港中大-商汤联合实验室等提出:Guided Anchoring: 物体检测器也能自己学 Anchor
点击上方“CVer”,选择"星标"和“置顶”
重磅干货,第一时间送达

前戏
最近目标检测方向,出了很多paper(难道为了赶顶会ddl),CVer也立即跟进报道(点击可访问):
本文介绍一篇同样很棒的paper,由香港中文大学-商汤联合实验室提出,后面有原作者的论文解读。重点是预计3月底或4月初开源。
简介
《Region Proposal by Guided Anchoring》

arXiv: https://arxiv.org/abs/1901.03278
github: 3月底或4月初
作者团队:香港中文大学-商汤联合实验室&Amazon Rekognition&南洋理工大学
注:2019年01月10日刚出炉的paper
下面附上论文第一作者:陈恺博士对论文的解读
链接(已获权转载):
https://zhuanlan.zhihu.com/p/55854246
论文解读
前言
进入图片物体检测这个坑也有一年出头了,而且至少短期内还将继续待在坑里而且还拉了同伙入坑。值此新(ji)春(xu)佳(ban)节(zhuan)之际,打算介绍一些做过的工作,写一下对这个领域的理解,另外有空的话也会讲讲 mmdetection 的设计和一些实现。
作为开篇,就讲一下启动最早的一个项目,"Region Proposal by Guided Anchoring"。这篇 paper 的方法用在了 COCO Challenge 2018 检测任务的冠军方法中,在极高的 baseline 上涨了1个点。最近公开在 ArXiv 上,欢迎大家提出意见。
概述
我们提出了一种新的 anchor 生成方法 —— Guided Anchoring,即通过图像特征来指导 anchor 的生成。通过预测 anchor 的位置和形状,来生成稀疏而且形状任意的 anchor,并且设计了 Feature Adaption 模块来修正特征图使之与 anchor 形状更加匹配。在使用 ResNet-50-FPN 作为 backbone 的情况下,Guided Anchoring 将 RPN 的 recall(AR@1000) 提高了 9.1 个点,将其用于不同的物体检测器上,可以提高 mAP 1.2 到 2.7 个点不等。
下图是我们的方法和传统 RPN 的性能和速度对比,可以看到要显著优于传统 RPN。

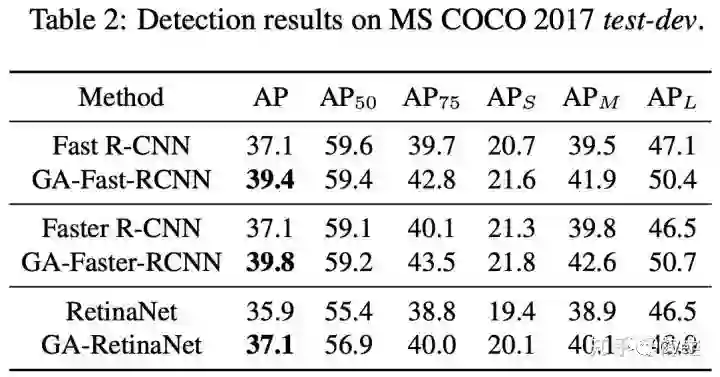
下面是应用在不同检测方法上的结果,backbone 均为 ResNet-50-FPN。
背景
Anchor 是物体检测中的一个重要概念,通常是人为设计的一组框,作为分类(classification)和框回归(bounding box regression)的基准框。无论是单阶段(single-stage)检测器还是两阶段(two-stage)检测器,都广泛地使用了 anchor。例如,两阶段检测器的第一阶段通常采用 RPN 生成 proposal,是对 anchor 进行分类和回归的过程,即 anchor -> proposal -> detection bbox;大部分单阶段检测器是直接对 anchor 进行分类和回归,也就是 anchor -> detection bbox。
