字节跳动在 Spark SQL 上的核心优化实践


作者 | 郭俊
封图 | BanburyTang
字节跳动数据仓库架构团队负责数据仓库领域架构设计,支持字节跳动几乎所有产品线(包含但不限于抖音、今日头条、西瓜视频、火山视频)数据仓库方向的需求,如 Spark SQL / Druid 的二次开发和优化。字节跳动数据仓库架构负责人郭俊从 SparkSQL 的架构简介、字节跳动在 SparkSQL 引擎上的优化实践,以及字节跳动在 Spark Shuffle 稳定性提升和性能优化三个方面全方位地分享了字节跳动在 Spark SQL 上的核心优化的探索与实践。
以下为郭俊演讲精华整理:

Spark SQL 架构简介
我们先简单聊一下 Spark SQL 的架构。下面这张图描述了一条 SQL 提交之后需要经历的几个阶段,结合这些阶段就可以看到在哪些环节可以做优化。
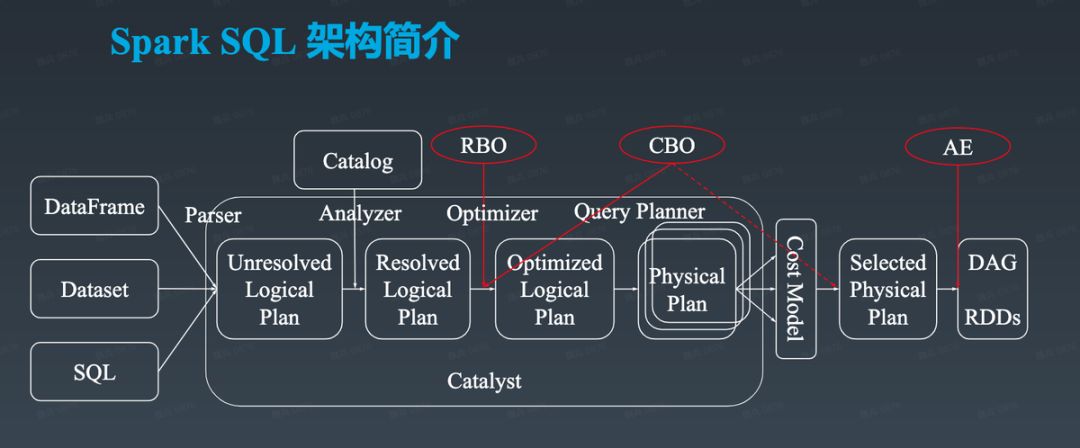
很多时候,做数据仓库建模的同学更倾向于直接写 SQL 而非使用 Spark 的 DSL。一条 SQL 提交之后会被 Parser 解析并转化为 Unresolved Logical Plan。它的重点是 Logical Plan 也即逻辑计划,它描述了希望做什么样的查询。Unresolved 是指该查询相关的一些信息未知,比如不知道查询的目标表的 Schema 以及数据位置。
上述信息存于 Catalog 内。在生产环境中,一般由 Hive Metastore 提供 Catalog 服务。Analyzer 会结合 Catalog 将 Unresolved Logical Plan 转换为 Resolved Logical Plan。
到这里还不够。不同的人写出来的 SQL 不一样,生成的 Resolved Logical Plan 也就不一样,执行效率也不一样。为了保证无论用户如何写 SQL 都可以高效的执行,Spark SQL 需要对 Resolved Logical Plan 进行优化,这个优化由 Optimizer 完成。Optimizer 包含了一系列规则,对 Resolved Logical Plan 进行等价转换,最终生成 Optimized Logical Plan。该 Optimized Logical Plan 不能保证是全局最优的,但至少是接近最优的。
上述过程只与 SQL 有关,与查询有关,但是与 Spark 无关,因此无法直接提交给 Spark 执行。Query Planner 负责将 Optimized Logical Plan 转换为 Physical Plan,进而可以直接由 Spark 执行。
由于同一种逻辑算子可以有多种物理实现。如 Join 有多种实现,ShuffledHashJoin、BroadcastHashJoin、BroadcastNestedLoopJoin、SortMergeJoin 等。因此 Optimized Logical Plan 可被 Query Planner 转换为多个 Physical Plan。如何选择最优的 Physical Plan 成为一件非常影响最终执行性能的事情。一种比较好的方式是,构建一个 Cost Model,并对所有候选的 Physical Plan 应用该 Model 并挑选 Cost 最小的 Physical Plan 作为最终的 Selected Physical Plan。
