和 Geoffery Hinton 面对面聊聊

AI 科技评论按:在今年的谷歌 I/O 2019 大会上有个环节,邀请了「深度学习教父」、也是 2018 年图灵奖获奖者之一的 Geoffery Hinton 聊一聊学术、非学术的各类话题。整个过程很轻松,就是聊聊各种话题,不过 Hinton 老爷子一如既往地学术风气十足。雷锋网 AI 科技评论根据视频回放把访谈内容听译整理如下。有小部分删节。
主持人:大家好,我是 Nicholas Thompson,Wired 记者。今天我们要和 Geoffery Hinton 面对面聊一聊。说起 Hinton 他身上有两件事让我很敬佩,第一件当然是他很能坚持,即便所有别的人都说他的想法很糟糕,他也坚持相信自己,坚持一直做下去。别的「有很糟糕的想法」的人很受到他的鼓励,包括我自己。第二件就是,我做了大半辈子管理者,可以说收集了各种各样的职位头衔,而当我看到 Hinton 的简介的时候,他的头衔简直不能更加平庸 —— 就是谷歌工程 Fellow(Google Engineering Fellow)而已。让我们邀请他上台。
Hinton:谢谢,很高兴来到这里。

为什么要坚持神经网络
主持人:那我们开始吧。我记得大概是 20 年前,你开始写一些最早的产生影响力的论文,别人看了以后觉得「唔,挺聪明的想法,但是我们没办法设计这样的电脑」。跟大家谈谈你为什么能一直坚持、为什么那么相信自己找到了很重要的东西?
Hinton:首先纠正你一下那是 40 年前。在我看来,大脑没办法以别的方式运转,它只能是学习连接的强弱。那么,如果你想要制造一个能做智能的事情的机器,你面前有两个选择,给它编程,或者让它学习。显然我们人类的智慧不是被别人编写出来的,所以就只能是「学习」。只有这一种可能。
主持人:那你能再给大家解释一下「神经网络」这个概念吗?在场的多数人应该都是知道的,不过我们还是想听听你最初的想法,以及它是如何发展的。

Hinton:首先你有一些非常简单的处理单元,可以看做是神经元的简单形式。它们能接受传入的信号,每个信号都有权重,这些权重可以变化,这就是学习的过程。然后神经元做的事情就是先把传入的信号值乘上权重,再把它们全都加起来得到一个和,最后再决定是否要把这个和传送出去;比如这个值足够大,就传送出去,不够大或者是负数,就不传送。就这么简单。你只需要把成千上万个这样的单元互相连接起来,里面有成千上万的成千上万倍的权重,然后学习到这些权重,那你就可以做到任何事了。难点只在于如何学习权重。
主持人:你是在什么时候开始觉得,这种做法和人类大脑的运转方式差不多的?
Hinton:神经网络一开始就是仿照人类大脑的样子设计的。
主持人:比如在你人生中的某个时候你开始意识到了人类大脑是怎么工作的,可能是在 12 岁的时候,也可能是在 25 岁的时候,那么你是在什么时候开始、以及如何决定了你要仿照人类大脑的样子设计神经网络的?
Hinton:差不多一知道人类大脑是这么工作的就决定了吧。做这个研究的整个思路就是模仿人类的大脑的连接,然后试着学习这些连接权重。我其实不是这个思路的创始人,图灵就有过同样的思路。虽然图灵为标准计算机科学的发展做出了很大贡献,但是他就认为人类大脑是一个没有什么明确结构、连接权重也都是随机值的设备,然后只需要用强化学习的方式改变这些权重,它就可以学到任何东西。他觉得「智慧」的最好的模式就是这样的。还有很多别的人也都有差不多的想法。
主持人:上世纪 80 年代的时候你在这方面的研究让你变得小有名气,但后来,从什么时候开始其它的研究者就开始放弃这个方向了呢?只有你一个人坚持下来了。
Hinton:(停顿了一下)总有那么一小拨人是坚持相信、坚持到了今天的,尤其是心理学领域里。不过计算机科学这边能坚持的就少一点,因为上世纪 90 年代的时候,领域内的数据集很小、计算机也没有那么快,这时候还有其它类型的方法出现,比如支持向量机(SVM),它们在那样的条件下效果更好,受到噪声的影响也没那么严重。这就开始让人感觉到沮丧了,虽然我们在 80 年代开发了反向传播,我们也相信它能解决任何问题,但那时候我们搞不清它「为什么没能解决任何问题」。后来我们知道了让神经网络发挥实力需要数据和计算力都有很大的规模,但当时没人知道。
主持人:你们当时以为它效果不好的原因是什么?