常见的生成 anchor 的方式是滑窗(sliding window),也就是首先定义 k 个特定尺度(scale)和长宽比(aspect ratio)的 anchor,然后在全图上以一定的步长滑动。这种方式在 Faster R-CNN,SSD,RetinaNet 等经典检测方法中被广泛使用。
Motivation
通过 sliding window 生成 anchor 的办法简单可行,但也不是完美的,不然就不会有要讲的这篇 paper 了。首先,anchor 的尺度和长宽比需要预先定义,这是一个对性能影响比较大的超参,而且对于不同数据集和方法需要单独调整。如果尺度和长宽比设置不合适,可能会导致 recall 不够高,或者 anchor 过多影响分类性能和速度。一方面,大部分的 anchor 都分布在背景区域,对 proposal 或者检测不会有任何正面作用;另一方面,预先定义好的 anchor 形状不一定能满足极端大小或者长宽比悬殊的物体。所以我们期待的是稀疏,形状根据位置可变的 anchor。

Formulation
首先我们思考 anchor 是如何生成的。我们通常使用 4 个数 (x, y, w, h) 来描述一个 anchor,即中心点坐标和宽高。我们将 anchor 的分布 formulate 成如下公式。
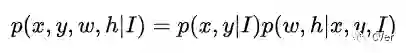
Anchor 的概率分布被分解为两个条件概率分布,也就是给定图像特征之后 anchor 中心点的概率分布,和给定图像特征和中心点之后的形状概率分布,这也是论文标题中 Guided Anchoring 的由来。Sliding window 可以看成是 p(x,y|I) 是均匀分布而 p(w,h|x,y,I) 是冲激函数的一个特例。
根据上面的公式,anchor 的生成过程可以分解为两个步骤,anchor 位置预测和形状预测。在这个看起来很简单的 formulation 上,我们走过一些弯路,讨论过一些奇奇怪怪的方法,最后发现大道至简。
方法
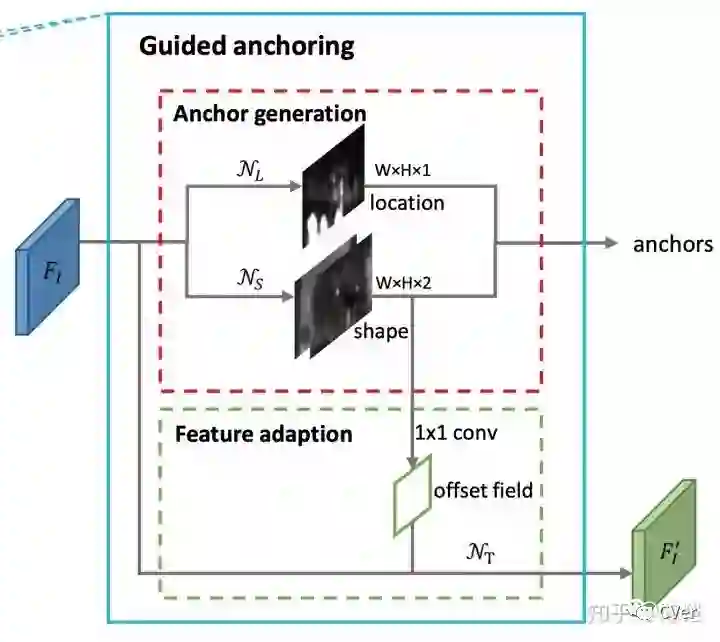
如图所示,在原始 RPN 的特征图基础上,我们采用两个分支分别预测 anchor 位置和形状,然后结合在一起得到 anchor。之后采用一个 Feature Adaption 模块进行 anchor 特征的调整,得到新的特征图供之后的预测(anchor 的分类和回归)使用。整个方法可以 end-to-end training,而且相比之前只是增加了 3 个 1x1 conv 和一个 3x3 deformable conv,带来的模型参数量的变化很小。
位置预测
位置预测分支的目标是预测那些区域应该作为中心点来生成 anchor,是一个二分类问题。不同于 RPN 或者 segmentation 的分类,这里我们并不是预测每个点是前景还是背景,而是预测是不是物体的中心。
