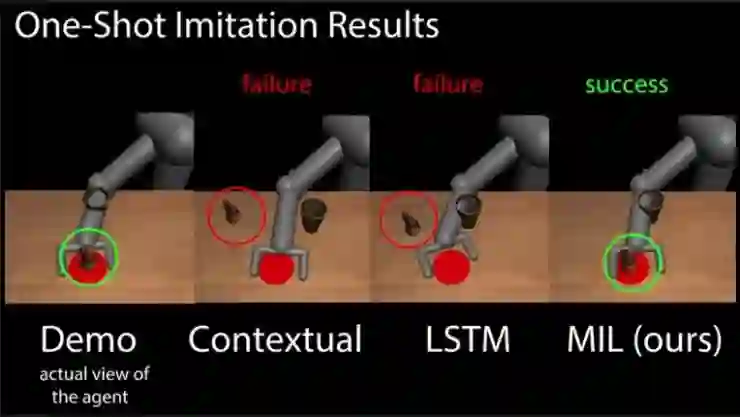
模拟测试环节,这一环节使用算法提供的虚拟3D物品进行模拟,MIL比Contexual和LSTM更好地完成了任务。

在实际场景测试环节,该团队设计了一个抓取物品并将其放到指定容器中的任务。从上图我们可以看到,在这一环节用于训练的物品与实际测试的物品无论在形状、大小、纹理上都有着差别,MIL算法同样较好地完成了任务。

「AI科技评论」发现,除了BAIR,Google Deepmind(参见「AI科技评论」之前文章《只训练一次数据就能识别出物体,谷歌全新 AI 算法“单次学习”》)、OpenAI也有在进行关于“一次性学习”的研究。“一次性学习”通常被认为是计算机视觉中的对象分类问题,旨在从一个或仅少数几个训练图像中学习关于对象类别的信息,并且已经成功应用到包括计算机视觉和药物研发在内的具有高维数据的领域。今年5月,OpenAI也发布了类似的在虚拟场景下通过一次性学习,完成堆叠方块等任务的论文。
在《人类的由来》中,达尔文这样写道:“人和其他高等动物在精神上的差异虽然很大,但这种差别肯定只是程度上、而非种类上的差别。”而这些在一次性学习和元学习上的研究也证明,当前的人工智能与未来世界的超级人工智能之间的差异,或许也只是程度上的差异,而非种类上的差异。在深度学习发展的过程中,类似的优化看起来只是一小步,但加速化发展的趋势已经很明显:当你在阅读传统期刊上的论文时,在Arxiv上或许已经出现了新的替代版本。或许在不久之后,创造出更聪明、具有适应力的实用机器人并不是难事。
论文地址:https://arxiv.org/pdf/1709.04905.pdf
视频演示及更多详细说明:https://sites.google.com/view/one-shot-imitation
————— 给爱学习的你的福利 —————
3个月,从无人问津到年薪30万的秘密究竟是什么?答案在这里——崔立明授课【推荐系统算法工程师-从入门到就业】3个月算法水平得到快速提升,让你的职业生涯更有竞争力!长按识别下方二维码(或阅读原文戳开链接)抵达课程详细介绍~

————————————————————