Hinton:我们以为是算法不好、目标函数不好等等各种原因。我自己很长时间内都有一个想法,觉得是因为我们在做监督学习,需要标注很多数据;那么我们应该做的是无监督学习,从没有标签的数据中学习。但最后我们发现主要原因还是在规模上。
主持人:听起来很有趣,其实只是数据量不足,但是你们当时以为数据量够了,但是标注得不好 —— 你们找错了问题了对吗?

Hinton:我当时觉得「用有标注的数据」就是不对的,人类的大多数学习过程都没有用到任何标签,就只是在建模数据中的结构。其实我现在也还相信这个,我觉得随着计算机变得越来越快,给定一个足够大的数据集以后就应该先做无监督学习;无监督学习做完以后,就可以用更少的标注数据学习。
主持人:到了九十年代,你还继续在学术界做研究,还在发表论文,但是没能继续解决越来越多的问题。你当时有没有想过,觉得我受够了、我要做点别的去?还是就是很坚定地要一直做下去?
Hinton:就是要坚定做下去,这是一定能行的。你看,人类大脑就是通过改变这些连接来学习的,我们去研究、去模仿就好了。学习这些连接的强弱可能会有很多种不同的方式,大脑用了某一种,但是其他的方法也有可能是可行的。不过你总是需要找到一种学习连接权重的方法。这一点我从来没有怀疑过。
看到希望
主持人:大概在什么时候看起来好像行得通了?
Hinton:八十年代的时候其实有件事让大家很头疼,就是如果你设计了一个有很多隐层(中间层)的神经网络,你没办法训练它们。有一些很简单的任务里的神经网络是可以训练的,比如识别手写字体,但是对于大多数比较深的神经网络,我们都不知道要怎么训练。到了大约 2005 年,我想到了一些对深度神经网络做无监督训练的点子。具体来说是,从你的输入,比如说是一些像素,学习一些特征检测器,学习过之后它们就可以很好地解释为什么这些像素是这样的。然后你把这些特征检测器作为数据,把它们作为输入再学习另一批特征检测器,就可以解释那些特征检测器之间为什么会有关联性。那么就这样一层又一层地学。很有趣的是,你可以通过数学证明,当你学的层数越来越多的时候,你不一定得到了更好的数据模型,但是你会知道你当前的模型的比较结果。每当你增加一个新的层,你就会得到更好比较结果。
主持人:能多解释一下吗?
Hinton:当你得到一个模型以后,你会问「这个模型和数据的相符程度如何?」你可以给模型输入一些数据,然后问它「你认为这些数据和你的想法相符吗?还是说你感到很意外?」你可以对这个程度做出一些测量。我们想要的效果是,得到一个好的模型,它看到这些数据以后会说「嗯,嗯,都是我很熟悉的」。准确地计算模型对数据有多熟悉一般来说是很难的,但是你可以计算一个模型和模型之间的相对高低,就是比较结果。那么我们就证明了,当你增加的额外的特征检测器层越多,新模型对数据的熟悉程度就会越高。(雷锋网 AI 科技评论注:这部分的具体技术细节可以参见 Hinton 在 NIPS 2007 上介绍深度信念网络的教学讲座 http://www.cs.toronto.edu/~hinton/nipstutorial/nipstut3.pdf )
主持人:在 2005 年有这样的建模想法挺好的,那你的模型开始有好的输出大概是在什么时候?你又是在什么数据上做的实验?