Physical Plan 可直接转换成 RDD 由 Spark 执行。我们经常说“计划赶不上变化”,在执行过程中,可能发现原计划不是最优的,后续执行计划如果能根据运行时的统计信息进行调整可能提升整体执行效率。这部分动态调整由 Adaptive Execution 完成。
后面介绍字节跳动在 Spark SQL 上做的一些优化,主要围绕这一节介绍的逻辑计划优化与物理计划优化展开。

Spark SQL 引擎优化
Bucket Join 改进
在 Spark 里,实际并没有 Bucket Join 算子。这里说的 Bucket Join 泛指不需要 Shuffle 的 SortMergeJoin。
下图展示了 SortMergeJoin 的基本原理。用虚线框代表的 Table 1 和 Table 2 是两张需要按某字段进行 Join 的表。虚线框内的 partition 0 到 partition m 是该表转换成 RDD 后的 Partition,而非表的分区。假设 Table 1 与 Table 2 转换为 RDD 后分别包含 m 和 k 个 Partition。为了进行 Join,需要通过 Shuffle 保证相同 Join Key 的数据在同一个 Partition 内且 Partition 内按 Key 排序,同时保证 Table 1 与 Table 2 经过 Shuffle 后的 RDD 的 Partition 数相同。
如下图所示,经过 Shuffle 后只需要启动 n 个 Task,每个 Task 处理 Table 1 与 Table 2 中对应 Partition 的数据进行 Join 即可。如 Task 0 只需要顺序扫描 Shuffle 后的左右两边的 partition 0 即可完成 Join。
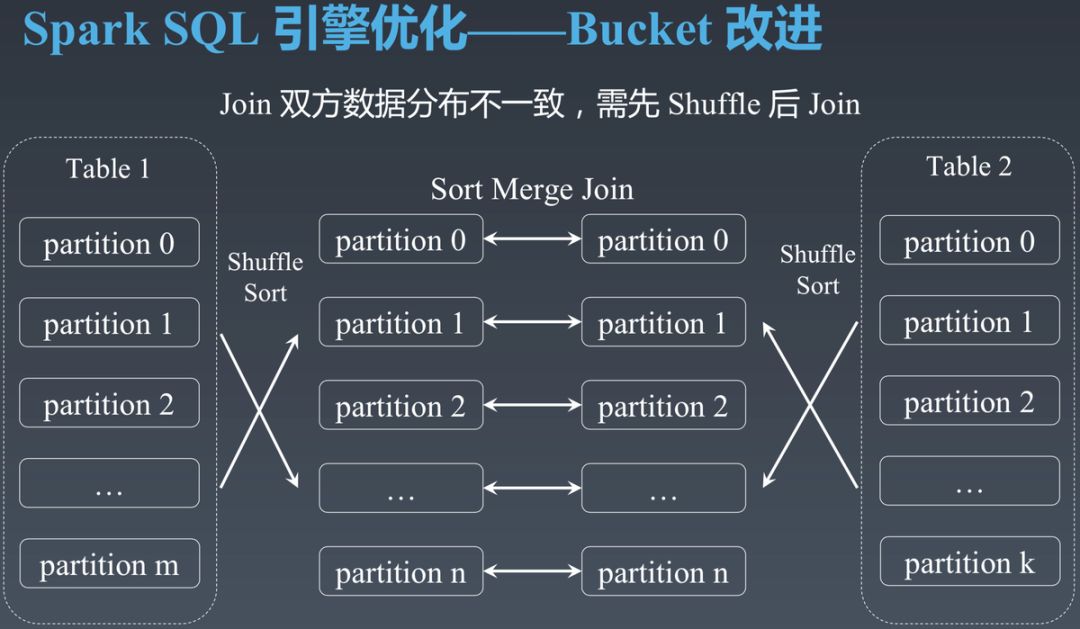
该方法的优势是适用场景广,几乎可用于任意大小的数据集。劣势是每次 Join 都需要对全量数据进行 Shuffle,而 Shuffle 是最影响 Spark SQL 性能的环节。如果能避免 Shuffle 往往能大幅提升 Spark SQL 性能。
对于大数据的场景来讲,数据一般是一次写入多次查询。如果经常对两张表按相同或类似的方式进行 Join,每次都需要付出 Shuffle 的代价。与其这样,不如让数据在写的时候,就让数据按照利于 Join 的方式分布,从而使得 Join 时无需进行 Shuffle。如下图所示,Table 1 与 Table 2 内的数据按照相同的 Key 进行分桶且桶数都为 n,同时桶内按该 Key 排序。对这两张表进行 Join 时,可以避免 Shuffle,直接启动 n 个 Task 进行 Join。

字节跳动对 Spark SQL 的 BucketJoin 做了四项比较大的改进。
改进一:支持与 Hive 兼容
在过去一段时间,字节跳动把大量的 Hive 作业迁移到了 SparkSQL。而 Hive 与 Spark SQL 的 Bucket 表不兼容。对于使用 Bucket 表的场景,如果直接更新计算引擎,会造成 Spark SQL 写入 Hive Bucket 表的数据无法被下游的 Hive 作业当成 Bucket 表进行 Bucket Join,从而造成作业执行时间变长,可能影响 SLA。