我们将整个 feature map 的区域分为物体中心区域,外围区域和忽略区域,大概思路就是将 ground truth 框的中心一小块对应在 feature map 上的区域标为物体中心区域,在训练的时候作为正样本,其余区域按照离中心的距离标为忽略或者负样本,具体设计在 paper 里讲得比较清楚。通过位置预测,我们可以筛选出一小部分区域作为 anchor 的候选中心点位置,使得 anchor 数量大大降低。在 inference 的时候,预测完位置之后,我们可以采用 masked conv 替代普通的 conv,只在有 anchor 的地方进行计算,可以进行加速。
形状预测
形状预测分支的目标是给定 anchor 中心点,预测最佳的长和宽,这是一个回归问题。按照往常做法,当然是先算出 target,也就是该中心点的 anchor 最优的 w 和 h,然后用 L1/L2/Smooth L1 这类 loss 来监督。然而这玩意的 target 并不好计算,而且实现起来也会比较困难,所以我们直接使用 IoU 作为监督,来学习 w 和 h。既然我们算不出来最优的 w 和 h,而计算 IoU 又是可导的操作,那就让网络自己去优化使得 IoU 最大吧。后来改用了 bounded IoU Loss,但原理是一样的。
这里面还有个问题,就是对于某个 anchor,应该优化和哪个 ground truth 的 IoU,也就是说应该把这个 anchor 分配给哪个 ground truth。对于以前常规的 anchor,我们可以直接计算它和所有 ground truth 的 IoU,然后将它分配给 IoU 最大的那个 gt。但是很不幸现在的 anchor 的 w 和 h 是不确定的,是一个需要预测的变量。我们将这个 anchor 和某个 gt 的 IoU 表示为
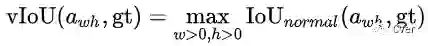
。当然我们不可能真的把所有可能的 w 和 h 遍历一遍然后求 IoU 的最大值,所以采用了近似的方法,也就是 sample 一些可能的 w 和 h。理论上 sample 得越多,近似效果越好,但出于效率的考虑,我们 sample 了常见的 9 组 w 和 h。我们通过实验发现,最终结果对 sample 的组数这个超参并不敏感,也就是说不管 sample 多少组,近似效果已经足够。
生成 anchor
在得到 anchor 位置和中心点的预测之后,我们便可以生成 anchor 了,如下图所示。这时的 anchor 是稀疏而且每个位置不一样的。采用生成的 anchor 取代 sliding window,AR (Average Recall) 已经可以超过普通 RPN 4 个点了,代价仅仅是增加两个 1x1 conv。

Feature Adaption
故事本可以就此结束,我们用生成的 anchor 和之前的特征图来进行 anchor 的分类和回归,涨点美滋滋。但是我们发现一个不合理的地方,大家都是同一层 conv 的特征,凭啥我就可以比别人优秀一些,代表一个又长又大的 anchor,你就只能代表一个小小的 anchor。