Hinton:就是手写数字数据集,非常简单。差不多也就是那个时候,GPU(图形计算单元)开始快速发展,做神经网络的人大概从 2007 年开始使用 GPU。我当时有一个很优秀的学生,他借助 GPU 在航拍图像里找到公路,他当时写的代码有一些后来被其它学生用在语音的音位检测里,也是借助 GPU。他们当时做的事情是预训练,做完预训练之后把标签加上去,然后做反向传播。这种做法不仅确实做出来了很深的、经过了预训练的神经网络,再做了反向传播之后还能有不错的输出,它在当时的语音识别测试中打败了不少别的模型,数据集是 TIMIT,很小,我们的模型比当时学术界的最好的成果好一点点,也比 IBM 的好一些。这是一开始,提升不算多。
然后其他人很快就意识到,这种方法再继续改进一点就能取得很好的成果,毕竟它当时打败的那些标准的模型都是花了 30 年时间才做到这种效果的。我的学生毕业以后去了微软、IBM、谷歌,然后谷歌最快把这个技术发展成了一个生产级别的语音识别系统。2009 年有了最初的成果,2012 年已经来到了安卓系统上,安卓系统也就在语音识别方面遥遥领先。
主持人:那时候你有这个想法都 30 年了,终于做出大众认可的成果,而且也比其他的研究人员效果更好,你的感觉如何?
Hinton:感觉真的很开心,终于发展到了解决实际问题的阶段了。
主持人:那么,当你发现神经网络能很好地解决语音识别问题以后,你是什么时候开始尝试用它解决其他的问题的?
Hinton:嗯这之后我们就开始在各种问题上尝试这个方法。最早用神经网络做语音识别的是 George Dahl,他开始用神经网络预测一个分子是否会连接到某些东西上面然后起到治疗的作用。当时有一个做这个的竞赛,他就直接把用于语音识别的标准方法用来预测药物分子的活性,然后就这么赢了竞赛。这是一个很积极的信号,神经网络的方法似乎有很高的通用性。这时候我有一个学生说,「Geoff,我感觉用这个方法去做图像识别也会效果很好,李飞飞也已经创建了一个合适的数据集,还有一个公开的竞赛,我们一定要去试试」。我们就参加了,得到的结果比标准计算机视觉方法好很多。(AlexNet 在 2012 年的 ImageNet 大规模视觉识别挑战赛 ILSVRC 中以远好于第二名的成绩取得第一,下图中 SuperVision 团队)
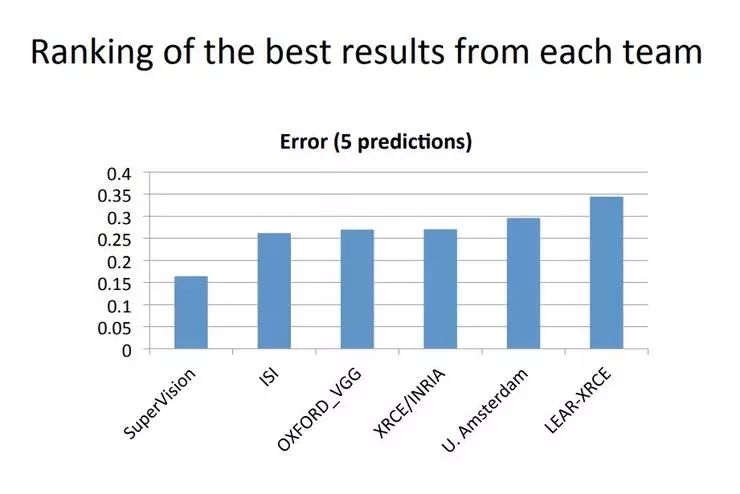
主持人:说了不少的成功案例,对化学分子建模啊、语音啊图像啊什么的,有没有什么失败的案例?