为了解决这个问题,我们让 Spark SQL 支持 Hive 兼容模式,从而保证 Spark SQL 写入的 Bucket 表与 Hive 写入的 Bucket 表效果一致,并且这种表可以被 Hive 和 Spark SQL 当成 Bucket 表进行 Bucket Join 而不需要 Shuffle。通过这种方式保证 Hive 向 Spark SQL 的透明迁移。
第一个需要解决的问题是,Hive 的一个 Bucket 一般只包含一个文件,而 Spark SQL 的一个 Bucket 可能包含多个文件。解决办法是动态增加一次以 Bucket Key 为 Key 并且并行度与 Bucket 个数相同的 Shuffle。
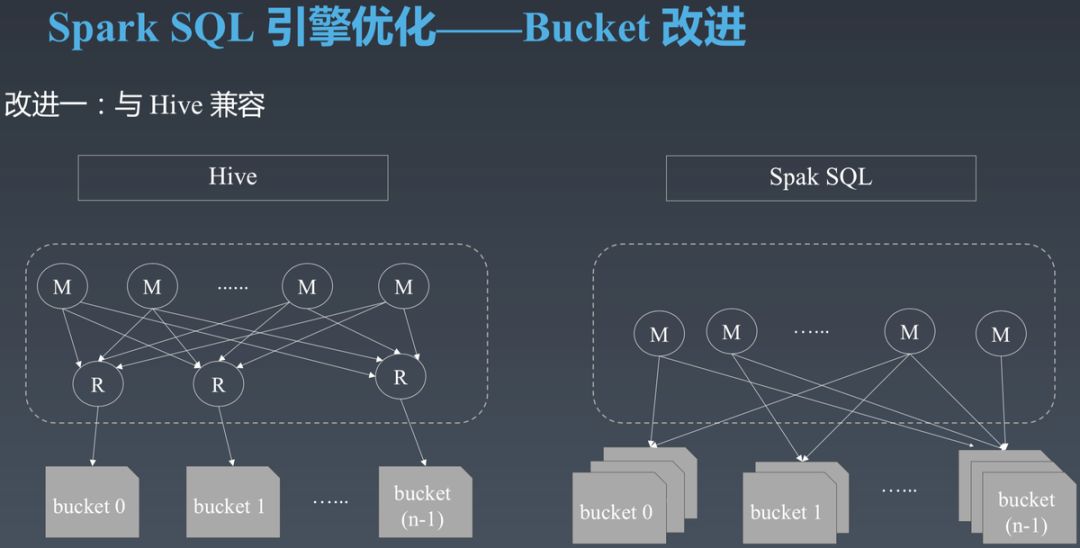
第二个需要解决的问题是,Hive 1.x 的哈希方式与 Spark SQL 2.x 的哈希方式(Murmur3Hash)不同,使得相同的数据在 Hive 中的 Bucket ID 与 Spark SQL 中的 Bucket ID 不同而无法直接 Join。在 Hive 兼容模式下,我们让上述动态增加的 Shuffle 使用 Hive 相同的哈希方式,从而解决该问题。
改进二:支持倍数关系 Bucket Join
Spark SQL 要求只有 Bucket 相同的表才能(必要非充分条件)进行 Bucket Join。对于两张大小相差很大的表,比如几百 GB 的维度表与几十 TB (单分区)的事实表,它们的 Bucket 个数往往不同,并且个数相差很多,默认无法进行 Bucket Join。因此我们通过两种方式支持了倍数关系的 Bucket Join,即当两张 Bucket 表的 Bucket 数是倍数关系时支持 Bucket Join。
第一种方式,Task 个数与小表 Bucket 个数相同。如下图所示,Table A 包含 3 个 Bucket,Table B 包含 6 个 Bucket。此时 Table B 的 bucket 0 与 bucket 3 的数据合集应该与 Table A 的 bucket 0 进行 Join。这种情况下,可以启动 3 个 Task。其中 Task 0 对 Table A 的 bucket 0 与 Table B 的 bucket 0 + bucket 3 进行 Join。在这里,需要对 Table B 的 bucket 0 与 bucket 3 的数据再做一次 merge sort 从而保证合集有序。

如果 Table A 与 Table B 的 Bucket 个数相差不大,可以使用上述方式。如果 Table B 的 Bucket 个数是 Bucket A Bucket 个数的 10 倍,那上述方式虽然避免了 Shuffle,但可能因为并行度不够反而比包含 Shuffle 的 SortMergeJoin 速度慢。此时可以使用另外一种方式,即 Task 个数与大表 Bucket 个数相等,如下图所示。

在该方案下,可将 Table A 的 3 个 Bucket 读多次。在上图中,直接将 Table A 与 Table A 进行 Bucket Union (新的算子,与 Union 类似,但保留了 Bucket 特性),结果相当于 6 个 Bucket,与 Table B 的 Bucket 个数相同,从而可以进行 Bucket Join。
改进三:支持 BucketJoin 降级
