清华构建新一代数据集NICO,定义图像分类新标准

 相对I.I.D.假设下的模型学习,这种训练环境和测试环境的数据分布不同的问题称为Non-I.I.D.或者OOD(Out-of-Distribution)。
相对I.I.D.假设下的模型学习,这种训练环境和测试环境的数据分布不同的问题称为Non-I.I.D.或者OOD(Out-of-Distribution)。

区别于I.I.D.下传统图像任务的定义,Non-I.I.D.把“跨数据集泛化性”作为主要的评价标准。以基本的图像分类任务为例,Non-I.I.D.下的图像分类分为Targeted类和General类。两类任务的区别在于是否已知测试环境的信息,目标都是从训练环境中学习可以泛化到有数据分布偏差的测试环境的模型。显然,随着不同类型、任务、规模的数据集不断提出,单单通过排列组合来考察“跨数据集泛化性”带来的边际效应越来越低,从实际研究的⻆度出发,整个研究社区亟需⼀个可以系统、定量地研究数据分布偏差与模型泛化性能的标杆数据集。

 区别于其它标准数据集,构建NICO数据集的核心思想是以(主体对象,上下文)的组合为单位收集数据。同一个类别(主体对象),有多个上下文与之对应,描述主体内的属性,如颜色、形状等,或主体外的背景,如草地、日落等。为了实用性和适用性,我们从搜索引擎上与主体最密切的联想词中筛选出丰富多样的上下文,并保证不同主体的上下文有足够的重叠度。上下文实际上提供了围绕主体的有偏数据分布,通过在训练环境和测试环境组合不同的(主体对象,上下文),我们就能构建不同的Non-I.I.D.场景。可以构建的场景包括但不限于:
区别于其它标准数据集,构建NICO数据集的核心思想是以(主体对象,上下文)的组合为单位收集数据。同一个类别(主体对象),有多个上下文与之对应,描述主体内的属性,如颜色、形状等,或主体外的背景,如草地、日落等。为了实用性和适用性,我们从搜索引擎上与主体最密切的联想词中筛选出丰富多样的上下文,并保证不同主体的上下文有足够的重叠度。上下文实际上提供了围绕主体的有偏数据分布,通过在训练环境和测试环境组合不同的(主体对象,上下文),我们就能构建不同的Non-I.I.D.场景。可以构建的场景包括但不限于:
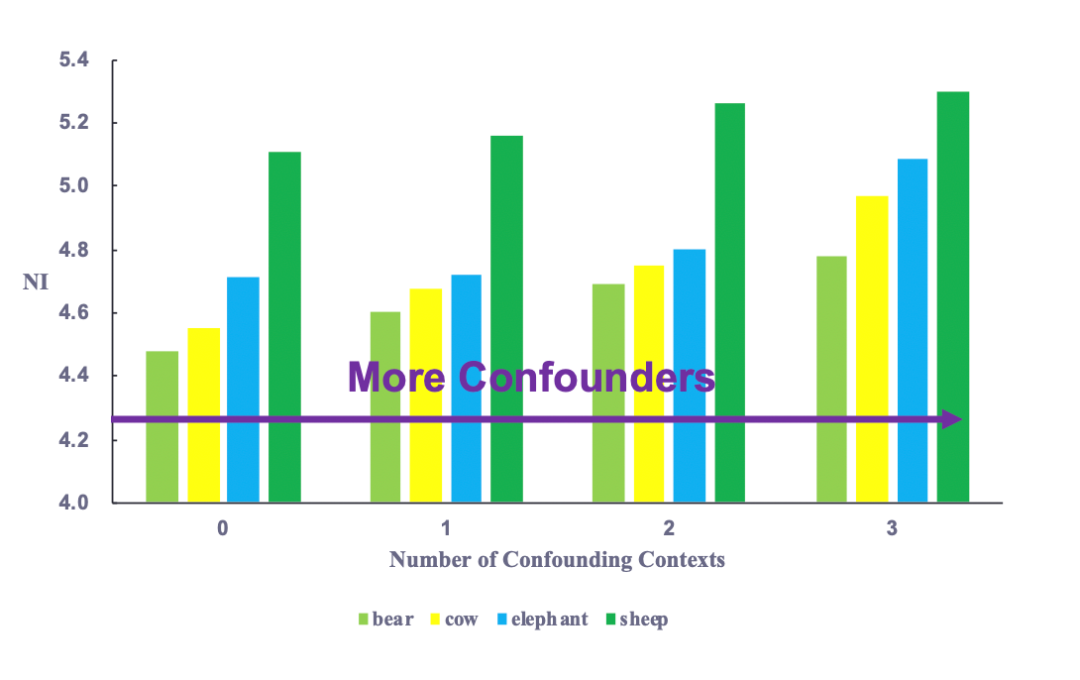
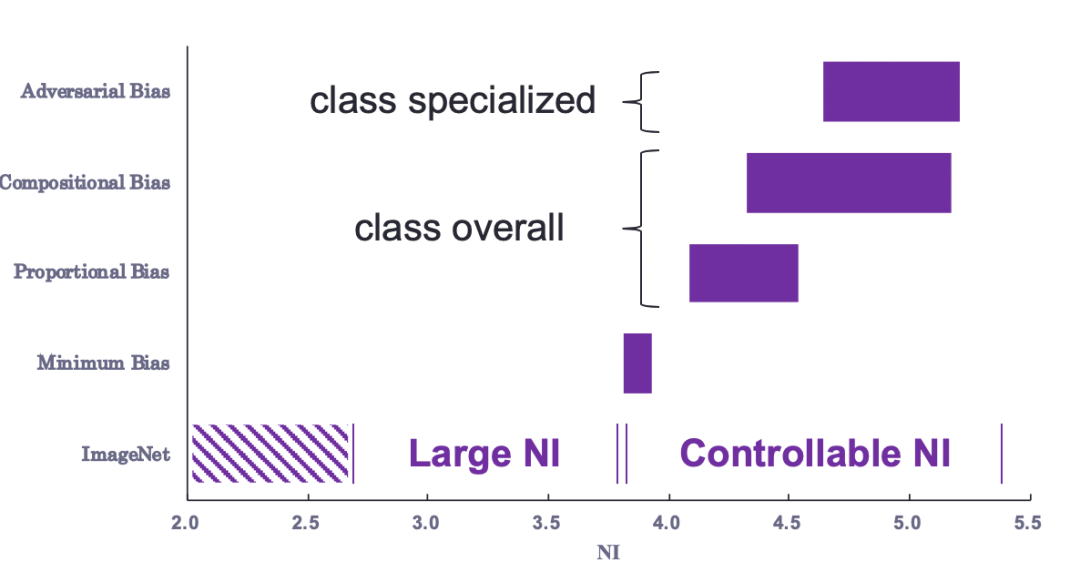
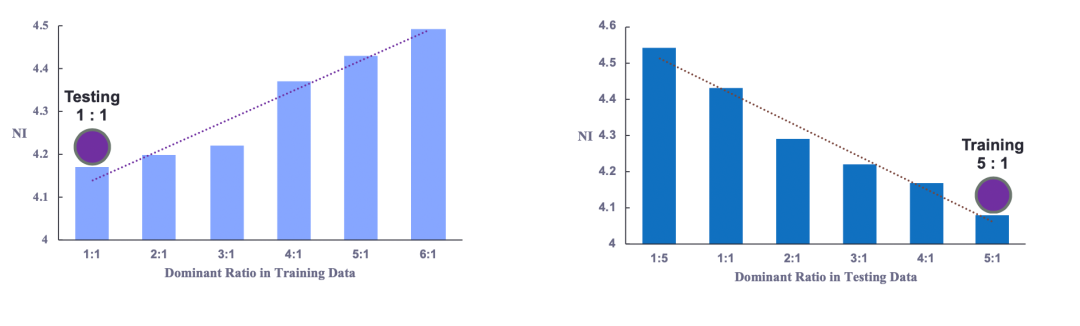 3、成份偏差:
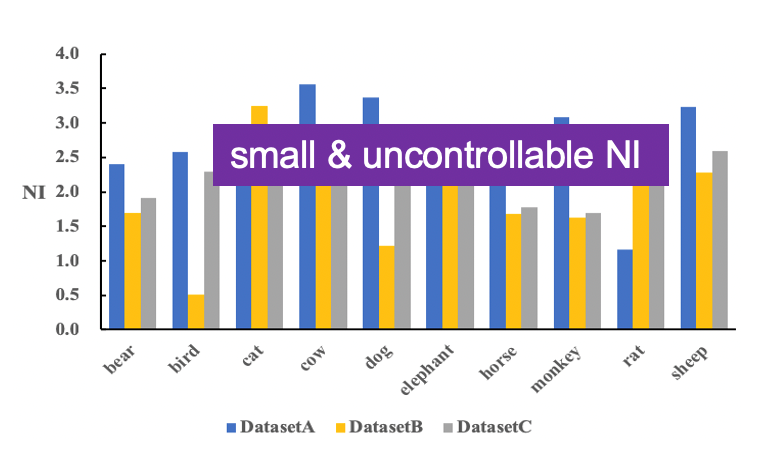
测试环境中存在训练环境中没出现过的(主体对象,上下文)单元,算作比例偏差的一个特例。成分偏差考验了模型对外插数据的泛化能力,没见过的上下文组合越多,数据分布差异越大,也就越难学。我们还可以在训练集中对不同类别再次设置主导的上下文,进一步增加分布差异。
3、成份偏差:
测试环境中存在训练环境中没出现过的(主体对象,上下文)单元,算作比例偏差的一个特例。成分偏差考验了模型对外插数据的泛化能力,没见过的上下文组合越多,数据分布差异越大,也就越难学。我们还可以在训练集中对不同类别再次设置主导的上下文,进一步增加分布差异。
一、新一代数据集应该是怎样的标准?
1、ImageNet开启了数据集的黄金时代。在ImageNet之后的各种数据集通常都会在哪些方面做到差别化?
差异化体现在数据集的建立初衷、目标问题、适用场景;以及样本提供的不同信息,比如标签、上下文等。
2、新一代数据集是任务通用的吗还是分任务进行分门别类构建?