Hinton:失败都只是暂时的,你能明白吗?
主持人:那么,有没有哪些领域特别快就成功,有的领域里就慢一些?我的感觉好像是视觉信号处理、语音信号处理这些人类的感知器官的核心任务是最先攻克的,是这样吗?
Hinton:不完全对,感知的确实攻克了,但还有运动控制之类的事情没有那么大的进步。人类的运动控制能力非常高,也非常轻松,很显然我们的大脑就是为运动控制设计的。一直发展到今天,神经网络在运动控制方面的表现才开始追赶上此前就有的技术。神经网络最终会赶超的,但现在才刚刚出现小的胜利。我觉得,推理、抽象推导这些人类也最后才学会做的事情,也将会是神经网络最难学会的事情。
主持人:你们总说神经网络最后能搞定所有的事情?(笑)
Hinton:这个嘛,我们人类就是神经网络啊。所有我们能做的,神经网络就能做。
主持人:没错,不过人类大脑也不见得就一定是世界上最高效的计算机器。有没有哪种机器比人类大脑的效率更高的?
Hinton:哲学上来讲,我并不反对「存在一种完全不同的方式来达成这一切」这样的观点。比如有可能你从逻辑开始,你就会尝试研究自动逻辑,会研究出什么特别厉害的自动定理证明机器;如果你从推理开始,然后你要通过推理做视觉感知,可能这个方法也可行。不过最后这些方法没做出好的效果。我从哲学角度上并不反对其它的方式也能达成这些。只是目前来看,我们知道大脑、也就是神经网络,是确实可以做出这些的。
我们理解神经网络吗?理解我们的大脑吗?
主持人:下面我想问另一个角度的问题,那就是,目前我们并不完全清楚神经网络是如何工作的,对吗?
Hinton:对,我们不太清楚神经网络是如何工作的。

主持人:我们很难从结果推理出神经网络的工作方式,这是我们对神经网络的不理解的关键之处对吧?详细谈谈吧。以及显然我还有紧接着的下一个问题:如果我们不知道他们是如何工作的,那么我们把它们造出来以后是如何得到好的效果的?
Hinton:如果你观察一下当前的计算机视觉系统的话,它们大多数都只有前向传播,没有反馈连接。当前的计算机视觉系统还有一个特点,就是他们对于对抗性错误非常敏感,比如你有一种张熊猫的图像,轻微修改了其中几个像素以后,在我们看起来仍然是熊猫,但计算机视觉系统就会一下子认为图中是火鸡。显然,这个修改像素的方式是需要经过精密的设计的,是对计算机视觉系统的误导或者欺骗。但重点是,在人类看来它仍然是熊猫,不受影响。
所以一开始我们以为基于神经网络的计算机视觉系统工作得挺不错的,但是后来当我们发展这样的对抗性修改(攻击)可以起到这样的作用以后,大家都会开始有点担心。我觉得这个问题有一部分原因是因为网络并没能从高级别的表征进行重建。现在有研究者开始尝试做判别式学习,就是学习很多层的特征检测器,然后最终目标是改变不同特征检测器的权重,更更好地得到正确的结果。最近我们团队在多伦多也有一些发现,Nick Frost 发现,如果你引入了重建过程,它能让网络面对对抗性攻击的时候更稳定。所以我觉得人类视觉系统中,学习的过程就带有重建。而且我们除了视觉之外,很多的学习过程都是带有重建的,所以我们面对对抗性攻击的时候要稳定得多。
主持人:就是说,你觉得神经网络中从后往前的连接可以帮你测试数据的重建的过程?
Hinton:对,我觉得这非常重要。
主持人:那么脑科学家也持有同样的观点吗?