公司内部过去使用 Bucket 的表较少,在我们对 Bucket 做了一系列改进后,大量用户希望将表转换为 Bucket 表。转换后,表的元信息显示该表为 Bucket 表,而历史分区内的数据并未按 Bucket 表要求分布,在查询历史数据时会出现无法识别 Bucket 的问题。
同时,由于数据量上涨快,平均 Bucket 大小也快速增长。这会造成单 Task 需要处理的数据量过大进而引起使用 Bucket 后的效果可能不如直接使用基于 Shuffle 的 Join。
为了解决上述问题,我们实现了支持降级的 Bucket 表。基本原理是,每次修改 Bucket 信息(包含上述两种情况——将非 Bucket 表转为 Bucket 表,以及修改 Bucket 个数)时,记录修改日期。并且在决定使用哪种 Join 方式时,对于 Bucket 表先检查所查询的数据是否只包含该日期之后的分区。如果是,则当成 Bucket 表处理,支持 Bucket Join;否则当成普通无 Bucket 的表。
改进四:支持超集
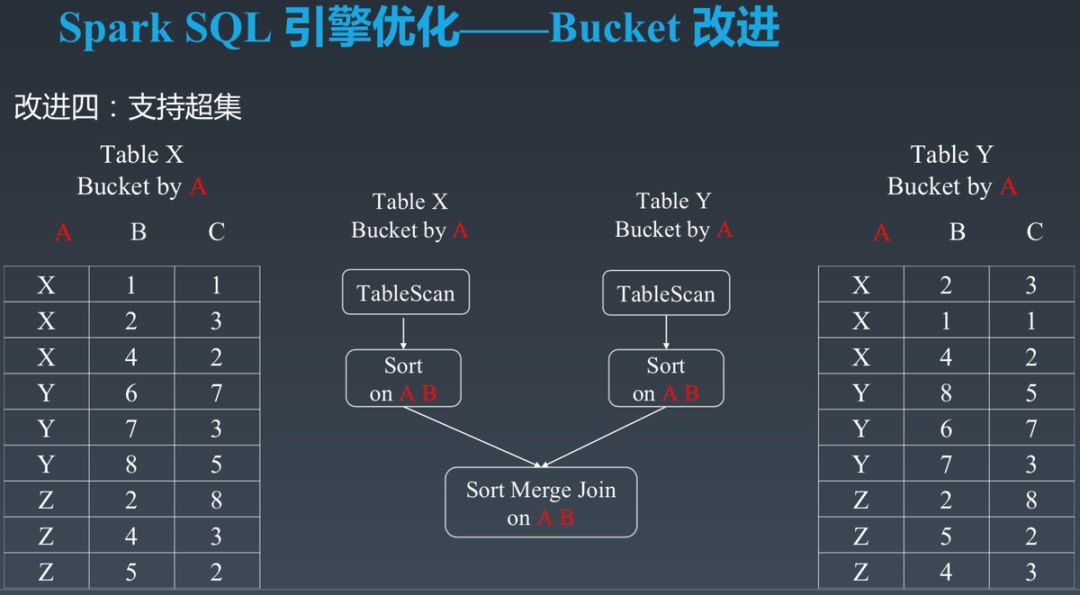
对于一张常用表,可能会与另外一张表按 User 字段做 Join,也可能会与另外一张表按 User 和 App 字段做 Join,与其它表按 User 与 Item 字段进行 Join。而 Spark SQL 原生的 Bucket Join 要求 Join Key Set 与表的 Bucket Key Set 完全相同才能进行 Bucket Join。在该场景中,不同 Join 的 Key Set 不同,因此无法同时使用 Bucket Join。这极大的限制了 Bucket Join 的适用场景。
针对此问题,我们支持了超集场景下的 Bucket Join。只要 Join Key Set 包含了 Bucket Key Set,即可进行 Bucket Join。
如下图所示,Table X 与 Table Y,都按字段 A 分 Bucket。而查询需要对 Table X 与 Table Y 进行 Join,且 Join Key Set 为 A 与 B。此时,由于 A 相等的数据,在两表中的 Bucket ID 相同,那 A 与 B 各自相等的数据在两表中的 Bucket ID 肯定也相同,所以数据分布是满足 Join 要求的,不需要 Shuffle。同时,Bucket Join 还需要保证两表按 Join Key Set 即 A 和 B 排序,此时只需要对 Table X 与 Table Y 进行分区内排序即可。由于两边已经按字段 A 排序了,此时再按 A 与 B 排序,代价相对较低。
物化列
Spark SQL 处理嵌套类型数据时,存在以下问题:
读取大量不必要的数据:对于 Parquet / ORC 等列式存储格式,可只读取需要的字段,而直接跳过其它字段,从而极大节省 IO。而对于嵌套数据类型的字段,如下图中的 Map 类型的 people 字段,往往只需要读取其中的子字段,如 people.age。却需要将整个 Map 类型的 people 字段全部读取出来然后抽取出 people.age 字段。这会引入大量的无意义的 IO 开销。在我们的场景中,存在不少 Map 类型的字段,而且很多包含几十至几百个 Key,这也就意味着 IO 被放大了几十至几百倍。
无法进行向量化读取:而向量化读能极大的提升性能。但截止到目前(2019 年 10 月 26 日),Spark 不支持包含嵌套数据类型的向量化读取。这极大地影响了包含嵌套数据类型的查询性能。
