点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达![]()
本文转载自:将门创投
众所周知,参加顶会竞赛是当今AI研究人员锻炼自身、验证已有学术成果的一大舞台。
从2017年到现在,旷视研究院在全球顶会累计荣获28项世界冠军,好奇的同学们肯定想知道其中的经验与技巧。
为此我们很荣幸邀请到
旷视南京研究院研究员—
赵冰辰
,与大家分享其团队在
CVPR 2020 iWildCam
项目夺冠的经历,同时也介绍了他们在本次比赛中针对 Camera Trap 数据的特点设计的方法及冠军方案。
![]() 复制www.techbeat.net 至浏览器中,在搜索框中搜索“赵冰辰”或在最新上架中找到它!️
复制www.techbeat.net 至浏览器中,在搜索框中搜索“赵冰辰”或在最新上架中找到它!️
值得一提的是,虽然旷视南京研究院在整个参赛过程中持续领先,但就在最终截止日期前5天,Facebook突然大比分反超。
经过对现有模型的快速分析,团队通过序列和日期信息大幅提升了模型性能近10个点,在48小时内重新登顶,并夺得iWildCam的全球冠军。
本文回顾了此次比赛的
基本背景
、
团队方案
,并介绍了团队总结的
参赛经验
,希望能为同学们带来启发。
iWildCam竞赛隶属于
CVPR 2020 FGVC workshop
, 其目的是利用部署在野外无人操纵的 Camera Trap 来识别野生动物,从而辅助对野生动物的研究与保护。该比赛的难点在于,
由于 Camera Trap 的拍摄机制是通过热感或运动来触发相机,因此成像效果与ImageNet或者是iNaturalist中的图像有很大区别
。
![]() 一个典型的camera trap设备
例如下图,每张图片中都存在动物,但是由于 camera trap
无人操纵
的特性,获取的画面会受到光照、模糊、小ROI、遮挡、奇异视角、或者动物本身保护色等诸多因素的干扰。 可以发现,
定位到这些动物并且给出正确分类,即使对人类来说也比较困难。
Camera Trap数据的另外一个特点在于
画面背景
。
由于camera trap固定在某个区域进行拍摄,因此由特定camera trap所采集到的图片背景相似度极高。
如下图,Camera-1和Camera-2分别对应部署在两个位置的camera trap,可以发现同一个camera拍到的图片背景基本一致。而相应的,不同camera获取的背景差异显著。
因此,这对
分类模型的泛化性