一般会先以某些任务为目标构建起来;然后随着数据集的发展丰富,以及研究人员的灵活使用,逐渐通用。
3、新一代数据集是考虑加入因果关系吗?该怎么加?
数据集本身是不考虑因果关系的,但可以通过构造有数据分布偏差的训练和测试集,支持因果的研究,比如NICO可以在训练环境和测试环境组合不同的(主体对象,上下文)单元。
4、如果是检测任务,背景的影响还有那么重要吗?
对于检测任务,图像的背景对模型性能的影响较小; 但是 NICO 的上下文不仅包括背景,还包括主体对象的属性,比如色彩、动作等,其带来的分布差异也会影响模型。
二、针对NICO数据集本身的问题
1、NICO数据集建立的初衷是什么?相比传统数据集有什么优势?
NICO数据集建立的初衷是吸引更多机器学习的研究者关注智能认知的本质机理。这样的机理将更接近人类智慧的习惯(比如因果),因此具备跨环境的稳定性和鲁棒性。为了支持以上研究,区别于传统数据集,NICO的图像样本除了主体类别标签,还有唯一的上下文信息描述主体的属性或者背景,通过在训练环境和测试环境中以不同比例组合不同的(主体对象,上下文)单元,可以灵活方便地构造数据环境模拟不同的Non-I.I.D.场景(见补充材料),支持对智能认知的本质机理的研究。
2、NICO数据集只适用于CV中的识别分类任务吗?
识别分类任务是当前NICO中设立的标准任务,但NICO不限于识别分类任务,研究人员可以利用上下文信息自行设计更多有意思的任务;另外,我们后续对NICO的优化和补充可能会细化上下文或者提供更多的图像标注,进而孵化出更多的任务。
3、如果是检测任务,背景的影响还有那么重要吗?
对于检测任务,图像的背景对模型性能的影响较小;但是NICO的上下文不仅包括背景,还包括主体对象的属性,比如色彩、动作等,其带来的分布差异也会影响模型。
4、数据集具体怎么收集构建的?