Hinton:脑科学家们全都同意这个观点,就是如果感知信号通路要经过大脑皮层的两个不同区域,那一定会有反向连接。他们只是还没有在这个连接的作用上达成一致。它的作用有可能是注意力、有可能是为了学习、也有可能是为了重建,甚至有可能三者都是。

主持人:所以我们还不完全理解反向连接的作用。那现在你就希望在网络中构建起到重建作用的反向连接,这么做合理吗?虽然你说要仿照大脑,但是你不确定大脑到底是不是这样的。
Hinton:我完全没有这方面的担心。毕竟我做的不是计算神经科学,也不是要为人类大脑的运转方式提出一个多么好的模型。我所做的仅仅是观察大脑,然后说「既然它能很好地发挥作用,那我们想让别的东西也发挥好的作用的时候,就可以从这里寻找一些灵感」。所以我们从神经科学、脑科学中获得灵感,但并不是为脑神经建模。我们的整个神经网络模型、我们的模型中用的神经元,就是来自于人脑中的神经的启发:神经元有很多的连接,而且这些连接可以改变权重。
主持人:听起来很有趣。所以如果我也做计算机科学,我也研究神经网络,然后我想要比 Hinton 做得更好的话,有一种选择是根据脑科学里的其它一些模型构建从后向前的连接,这次我可以选择让它发挥学习的作用。
Hinton:如果这样能得到更好的模型,那你真的有可能会成功的。
主持人:下一个话题,既然我们说神经网络可以解决各种问题,那有没有可能让神经网络捕捉重现人类的大脑,比如感情呀……
Hinton:(直接打断)不可能的。
主持人:那能用神经网络重建爱情、重建意识吗?
Hinton:这个可以,只要你弄明白了这些东西的含义到底是什么。毕竟我们人类也是神经网络。意识是我现在特别感兴趣的一件事,不过很多人说到这个词的时候都不太清楚自己到底在说什么。这东西有很多不同的定义,在我眼中它应当是一个科学词汇。100 年以前如果你问别人「生命」是什么,他们可能会说「活着的东西就有一种积极的生命力,当他们死去的时候,这种生命力就跟着一起走了。所以活着和死了的区别就是有没有那种生命力」。现在我们已经不谈生命力这种东西了,我们认为这是伪科学概念。甚至当你学习了生物化学和分子生物学之后,你就会开始痛斥生命力的说法,因为你已经明白生命具体是怎么回事了。我觉得我们对于「意识」的理解也会经过同样的过程。以前提出这个词是为了解释我们觉得有重要含义的精神现象。但一旦我们真正明白了意识是怎么一回事,这个「重要含义」的内容就不再重要了,我们能够清楚地解释做哪些事会让别人觉得一个人「有意识」,而且这又是为什么,也能够解释这个词的所有不同含义。
主持人:那么,没有什么感情是不能被创造的,没有什么思维是不能被创造的,只要我们完全理解了大脑是如何工作的,理论上就没有什么人类大脑能做的事情是不能被工作良好的神经网络重现的?
Hinton:你知道吗,你刚才说的这几句,让我想起 John Lennon 的一首歌,词句很像。
主持人:你对这些有 100% 的信心吗?
Hinton:不,不是 100%。我是一个贝叶斯主义者,我有 99.9% 是有信心的。
主持人:好吧,那另外那 0.1% 呢?
Hinton:就是有可能我们整个世界都是一个很大的模拟器,这一切都不是真的。
主持人:也不是没可能。那么,通过你在计算机方面的研究,我们有没有什么关于大脑的新发现?
Hinton:我觉得,在过去的十年中我们学到的是,如果你有一个系统有数以亿计的参数和一个目标函数,比如做好完形填空,它能达到的表现要比直接看上去的好得多。

做传统 AI 的人大多数会觉得,或者一个普通人也会觉得,对于一个有几十亿参数的系统,要从所有参数都是随机值的初始状态开始,计算目标函数的梯度,然后挨个更改这几十亿参数,让目标函数的值向着更好的方向去那么一点点,而且要做一轮一轮又一轮,这件事工作量太大了,没什么希望完成,很有可能在半路上就卡死了。但实际上这是一种很好的算法,各方面的规模越大,它的效果就越好。这完全是从我们的经验中总结出来的。现在既然我们已经发展了这样的规律,那么认为人类大脑也是在计算某些目标函数的梯度、然后依据梯度更新神经电信号传播时候的强弱,就显得容易接受多了。我们只需要弄明白这个过程是如何分解成一步步的,以及这个目标函数是什么。
主持人:但我们对大脑的理解还没有到那一步?我们还不理解这个改变权重的过程?
