指数级加速架构搜索:CMU提出基于梯度下降的可微架构搜索方法

作者:刘寒骁、Karen Simonyan、杨一鸣
来源:arXiv、机器之心
研究者称,该方法已被证明在卷积神经网络和循环神经网络上都可以获得业内最优的效果,而所用 GPU 算力有时甚至仅为此前搜索方法的 700 分之 1,这意味着单块 GPU 也可以完成任务。该研究的论文《DARTS: Differentiable Architecture Search》一经发出便引起了 Andrew Karpathy、Oriol Vinyals 等学者的关注。
DARTS 代码: https://github.com/quark0/darts
引言
发现最优的神经网络架构需要人类专家耗费大量精力才能实现。近来,人们对开发算法来解决架构设计过程的自动化问题产生了兴趣。自动化的架构搜索已经在诸如图像分类和目标检测这样的任务中获得了非常有竞争力的性能。
当前最佳的架构搜索算法尽管性能优越,但需要很高的计算开销。例如,在 CIFAR-10 和 ImageNet 上获得当前最佳架构需要强化学习的 1800 个 GPU 工作天数 (Zoph et al., 2017) 或进化算法的 3150 个 GPU 工作天数(Real et al., 2018)。人们已经提出了很多加速方法,例如为搜索空间强加特定的结构(Liu et al., 2017b,a),为每个单独架构强加权重或性能预测(Brock et al., 2017; Baker et al., 2018)以及在多个架构之间共享权重(Pham et al., 2018b; Cai et al., 2018),但可扩展性的基本挑战仍然存在。主要方法(例如基于强化学习、进化算法、MCTS(Negrinho and Gordon, 2017)、SMBO(Liu et al., 2017a)或贝叶斯优化(Kandasamy et al., 2018))低效性的一个内部原因是,架构搜索被当成一种在离散域上的黑箱优化问题,这导致需要大量的架构评估。