不合理的原因一方面在于,在同一层 conv 的不同位置,feature 的 receiptive field 是相同的,在原来的 RPN 里面,大家都表示相同形状的 anchor,所以相安无事,但是现在每个 anchor 都有自己独特的形状大小,和 feature 就不是特别好地 match。另一方面,对原本的特征图来说,它并不知道形状预测分支预测的 anchor 形状,但是接下来的分类和回归却是基于预测出的 anchor 来做的,可能会比较懵逼。
我们增加了一个 Feature Adaption 模块来解决这种问题。思路很简单,就是把 anchor 的形状信息直接融入到特征图中,这样新得到的特征图就可以去适应每个位置 anchor 的形状。我们利用一个 3x3 的 deformable convolution 来修正原始的特征图,而 deformable convolution 的 offset 是通过 anchor 的 w 和 h 经过一个 1x1 conv 得到的。(此处应该划重点,如果是像正常的 deformable convolution 一样,用特征图来预测 offset,则提升有限,因为没有起到根据 anchor 形状来 adapt 的效果)
通过这样的操作,达到了让 feature 的有效范围和 anchor 形状更加接近的目的,同一个 conv 的不同位置也可以代表不同形状大小的 anchor 了。从表格可以看到,Feature Adaption 还是很给力的,带来了接近 5 个点的提升。
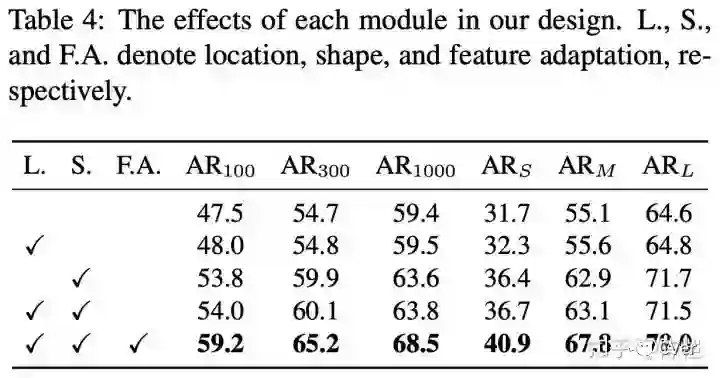
高质量 proposal 的正确打开方式
故事到这里其实也可以结束了,但是我们遇到了和之前一些改进 proposal 的 paper 里相同的问题,那就是 proposal 质量提升很多(如下图),但是在 detector 上性能提升比较有限。在不同的检测模型上,使用 Guided Anchoring 可以提升 1 个点左右。明明有很好的 proposal,但是 mAP 却没有涨很多,让人十分难受。
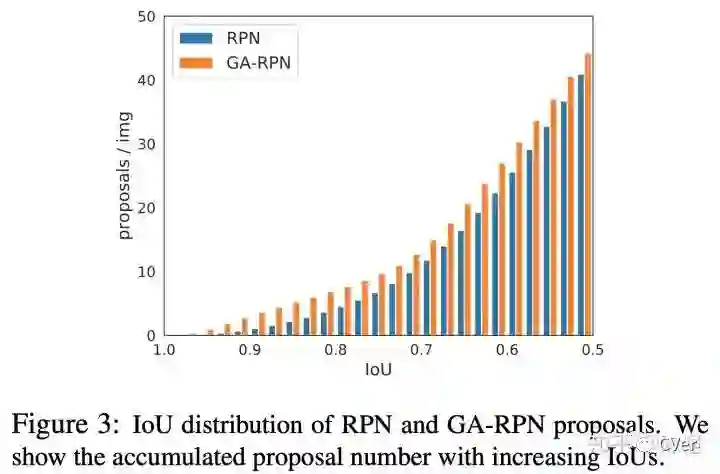
经过一番探究,我们发现了以下两点:1. 减少 proposal 数量,2. 增大训练时正样本的 IoU 阈值(这个更重要)。既然在 top300 里面已经有了很多高 IoU 的 proposal,那么何必用 1000 个框来训练和测试,既然 proposal 们都这么优秀,那么让 IoU 标准严格一些也未尝不可。
这个正确的打开方式基本是 Jiaqi 独立调出来的,让 performance 一下好看了很多。通过这两个改进,在 Faster R-CNN 上的涨点瞬间提升到了 2.7 个点(没有加任何 trick),其他方法上也有大幅提升。
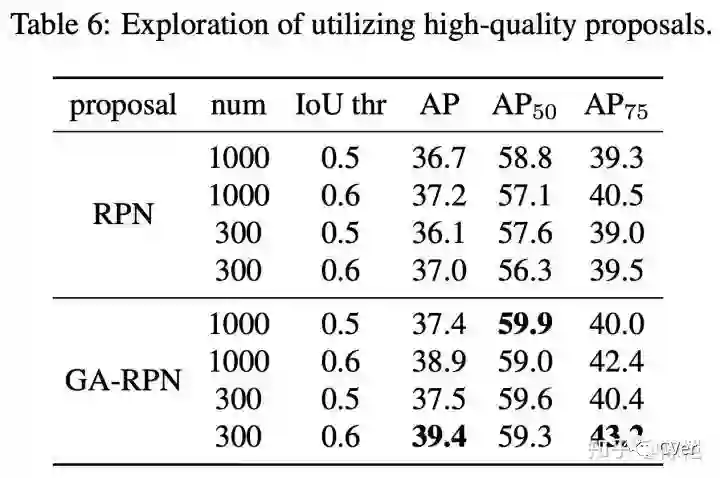
谈谈 anchor 设计准则
我们在 paper 里提到了 anchor 设计的两个准则,alignment(中心对齐) 和 consistency(特征一致)。其中 alignment 是指 anchor 的中心点要和 feature 的位置对齐,consistency 是指 anchor 的特征要和形状匹配。