Hinton:这是一种理论。挺久以前人们认为是有这个可能的,不过也总会有一些传统的计算机科学家坚持说「听起来很美,但是你说你有几十亿个随机初始值的参数,然后全部通过梯度下降去学习,这是办不到的,你必须在里面固定一些知识进去。」现在我们能证明他们的观点是错误的,你只需要从随机的参数开始,然后学到一切。
主持人:我们再拓展一点。假设我们根据我们认为的大脑工作方式设计了模型,然后对它们做大规模测试,我们就很有可能了解到越来越多的关于大脑事实上如何运转的知识。会不会有一天到了某个地步,我们可以动手改造自己的大脑,让它们成为更高效、最高效的计算机器?
Hinton:如果我们真的能弄明白的话,我们就可以把教育之类的事情做得更好。我相信这是会发生的。如果你能弄明白自己的大脑中在发生什么,但是却不能够调节它、让它更好地适应你所在的环境的话,这反倒是一件奇怪的事情。
机器学习也「做梦」
主持人:我们能更好地理解梦境吗?
Hinton:我觉得能,我自己也对梦境很感兴趣,以至于我知道至少四种关于梦境的理论。
主持人:给大家讲讲呗。
Hinton:第一种有个挺长的故事。很久以前有个叫做 Hopfield 网络的东西,它可以把记忆学习为局部吸引子。Hopfield 这个人发现,如果你试着往里面塞太多的记忆的话,它们就会混淆。这会让两个局部的吸引力子在中间某个位置合二为一。
有 Francis Crick 和 Graeme Mitchison 两个人,他们说可以做忘记(unlearn)来避开虚假的局部极小值。那么我们就关闭网络的输入,先把神经网络设在一个随机状态,然后等到它停止下来以后,我们会觉得得到的结果不好,然后调整一下网络连接让它不要停在那个状态。这样做过几次之后,它就可以存储更多的回忆。
然后就到我和 Terry Sejnowski,我们觉得,不仅仅有存储回忆的神经元,还有很多起其它作用的神经元,我们能不能设计一个算法,让其它的神经元也帮助恢复回忆。后来我们就这样开发出了机器学习里的玻尔兹曼机,它有一个非常有趣的性质:给它展示数据,它就会在其它的单元附近持续转悠,直到得到一个满意的状态;然后一旦得到了,它就会根据两个单元是否都激活来增加所有连接的权重。这里存在一个阶段,你需要把它和输入之间切割开。你让它转悠转悠来到一个它自己觉得舒服的状态,这时候你就会让它找到所有成对活跃的神经元然后减弱它们之间的连接。
在这儿我跟你解释的算法好像是一个有趣的过程,但实际上算法是数学研究的结果,我们考虑的是「要如何改变这些连接的方式,才能让带有隐层的神经网络觉得数据很熟悉」。而且它还需要有另外一个阶段,我们把它叫做负性状态,就是让它在没有输入的状态下运行,然后对于它所处的任何状态都会忘记。
我们人类每天都会睡很多个小时。如果你随机地醒来,你就能说出你刚才在做什么梦,因为梦的记忆在存储在短期记忆里的。如果你一直睡够了才醒来,你就只能记得最后一个梦,更早的梦就记不起来了。这其实是一件好事,免得把梦和现实弄混了。那么为什么我们不能记得我们的梦呢?Crick 的观点是,做梦的意义就在于把很多事情忘掉。就像是学习的反向操作。
而 Terry Sejnowski 和我展示了,其实这是一个玻尔兹曼机的最大似然学习过程。这也是做梦的一种理论。
主持人:你有没有让哪个深度学习算法也像这样做个梦?学习某个图像数据集,然后忘掉,再学习,等等。
Hinton:有的。我们试过机器学习算法。我们最早发现的能够学会处理隐层神经元的算法里就包括了玻尔兹曼机,不过效率非常低。后来我发现了一种对它们做逼近的方法,要高效多了。这些其实都是让深度学习重获生机的契机,也就是借助这些方法我能够每次学一层特征检测器。这也就是受限玻尔兹曼机的一种高效形式。它也可以做遗忘。不过它不需要睡眠,它只需要在看过每个数据点之后冥想一阵子。
主持人:第二种理论呢?