在这项研究中,我们从一个不同的角度来解决这个问题,并提出了一个高效架构搜索方法 DARTS(可微架构搜索)。该方法不同于之前在候选架构的离散集上搜索的方式,而是将搜索空间松弛为连续的,从而架构可以通过梯度下降并根据在验证集上的表现进行优化。与基于梯度优化的数据有效性和低效的黑箱搜索相反,它允许 DARTS 使用少几个数量级的计算资源达到和当前最佳性能有竞争力的结果。它还超越了其它近期的高效架构搜索方法 ENAS(Pham et al., 2018b)。值得注意的是,DARTS 比很多已有的方法都简单,因为它并不涉及任何控制器(Zoph and Le, 2016; Baker et al., 2016; Zoph et al., 2017; Pham et al., 2018b)、超网络(Brock et al., 2017)或性能预测器(Liu et al., 2017a),然而它也能足够通用地搜索卷积和循环架构。
在连续域中搜索架构的概念并不新鲜(Saxena 和 Verbeek,2016;Ahmed 和 Torresani,2017;Shin 等,2018),但有几个主要区别。尽管先前的工作试图微调架构的特定方面,例如卷积网络中的滤波器形状或分支模式,但 DARTS 能够在丰富的搜索空间中发现具有复杂图形拓扑的高性能架构。此外,DARTS 并不限于任何特定的架构族,且能够搜索卷积网络和循环网络。
实验证明 DARTS 设计的卷积单元可在 CIFAR-10 上获得 2.83 ± 0.06% 的测试误差,与使用正则化进化方法(Real et al., 2018)的当前最优结果不相上下,而后者使用的计算资源高于前者三个数量级。同样的卷积单元迁移至 ImageNet(移动端)后也得到了 26.9% 的 top-1 误差,与最优强化学习方法(Zoph et al., 2017)旗鼓相当。在语言建模任务上,DARTS 发现的循环单元在单个 GPU 工作天数的训练时间中即在 PTB 上获得了 56.1 的困惑度(perplexity),优于大规模调参的 LSTM(Melis et al., 2017)和基于 NAS(Zoph and Le, 2016)与 ENAS(Pham et al., 2018b)的所有现有自动搜索单元。
本论文的贡献如下:
介绍了一种新型算法用于可微网络架构搜索,该算法适用于卷积架构和循环架构。