不支持 Filter 下推:目前(2019 年 10 月 26 日)的 Spark 不支持嵌套类型字段上的 Filter 的下推。
重复计算:JSON 字段,在 Spark SQL 中以 String 类型存在,严格来说不算嵌套数据类型。不过实践中也常用于保存不固定的多个字段,在查询时通过 JSON Path 抽取目标子字段,而大型 JSON 字符串的字段抽取非常消耗 CPU。对于热点表,频繁重复抽取相同子字段非常浪费资源。
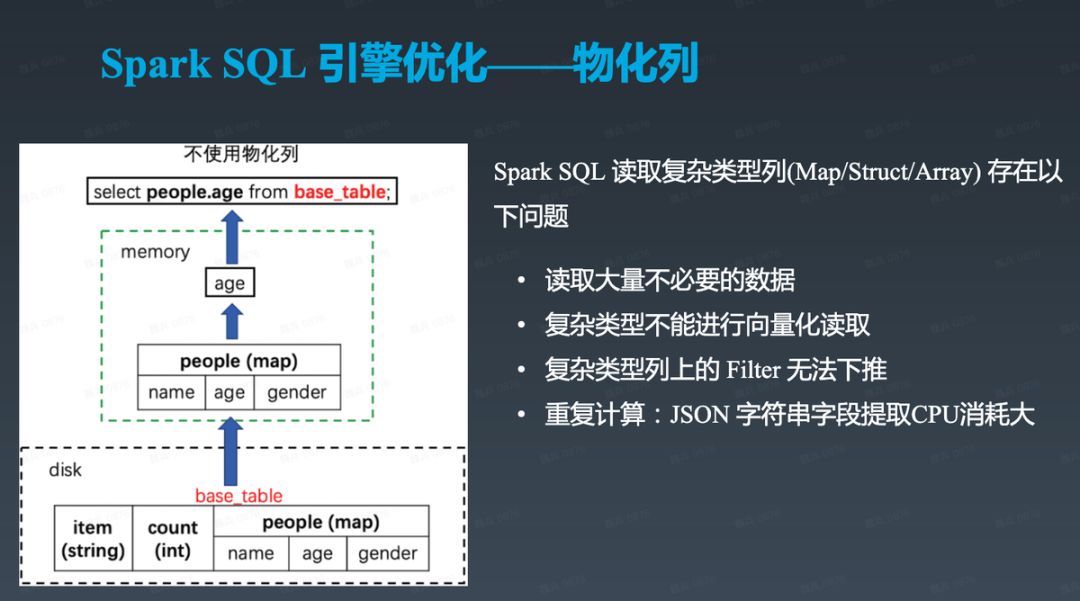
对于这个问题,做数仓的同学也想了一些解决方案。如下图所示,在名为 base_table 的表之外创建了一张名为 sub_table 的表,并且将高频使用的子字段 people.age 设置为一个额外的 Integer 类型的字段。下游不再通过 base_table 查询 people.age,而是使用 sub_table 上的 age 字段代替。通过这种方式,将嵌套类型字段上的查询转为了 Primitive 类型字段的查询,同时解决了上述问题。
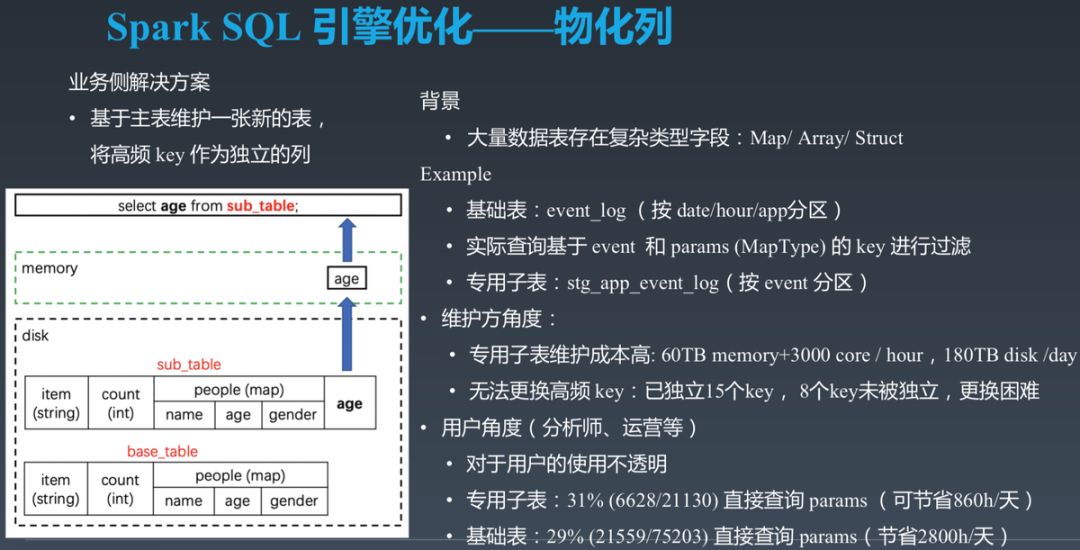
这种方案存在明显缺陷:
额外维护了一张表,引入了大量的额外存储/计算开销。
无法在新表上查询新增字段的历史数据(如要支持对历史数据的查询,需要重跑历史作业,开销过大,无法接受)。
表的维护方需要在修改表结构后修改插入数据的作业。
需要下游查询方修改查询语句,推广成本较大。
运营成本高:如果高频子字段变化,需要删除不再需要的独立子字段,并添加新子字段为独立字段。删除前,需要确保下游无业务使用该字段。而新增字段需要通知并推进下游业务方使用新字段。
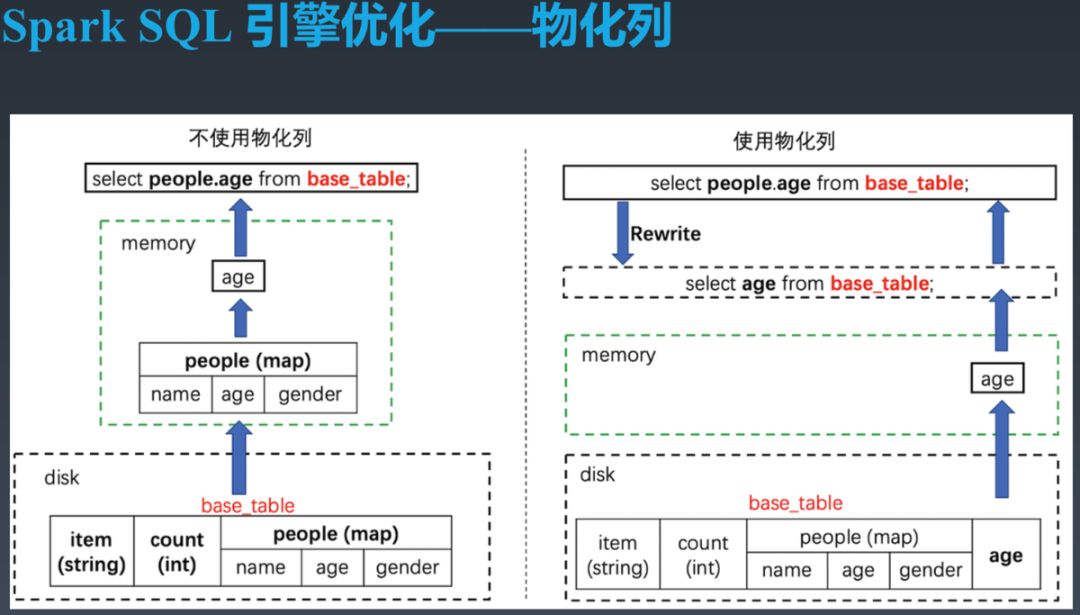
为解决上述所有问题,我们设计并实现了物化列。它的原理是:
新增一个 Primitive 类型字段,比如 Integer 类型的 age 字段,并且指定它是 people.age 的物化字段。
插入数据时,为物化字段自动生成数据,并在 Partition Parameter 内保存物化关系。因此对插入数据的作业完全透明,表的维护方不需要修改已有作业。
查询时,检查所需查询的所有 Partition,如果都包含物化信息(people.age 到 age 的映射),直接将 select people.age 自动重写为 select age,从而实现对下游查询方的完全透明优化。同时兼容历史数据。
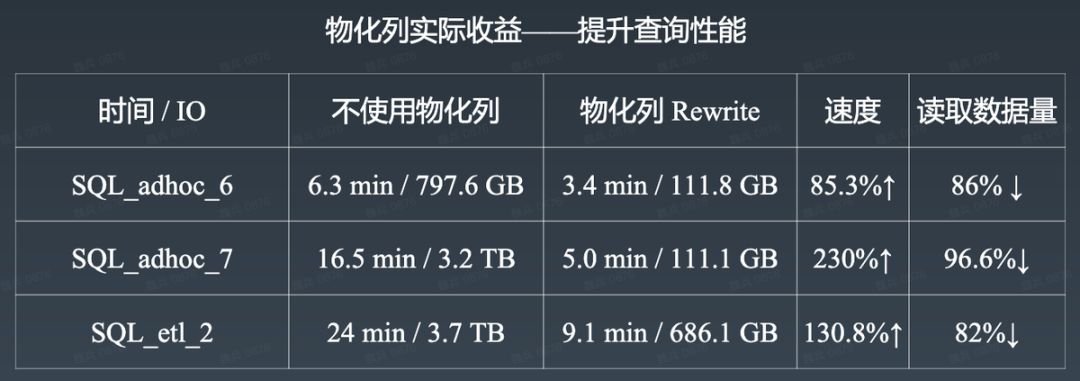
下图展示了在某张核心表上使用物化列的收益:
物化视图
在 OLAP 领域,经常会对相同表的某些固定字段进行 Group By 和 Aggregate / Join 等耗时操作,造成大量重复性计算,浪费资源,且影响查询性能,不利于提升用户体验。
我们实现了基于物化视图的优化功能:

如上图所示,查询历史显示大量查询根据 user 进行 group by,然后对 num 进行 sum 或 count 计算。此时可创建一张物化视图,且对 user 进行 gorup by,对 num 进行 avg(avg 会自动转换为 count 和 sum)。用户对原始表进行 select user, sum(num) 查询时,Spark SQL 自动将查询重写为对物化视图的 select user, sum_num 查询。