Hinton:第二种理论叫做清醒和睡眠算法(the Wake Sleep Algorithm),而且你会想要学习一个生成性的模型。这里的思路是,你有一个可以生成数据的模型,它有很多层特征检测器,它可以从高层开始逐步向下激活,一直激活到像素的那一层,然后你就得到了一张图像。你也可以反过来做,就成了识别一张图像。
这样你的算法就会有两个阶段,在醒着的阶段,数据进来,模型尝试识别数据;但这时候模型学习的目标不是加强连接用于识别,而是加强连接用于生成。随着数据进来,隐层的神经元被激活,然后让神经元学习如何更好地重建数据。每一层都学习如何重建。但问题是,这样要如何学习前向连接呢?思路就是,如果你已经知道了前向连接,你就可以学习反向连接,因为你可以学习重建。

现在我们还发现它可以使用反向连接,你可以学习反向连接,因为你可以直接从最上层开始激活然后生成数据。而且因为你在生成数据,你就知道隐层神经元的激活状态,你也就可以学习到前向连接来恢复这些状态。这就是睡眠阶段了。当你关掉输入的时候,你只是生成数据,然后你尝试重建那些生成了数据的隐层神经元的状态。另外,如果你知道了自顶向下的链接的话,你就可以学习从下向上的连接;反过来也一样。所以如果你从随机连接开始做,把两件事交替进行的话,也是可行的。当然了,为了让它有好的效果,你需要对它做各种变化,但是确实是可行的。
主持人:emmm,我们还有 8 分钟时间,你打算继续谈谈其它两种理论吗?那样的话我们就跳过最后几个问题。
Hinton:另两个理论可能要花一个小时。
胶囊是个好想法,但也是个错误
主持人:那我们就继续往下问吧。你现在在做哪方面的研究?在尝试解决哪些问题?
Hinton:最终我们都是要把以前没做完的研究一直做完。我觉得我的研究里有一件东西是永远都结束不了的,那就是胶囊(capsules),它就是我心中那个通过重建进行视觉感知的理论,也是把信息路由到正确的地方的理论。在标准的神经网络里,信息,也就是每层神经元的活动,它的走向是自动的,你没法决定要让信息去哪里。胶囊的想法就是要决定把信息发送到哪里。目前来说,从我开始研究胶囊以后,有一些别的很聪明的谷歌同事创造了 Transformer 模型,做的是同样的事情。它们都是决定把信息送到哪里,这是很大的一个进步。
还有一件启发了我做胶囊的事情是坐标框架。当人类做视觉感知的时候,我们都会使用坐标框架。如果人类在一个事物上假设了错误的坐标框架,他就会认不出来那个物体。
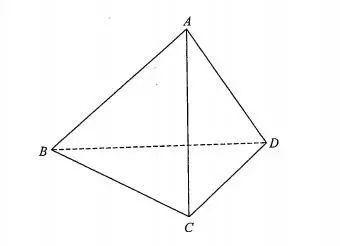
你做一个小任务感受一下:想象一个正四面体,它的底面是三角形,然后有三个三角形的侧面,四个面都是全等三角形。很容易想象对吧?然后想象用一个平面切割它,要得到一个正方形的截面。切割简单,但是得到正方形的截面就难了。每次你尝试截的时候,你都会得到一个三角形的截面。