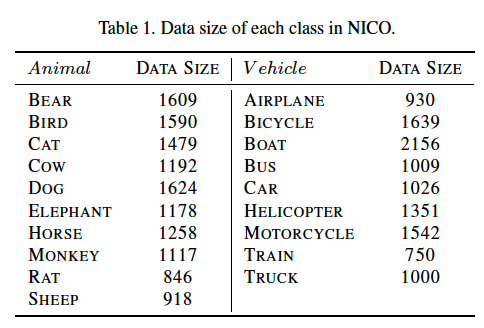
参照几个公认的图像数据集,我们确定了动物和交通工具两个超类,并选择了共 19 个常见的类别,如猫、火车等; 对于每个类别,我们先基于搜索引擎( YFCC100m )划定了频率最高的联想词的范围,然后把同时和多个类别相关的词作为上下文; 确定了(主体对象,上下文)的组合后,我们从搜索引擎上收集图像,多次检测完成过滤去噪的工作。
5、估计NICO数据集大概多大规模才能有效解决识别问题?
目前NICO的规模已经可以支持从头训练(不带预训练)一个深度网络模型(如 ResNet18),而且会不断扩大,足以支持对有效解决识别问题的算法的研究。
6、动物类的数据集中,为什么要收集吃、躺、颜色等非背景属性,有什么考虑?
选择NICO的上下文的时候,我们特别注意收集搜索引擎上与主体对象出现频率最高的联想词,这样可以保证每个(主体对象,上下文)都能收集到足够多的数据样本,保持数据集的规模,适应不同的实验设定。
7、有些不同标签的图像场景存在重叠,比如狗吃饭的时候也可能在家,这种重叠有什么影响?
我们特意保证不同主体的上下文之间有所交叉,这样可以更好地适应不同的实验设定,让研究人员更灵活方便地设计实验,详情请见NICO支持的典型场景部分。
8、后续NICO数据集还会有什么样的计划?
后续NICO会进一步增加数据集的规模,包括类别、上下文的种类、数据量,提高图像质量、进一步去噪过滤,并尝试细化上下文或者提供更多的图像标注。
三、目前利用NICO数据集做了哪些任务,有没有一套完整的流程,包括定义明确的指标、实际运行、结果。
请参见我们提供的补充材料,我们明确了几个NICO支持的经典的Non-I.I.D.场景,评价Non-I.I.D.程度的指标,以及指标下如何调节不同场景的Non-I.I.D.程度。
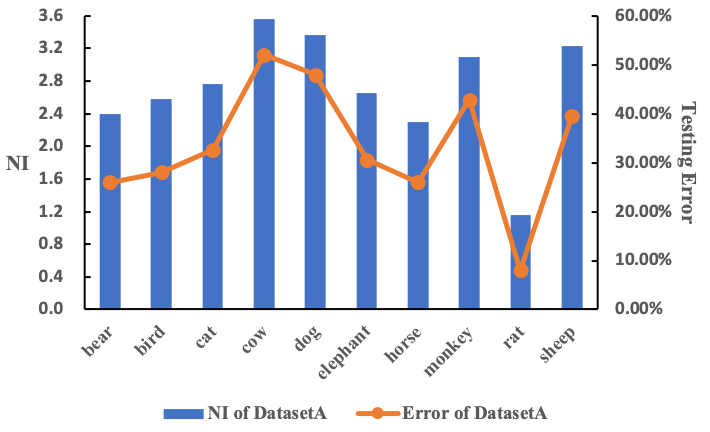
我们还在一些场景里,基于一个类似AlexNet的CNN结构,进行了图像分类问题的实验研究。实验结果说明,Non-I.I.D.对一般CNN结构的泛化能力的影响很大,说明传统CNN并不完全符合人类的智能认知。一个简单的causal模块(global balancing,CNBB)可以提升泛化能力。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
可 以考虑把一整个大数据集拆分成有重叠度的多个小数据集,借助社区的开源力量或者众包的方式,标注和构建数据集。
借助社区的开源力量。