Alignment
由于每个 anchor 都是由 feature map 上的一个点表示,那么这个 anchor 最好是以这个点为中心,否则位置偏了的话,这个点的 feature 和这个 anchor 就不是非常好地对应起来,用该 feature 来预测 anchor 的分类和回归会有问题。我们设计了类似 cascade/iterative RPN 的实验来证明这一点,对 anchor 进行两次回归,第一次回归采用常规做法,即中心点和长宽都进行回归,这样第一次回归之后,anchor 中心点和 feature map 每一个像素的中心就不再完全对齐。我们发现这样的两次 regress 提升十分有限。所以我们在形状预测分支只对 w 和 h 做预测,而不回归中心点位置。
Consistency
这条准则是我们设计 feature adaption 的初衷,由于每个位置 anchor 形状不同而破坏了特征的一致性,我们需要通过 feature adaption 来进行修正。这条准则本质上是对于如何准确提取 anchor 特征的讨论。对于两阶段检测器的第二阶段,我们可以通过 RoI Pooling 或者 RoI Align 来精确地提取 RoI 的特征。但是对于 RPN 或者单阶段检测器的 anchor 来说,由于数量巨大,我们不可能通过这种 heavy 的方法来实现特征和框的精确 match,还是只能用特征图上一个点,也就是 512x1x1 的向量来表示。那么 Feature Adaption 起到了一个让特征和 anchor 对应更加精确的作用,这种设计在其他地方也有可以借鉴之处。
总结
在 anchor 设计中,alignment 和 consistency 这两个准则十分重要。
采用两个 branch 分别预测 anchor 的位置和形状,不需要预先定义。
利用 anchor 形状来 adapt 特征图。
高质量 proposal 可以使用更少的数量和更高的 IoU 进行训练。
即插即用,无缝替换。
关于 code
预计在三月底或者四月的某个时候 release 在 mmdetection里,欢迎 watch。
https://github.com/open-mmlab/mmdetection
广告一下,我们已经公开(Guided Anchoring,Hybrid Task Cascade),或者还没挂 arxiv(打码,打码),以及正在研究(打码,打码)的算法,代码都会陆续在 mmdetection 开源。十分欢迎物体检测、实例分割算法的作者们使用这个 codebase 复现自己的算法并提交 PR,共同维护一个可复现,高质量的 benchmark。
https://arxiv.org/abs/1901.03278
想要了解最新最快最好的论文速递、开源项目和干货资料,欢迎加入CVer学术交流群。涉及图像分类、目标检测、图像分割、人脸检测&识别、目标跟踪、GANs、学术竞赛交流、Re-ID、风格迁移、医学影像分析、姿态估计、OCR、SLAM、场景文字检测&识别和超分辨率等方向。

扫码进群
这么硬的论文速递,麻烦给我一个好看

▲长按关注我们
麻烦给我一个好看!