Spark SQL 引擎上的其它优化
下图展示了我们在 Spark SQL 上进行的其它部分优化工作:


Spark Shuffle 稳定性提升与性能优化
Spark Shuffle 存在的问题
Shuffle 的原理,很多同学应该已经很熟悉了。鉴于时间关系,这里不介绍过多细节,只简单介绍下基本模型。
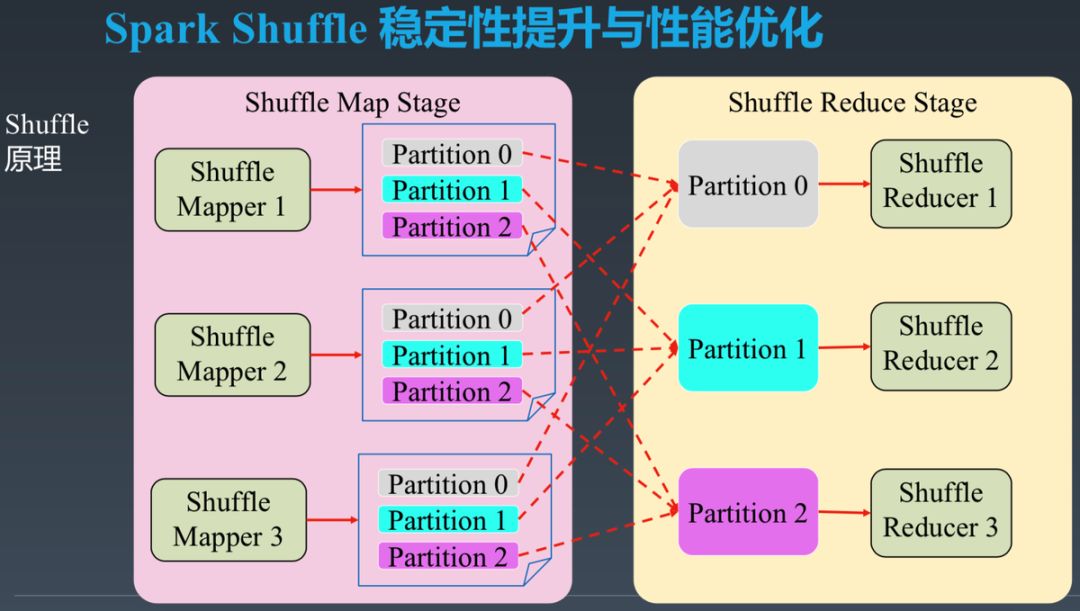
如上图所示,我们将 Shuffle 上游 Stage 称为 Mapper Stage,其中的 Task 称为 Mapper。Shuffle 下游 Stage 称为 Reducer Stage,其中的 Task 称为 Reducer。
每个 Mapper 会将自己的数据分为最多 N 个部分,N 为 Reducer 个数。每个 Reducer 需要去最多 M (Mapper 个数)个 Mapper 获取属于自己的那部分数据。
这个架构存在两个问题:
稳定性问题:
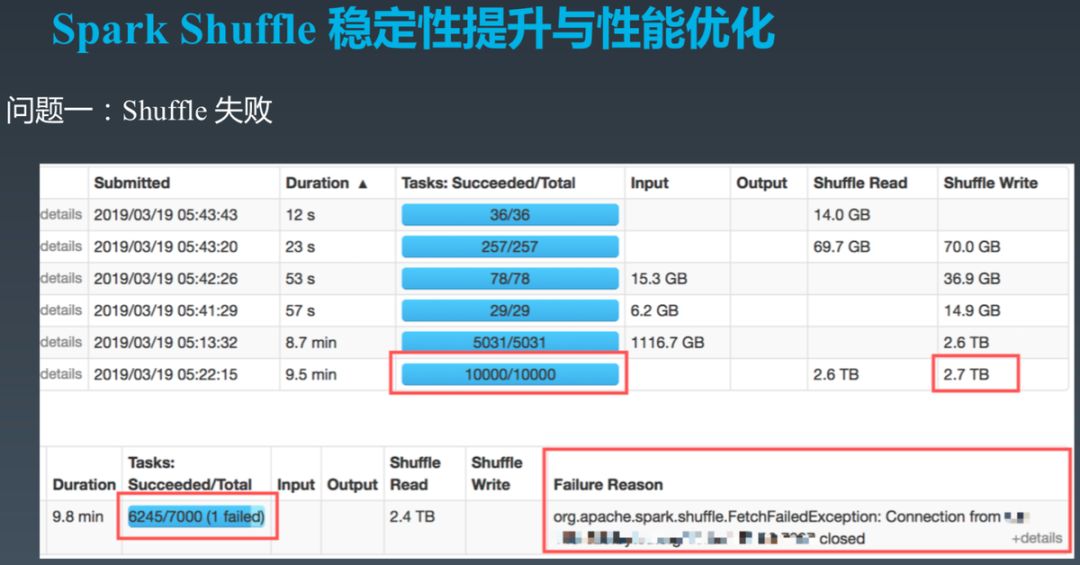
Mapper 的 Shuffle Write 数据存于 Mapper 本地磁盘,只有一个副本。当该机器出现磁盘故障,或者 IO 满载,CPU 满载时,Reducer 无法读取该数据,从而引起 FetchFailedException,进而导致 Stage Retry。Stage Retry 会造成作业执行时间增长,直接影响 SLA。同时,执行时间越长,出现 Shuffle 数据无法读取的可能性越大,反过来又会造成更多 Stage Retry。如此循环,可能导致大型作业无法成功执行。
性能问题:
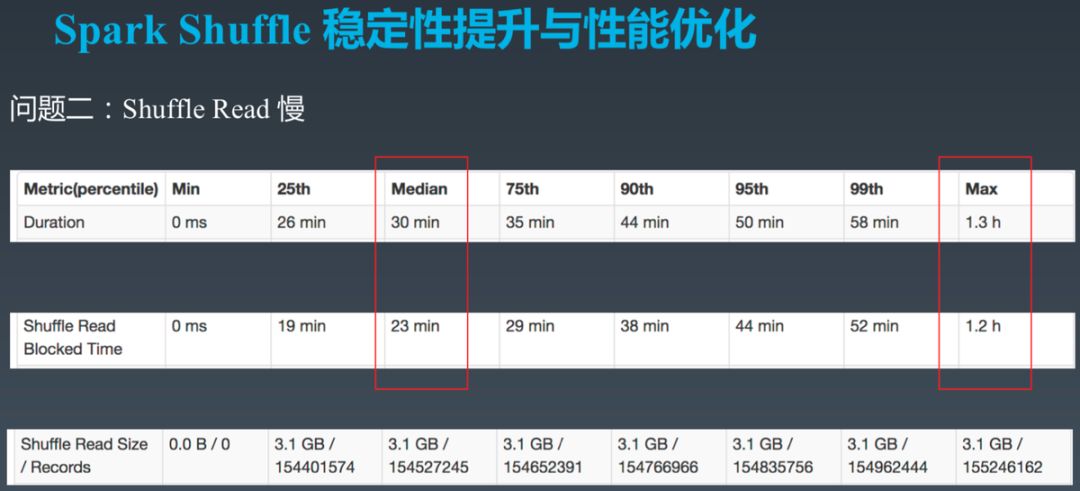
每个 Mapper 的数据会被大量 Reducer 读取,并且是随机读取不同部分。假设 Mapper 的 Shuffle 输出为 512MB,Reducer 有 10 万个,那平均每个 Reducer 读取数据 512MB / 100000 = 5.24KB。并且,不同 Reducer 并行读取数据。对于 Mapper 输出文件而言,存在大量的随机读取。而 HDD 的随机 IO 性能远低于顺序 IO。最终的现象是,Reducer 读取 Shuffle 数据非常慢,反映到 Metrics 上就是 Reducer Shuffle Read Blocked Time 较长,甚至占整个 Reducer 执行时间的一大半,如下图所示。
基于 HDFS 的 Shuffle 稳定性提升
经观察,引起 Shuffle 失败的最大因素不是磁盘故障等硬件问题,而是 CPU 满载和磁盘 IO 满载。
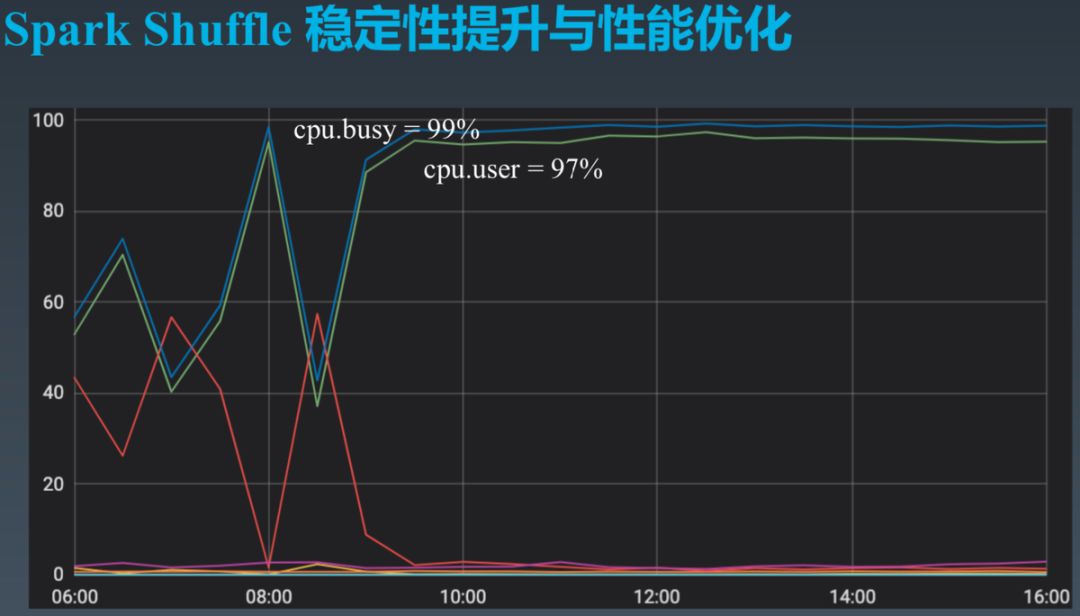
如上图所示,机器的 CPU 使用率接近 100%,使得 Mapper 侧的 Node Manager 内的 Spark External Shuffle Service 无法及时提供 Shuffle 服务。
下图中 Data Node 占用了整台机器 IO 资源的 84%,部分磁盘 IO 完全打满,这使得读取 Shuffle 数据非常慢,进而使得 Reducer 侧无法在超时时间内读取数据,造成 FetchFailedException。