提出了极高的要求。iWildCam数据集总共包括263个类别,28万张图片,其中训练集441个camera trap,测试集111个camera trap。主办方将全部552个位置的camera trap分成为train set 441个,和test set 111个,这也就是说
测试集图片全部来自训练集之外的camera trap
。
另外,
类别
数据的长尾分布
也是必须考虑的问题。
因此可以总结,在Camera Trap场景下,主要存在三个问题:
一个典型的camera trap设备
例如下图,每张图片中都存在动物,但是由于 camera trap
无人操纵
的特性,获取的画面会受到光照、模糊、小ROI、遮挡、奇异视角、或者动物本身保护色等诸多因素的干扰。 可以发现,
定位到这些动物并且给出正确分类,即使对人类来说也比较困难。
Camera Trap数据的另外一个特点在于
画面背景
。
由于camera trap固定在某个区域进行拍摄,因此由特定camera trap所采集到的图片背景相似度极高。
如下图,Camera-1和Camera-2分别对应部署在两个位置的camera trap,可以发现同一个camera拍到的图片背景基本一致。而相应的,不同camera获取的背景差异显著。
因此,这对
分类模型的泛化性
提出了极高的要求。iWildCam数据集总共包括263个类别,28万张图片,其中训练集441个camera trap,测试集111个camera trap。主办方将全部552个位置的camera trap分成为train set 441个,和test set 111个,这也就是说
测试集图片全部来自训练集之外的camera trap
。
另外,
类别
数据的长尾分布
也是必须考虑的问题。
因此可以总结,在Camera Trap场景下,主要存在三个问题:
-
Camera Trap无人操作导致的图像模糊,遮挡等问题。
-
-
针对上述问题,旷视南京研究院在此次参赛中进行了逐项攻克。
如前所述,iWildCam的第一个挑战来自于
camera trap所捕获的画面,即动物图片经常存在过小或者被遮挡
等问题。 因此比赛主办方提供了
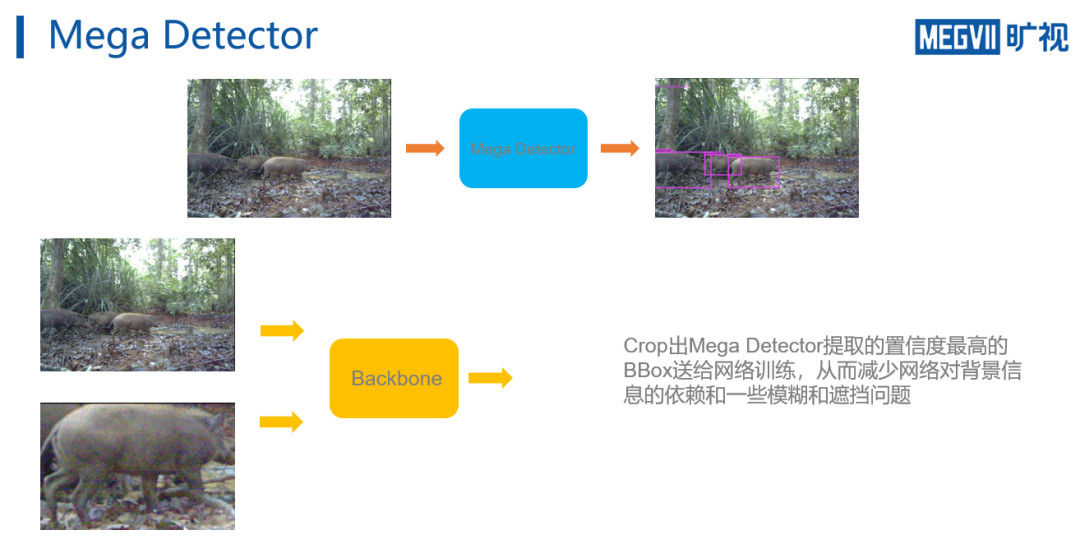
Mega Detector
(一个微软提供的Camera Trap动物检测器,输出类别只有animal和background)。
因此,旷视南京研究院用Mega Detector来提取图像的ROI区域,从辅助进一步的分类工作。