似乎很难看到这个正方形截面要怎么截出来。那么我换个方式来描述这同一个物体。我用你的笔来笔画一下,上面是一只笔,下面也有一只笔,想象它们在空间中垂直,然后把上面的笔上的所有的点连接到下面的笔的所有的点。这样你就得到了一个四面体。现在我们看一下这个四面体和坐标框架的关系,上面的边和一条坐标轴平行,下面的边和另一条坐标轴平行。那么当你这样来看它的时候,就很容易看到如何截出来一个矩形,也就能找到在中间某个位置可以得到一个正方形。但是只有我们在这个坐标框架下思考才能看得出来。
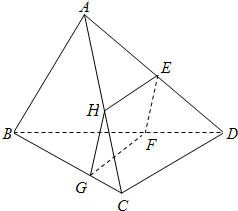
对于人类来说这一点是很显然的,但其实对感知这件事来说,坐标框架都很重要。
主持人:在模型中增加坐标框架,和你在 90 年代做的想要把规则集成到模型里结果发现是个错误,有什么区别吗?不是说要让系统是无监督的吗?
Hinton:没错,这就是同一个错误。正因为我很确定这是个糟糕的错误,所以我只能加一点点东西,有点不懂不痒。这实际上也让我自己的处境有点尴尬。
主持人:你目前的研究是专门针对视觉识别的,还是说先想到了坐标框架的事情,然后再试着把它做成更通用的样子?
Hinton:它可以可以用在其他任务里,不过我自己尤其对视觉识别里的应用感兴趣。
主持人:深度学习曾经很独特,如今似乎很大程度上就是 AI 的近义词了;同时 AI 也成了一个市场营销意味很浓的词,随便用了一个什么机器什么算法的人也说自己用了 AI。作为发展了这些技术、帮助带来了这种现状的人,你的感受如何?
Hinton:当年 AI 只是指基于逻辑的、操作符号的计算系统的时候我要快乐得多;当时的神经网络也是说你可以用神经网络学习。现在有很多企业不喜欢那些,只是在乎钱。我就是在这样的环境里长大的。如今我甚至看到有一些曾经连续很多年说神经网络是垃圾的人现在开始说「我是做 AI 的教授,所以请给我批资金」。真的很烦人。
主持人:你的研究领域起飞了,有点吞并了其它领域的味道,也就让他们有理由要钱了,有点让人沮丧。
Hinton:不过也不是完全不公平吧,有很多人确实调整了思路。
主持人:最后一个问题,你曾经在一次采访中说过,AI 有可能会像是黑洞,如果你构建它的方式不正确,它可能会反过来吃掉你。那么你在研究中是如何避免把它得有伤害、甚至做成黑洞的呢?

Hinton:我永远都不会故意做会带来伤害的 AI。当然了,如果你设计出了一个擅长吃别人的脑袋的黑洞,这就是挺不好的一件事,我是不会做这样的研究的。
主持人:好的。今天聊得很开心,谢谢你说了这么多。也许明年我们继续谈谈关于梦的第三个和第四个理论。

完整视频见:
https://www.youtube.com/watch?v=UTfQwTuri8Y
2019 全球人工智能与机器人峰会
由中国计算机学会主办、雷锋网和香港中文大学(深圳)联合承办的 2019 全球人工智能与机器人峰会( CCF-GAIR 2019),将于 2019 年 7 月 12 日至 14 日在深圳举行。
届时,诺贝尔奖得主JamesJ. Heckman、中外院士、世界顶会主席、知名Fellow,多位重磅嘉宾将亲自坐阵,一起探讨人工智能和机器人领域学、产、投等复杂的生存态势。

点击阅读原文,查看 Geoffery Hinton 其他相关文章