无论是何种原因,问题的症结都是 Mapper 侧的 Shuffle Write 数据只保存在本地,一旦该节点出现问题,会造成该节点上所有 Shuffle Write 数据无法被 Reducer 读取。解决这个问题的一个通用方法是,通过多副本保证可用性。
最初始的一个简单方案是,Mapper 侧最终数据文件与索引文件不写在本地磁盘,而是直接写到 HDFS。Reducer 不再通过 Mapper 侧的 External Shuffle Service 读取 Shuffle 数据,而是直接从 HDFS 上获取数据,如下图所示。
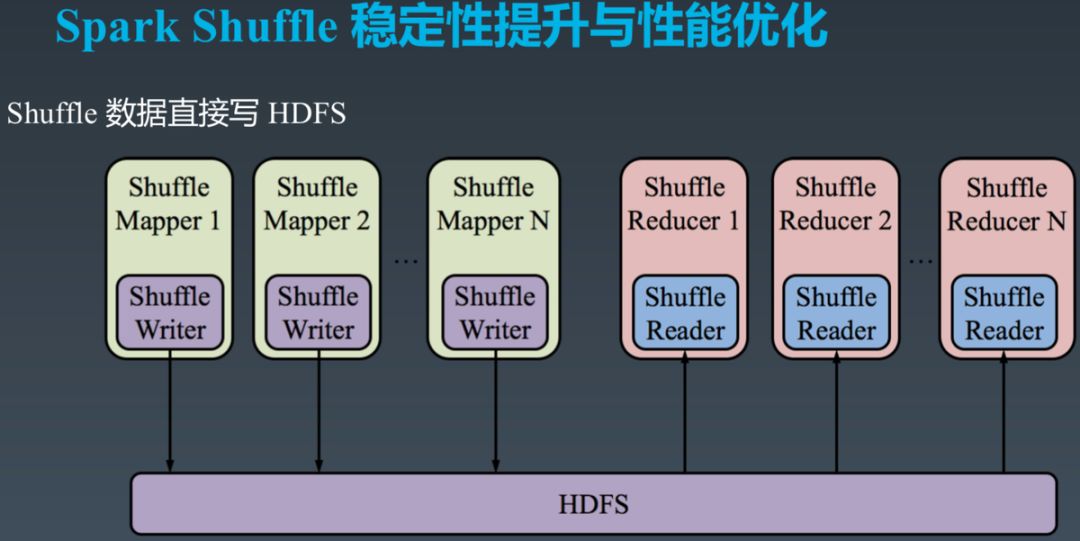
快速实现这个方案后,我们做了几组简单的测试。结果表明:
Mapper 与 Reducer 不多时,Shuffle 读写性能与原始方案相比无差异。
Mapper 与 Reducer 较多时,Shuffle 读变得非常慢。

在上面的实验过程中,HDFS 发出了报警信息。如下图所示,HDFS Name Node Proxy 的 QPS 峰值达到 60 万。(注:字节跳动自研了 Node Name Proxy,并在 Proxy 层实现了缓存,因此读 QPS 可以支撑到这个量级)。
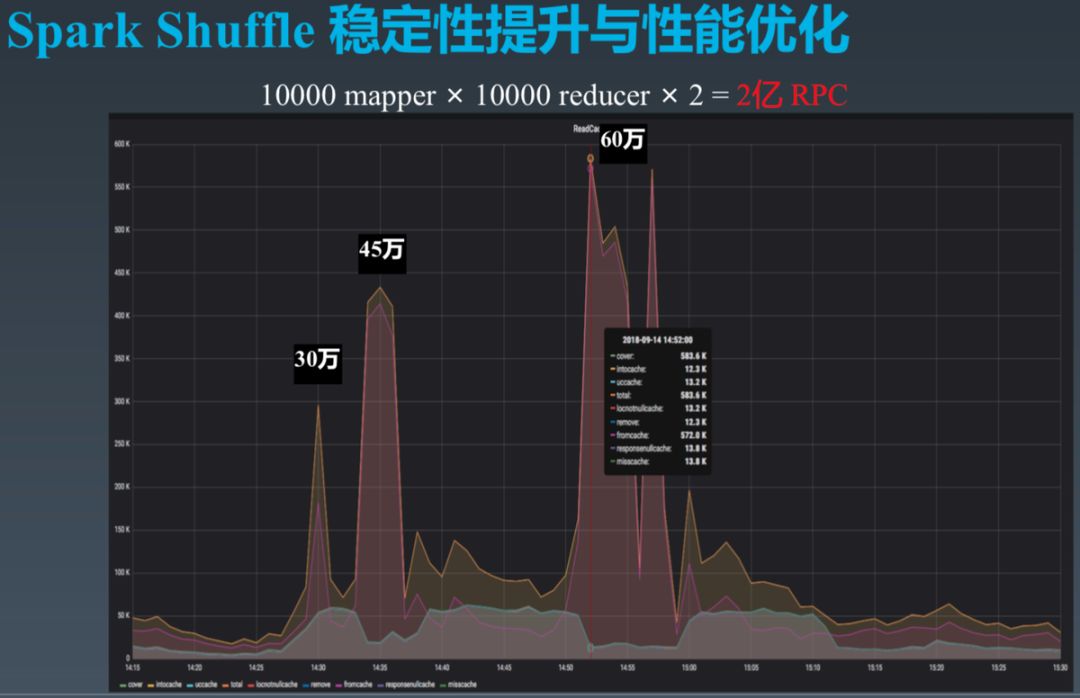
原因在于,总共 10000 Reducer,需要从 10000 个 Mapper 处读取数据文件和索引文件,总共需要读取 HDFS 10000 * 1000 * 2 = 2 亿次。
如果只是 Name Node 的单点性能问题,还可以通过一些简单的方法解决。例如在 Spark Driver 侧保存所有 Mapper 的 Block Location,然后 Driver 将该信息广播至所有 Executor,每个 Reducer 可以直接从 Executor 处获取 Block Location,然后无须连接 Name Node,而是直接从 Data Node 读取数据。但鉴于 Data Node 的线程模型,这种方案会对 Data Node 造成较大冲击。
最后我们选择了一种比较简单可行的方案,如下图所示。
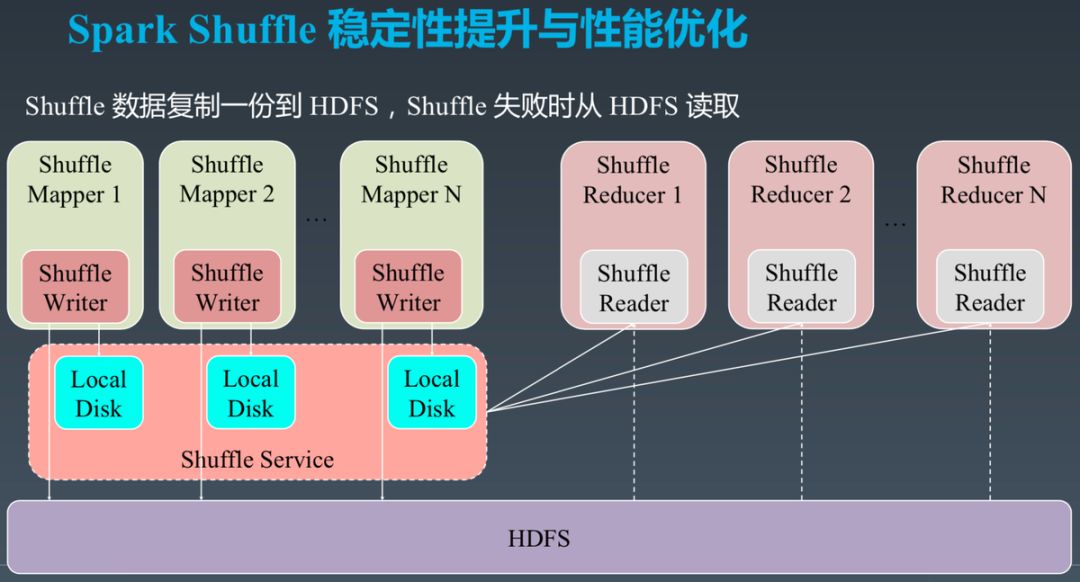
Mapper 的 Shuffle 输出数据仍然按原方案写本地磁盘,写完后上传到 HDFS。Reducer 仍然按原始方案通过 Mapper 侧的 External Shuffle Service 读取 Shuffle 数据。如果失败了,则从 HDFS 读取。这种方案极大减少了对 HDFS 的访问频率。
该方案上线近一年:
覆盖 57% 以上的 Spark Shuffle 数据。
使得 Spark 作业整体性能提升 14%。
天级大作业性能提升 18%。
小时级作业性能提升 12%。

该方案旨在提升 Spark Shuffle 稳定性从而提升作业稳定性,但最终没有使用方差等指标来衡量稳定性的提升。原因在于每天集群负载不一样,整体方差较大。Shuffle 稳定性提升后,Stage Retry 大幅减少,整体作业执行时间减少,也即性能提升。最终通过对比使用该方案前后的总的作业执行时间来对比性能的提升,用于衡量该方案的效果。
Shuffle 性能优化实践与探索
如上文所分析,Shuffle 性能问题的原因在于,Shuffle Write 由 Mapper 完成,然后 Reducer 需要从所有 Mapper 处读取数据。这种模型,我们称之为以 Mapper 为中心的 Shuffle。它的问题在于:
Mapper 侧会有 M 次顺序写 IO。
Mapper 侧会有 M * N * 2 次随机读 IO(这是最大的性能瓶颈)。
Mapper 侧的 External Shuffle Service 必须与 Mapper 位于同一台机器,无法做到有效的存储计算分离,Shuffle 服务无法独立扩展。
针对上述问题,我们提出了以 Reducer 为中心的,存储计算分离的 Shuffle 方案,如下图所示。
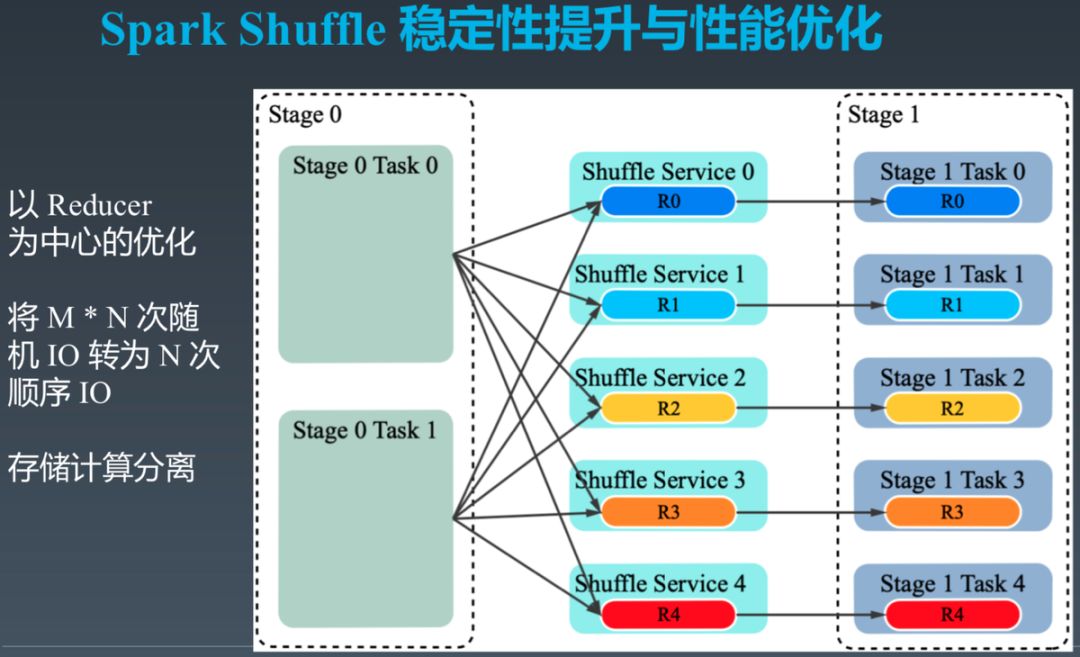
该方案的原理是,Mapper 直接将属于不同 Reducer 的数据写到不同的 Shuffle Service。在上图中,总共 2 个 Mapper,5 个 Reducer,5 个 Shuffle Service。所有 Mapper 都将属于 Reducer 0 的数据远程流式发送给 Shuffle Service 0,并由它顺序写入磁盘。Reducer 0 只需要从 Shuffle Service 0 顺序读取所有数据即可,无需再从 M 个 Mapper 取数据。该方案的优势在于:
将 M * N * 2 次随机 IO 变为 N 次顺序 IO。
Shuffle Service 可以独立于 Mapper 或者 Reducer 部署,从而做到独立扩展,做到存储计算分离。
Shuffle Service 可将数据直接存于 HDFS 等高可用存储,因此可同时解决 Shuffle 稳定性问题。
我的分享就到这里,谢谢大家。

QA 集锦
提问:物化列新增一列,是否需要修改历史数据?
回答:历史数据太多,不适合修改历史数据。
提问:如果用户的请求同时包含新数据和历史数据,如何处理?
回答:一般而言,用户修改数据都是以 Partition 为单位。所以我们在 Partition Parameter 上保存了物化列相关信息。如果用户的查询同时包含了新 Partition 与历史 Partition,我们会在新 Partition 上针对物化列进行 SQL Rewrite,历史 Partition 不 Rewrite,然后将新老 Partition 进行 Union,从而在保证数据正确性的前提下尽可能充分利用物化列的优势。
提问:你们针对用户的场景,做了很多挺有价值的优化。像物化列、物化视图,都需要根据用户的查询 Pattern 进行设置。目前你们是人工分析这些查询,还是有某种机制自动去分析并优化?
回答:目前我们主要是通过一些审计信息辅助人工分析。同时我们也正在做物化列与物化视图的推荐服务,最终做到智能建设物化列与物化视图。
提问:刚刚介绍的基于 HDFS 的 Spark Shuffle 稳定性提升方案,是否可以异步上传 Shuffle 数据至 HDFS?
回答:这个想法挺好,我们之前也考虑过,但基于几点考虑,最终没有这样做。第一,单 Mapper 的 Shuffle 输出数据量一般很小,上传到 HDFS 耗时在 2 秒以内,这个时间开销可以忽略;第二,我们广泛使用 External Shuffle Service 和 Dynamic Allocation,Mapper 执行完成后可能 Executor 就回收了,如果要异步上传,就必须依赖其它组件,这会提升复杂度,ROI 较低。
【END】

热 文 推 荐
☞大白话讲解比特币白皮书,十年后它依然是学习区块链的最佳资料,你真的读懂了吗?