在图像分类和语言建模任务上进行的大量实验表明:基于梯度的架构搜索在 CIFAR-10 上获得了极具竞争力的结果,在 PTB 上的性能优于之前最优的结果。这个结果非常有趣,要知道目前最好的架构搜索方法使用的是不可微搜索方法,如基于强化学习(Zoph et al., 2017)或进化(Real et al., 2018; Liu et al., 2017b)的方法。
达到了优秀的架构搜索效率(使用 4 块 GPU:经过 1 天训练之后在 CIFAR-10 上达到了 2.83% 的误差;经过六小时训练后在 PTB 达到了 56.1 的困惑度,研究者将其归功于基于梯度的优化方法)。
展示了 DARTS 在 CIFAR-10 和 PTB 上学到的架构分别可迁移至 ImageNet 和 WikiText-2。
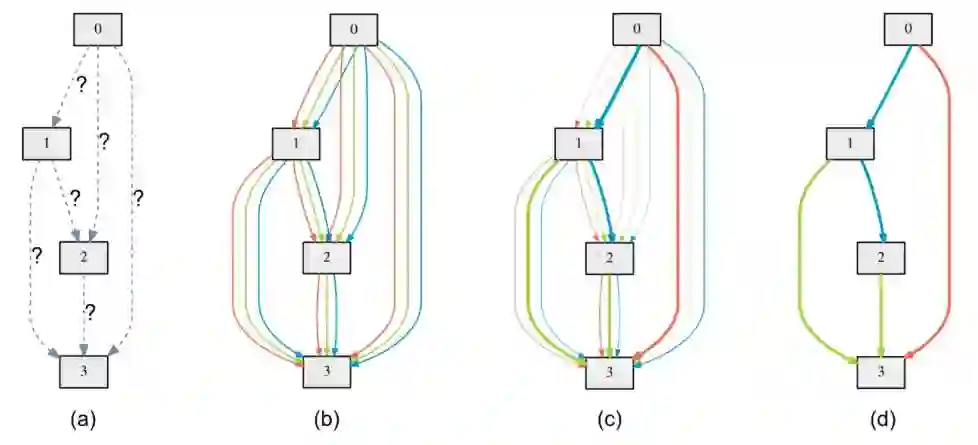
图 1:DARTS 概述:(a)一开始并不知道对边缘的操作。(b)通过在每个边缘放置各种候选操作来连续放宽搜索空间。(c)通过求解二级(bilevel)优化问题,联合优化混合概率和网络权重。(d)从学习到的混合概率中归纳出最终的架构。
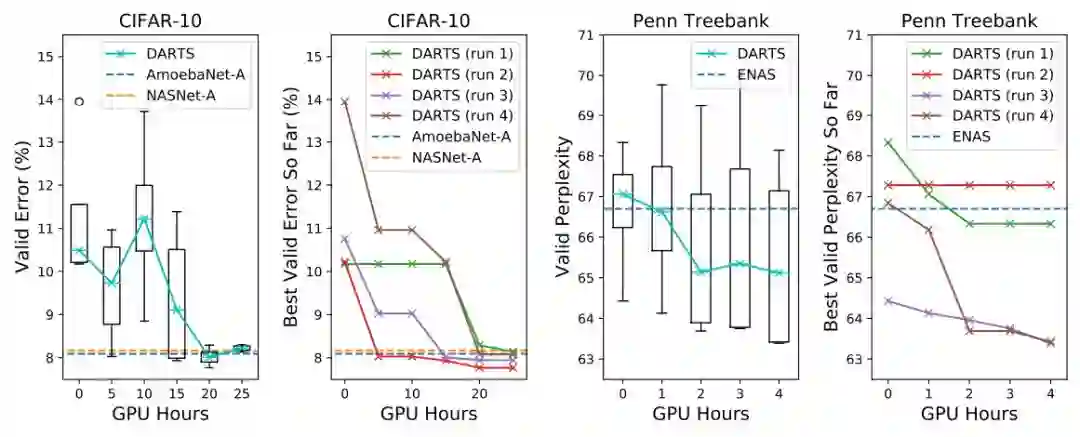
图 3:CIFAR-10 卷积单元和 Penn Treebank 循环单元的 DARTS 搜索进展。随着时间的推移,该方法会持续追踪最新的架构。每个架构的瞬象(snapshot)都使用训练集从头开始重新训练(CIFAR-10 上的 100 个 epoch 和 PTB 上的 300 个 epoch),然后在验证集上进行评估。对于每个任务,我们用不同的随机种子重复实验 4 次,并随着时间的推移报告架构每次运行的中值和最佳验证性能。作为参考,我们还报告了(在相同的评估设置下;具有可比较数量的参数)通过进化或使用强化学习发现的最佳已有单元的结果,包括 NASNet-A(Zoph 等,2017)(1800 个 GPU 工作天数),AmoebaNet-A(3150 个 GPU 工作天数)(Real 等,2018)和 ENAS(0.5 个 GPU 工作天数)(Pham 等,2018b)。
架构评估
为了选择要评估的架构,研究者使用不同的随机种子运行了四次 DARTS,基于验证性能选择了最好的单元。这对循环单元来说尤其重要,因为优化结果与初始化有较大关联(图 3)。
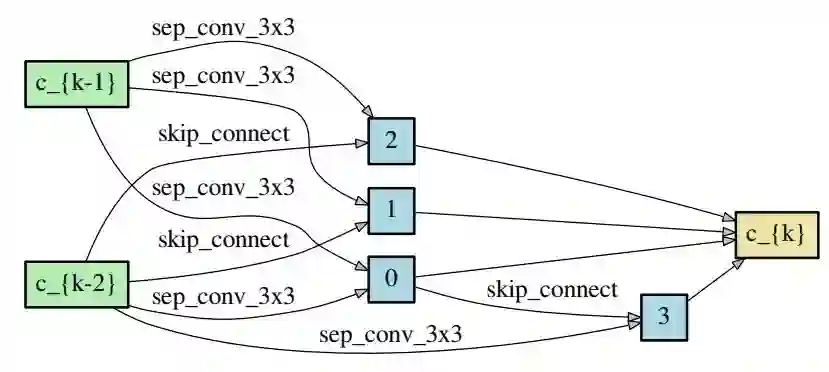
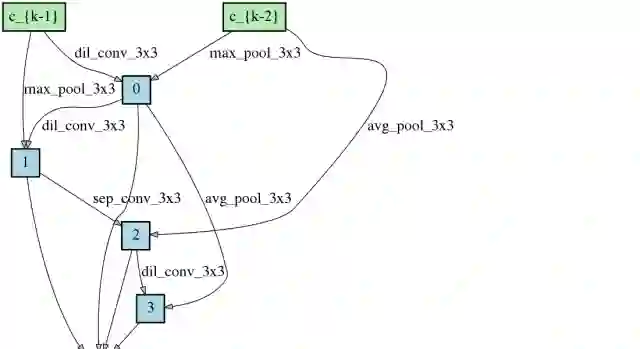
图 4:在 CIFAR-10 上习得的 normal 单元。
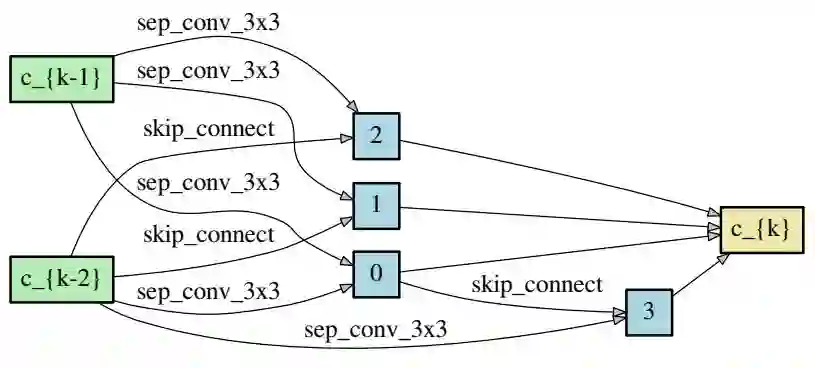
图 5:在 CIFAR-10 上习得的 reduction 单元。
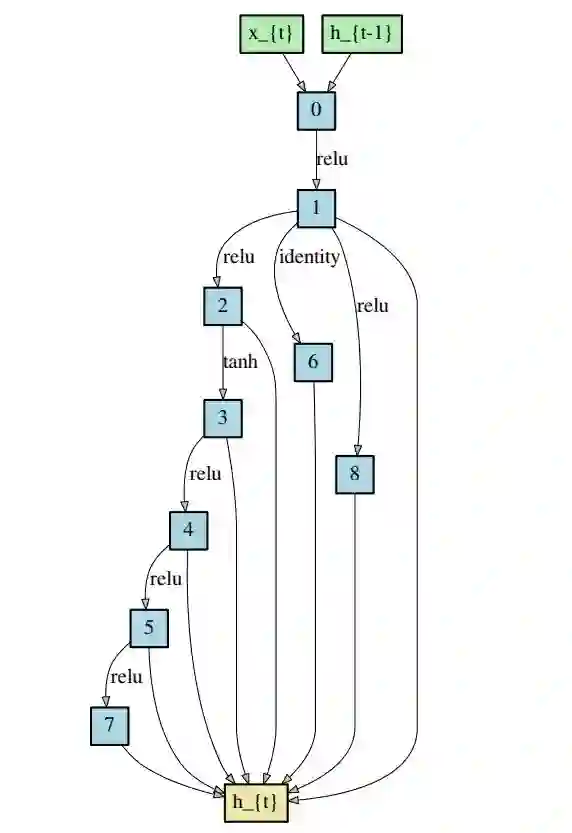
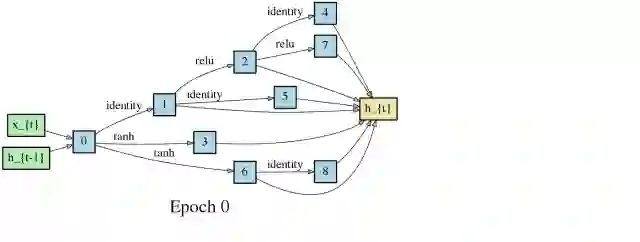
图 6:在 PTB 上得习的循环单元。
为了评估选择的架构,研究者对架构权重进行随机初始化(在搜索过程中习得的权重被丢弃),从头训练架构,并在测试集上测试其性能。测试集未用于架构搜索或架构选择。
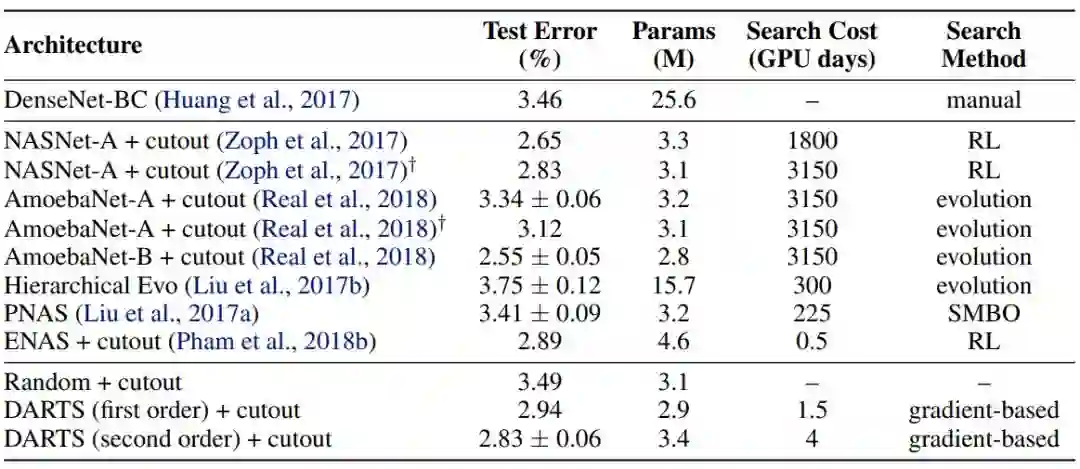
表 1:当前最优图像分类器在 CIFAR-10 上的对比结果。带有 † 标记的结果是使用本论文设置训练对应架构所得到的结果。
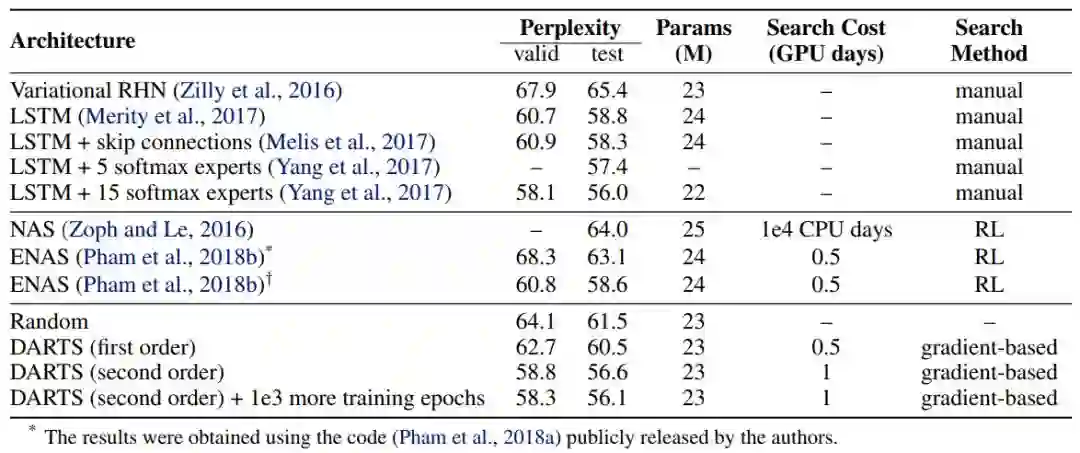
表 2:当前最优语言模型在 Penn Treebank 上的对比结果。带有 † 标记的结果是使用本论文设置训练对应架构所得到的结果。
论文:DARTS: Differentiable Architecture Search

论文链接:https://arxiv.org/abs/1806.09055
摘要:本论文用可微的方式重构架构搜索任务,解决了该任务的可扩展性难题。与在离散和不可微搜索空间中使用进化算法或强化学习的传统方法不同,我们的方法基于架构表征的连续松弛,利用梯度下降实现架构的高效搜索。我们在 CIFAR-10、ImageNet、Penn Treebank 和 WikiText-2 上进行了大量实验,结果表明我们的算法在发现高性能的图像分类卷积架构和语言建模循环架构中表现优异,且该算法的速度比之前最优的不可微方法快了几个数量级。
- 加入AI学院学习 -

点击“ 阅读原文 ”进入学习