一种简单的利用方式是将Mega Detector预测的BBox 裁剪出来,同原图一起送给网络进行训练,这样可以有效环节ROI 尺寸过小的问题。
不过这种方案的缺陷在于,如此训练分类网络,
会使得网络获得两个scale完全不同的输入,一个是原图,一个是BBox裁剪出的图像,这会对分类网络学习特征带来一定的干扰。
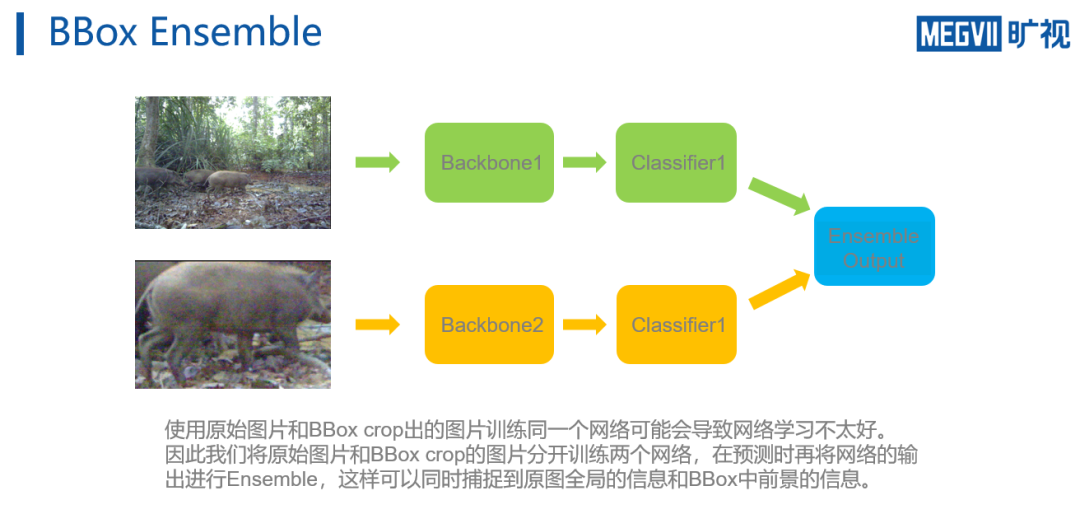
为此,团队修改了策略,
同时训练两个网络
。
分别输入原始图像,和Mega detector裁剪出的置信度最高的bbox图像。
在预测阶段,再将网络的输出进行Ensemble,从而可以同时捕捉到原图全局的信息和BBox中前景的信息。
除过ROI 储存过小之外,另一个问题是
训练集的camera trap 取景位置和测试集的camera trap 不相交所导致的背景差异问题
。
![]() 训练集图片均来自于蓝色点表示的区域,它和红色区域没有相交。
因此这会造成
domain shift
的问题。即
在训练地表现好的模型并不一定也会在test地有同样表现
。因为模型有可能学到一些和location相关的信息,而它们不是可以用于分类动物的通用信息。
此外,与正常的domain adaptation不同,
iWildCam 的训练集包括很多不同domain
(如果将每个camera trap地点作为一个domain,则训练集包含441个,而测试集包含111个)。
因此,如果能利用训练集中的位置标注来帮助网络学习location invariant的特征,那么网络就可捕捉更多与位置无关而和分类相关的信息。
对此,domain adaptation领域非常著名的论文
Unsupervised domain adaption by backpropagation
为团队提供了启发。
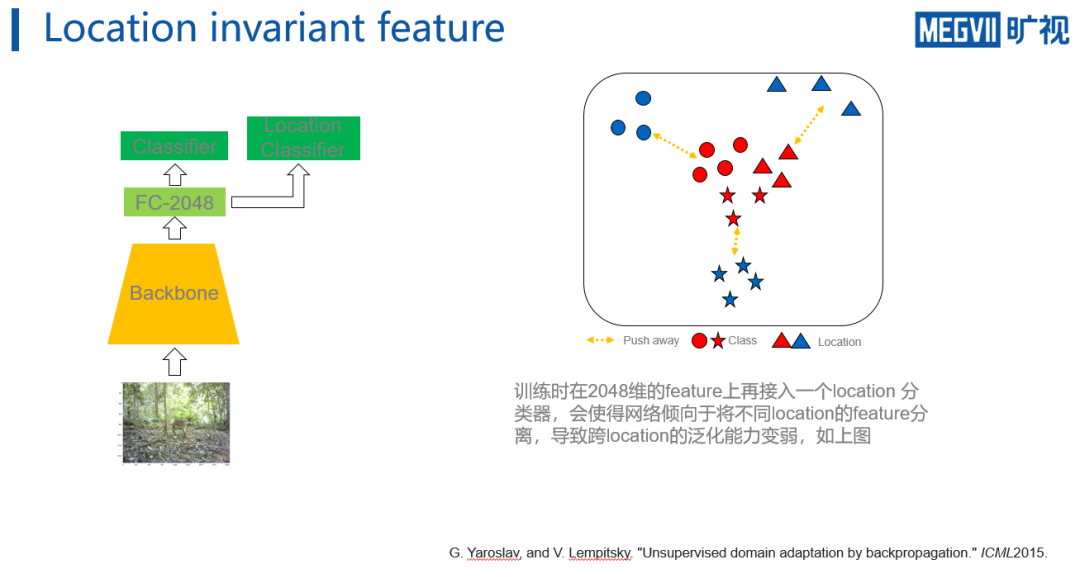
如上图首先可以假
设,如果在原来的2048维上加一个额外位置(location)的classifier,那么网络提取的特征就会倾向于将不同location的特征相互推远。如上方右图所示(不同形状表示不同类别,不同颜色表示不同)
,虽然每个类别的特征之间有分类的可分性约束,但是location之间的相互排斥也会导致一些location图片的特征被推到一个不太有利于分类的局面,从而导致网络学到的特征并不能实现location invariant,从而在测试集上表现欠佳。
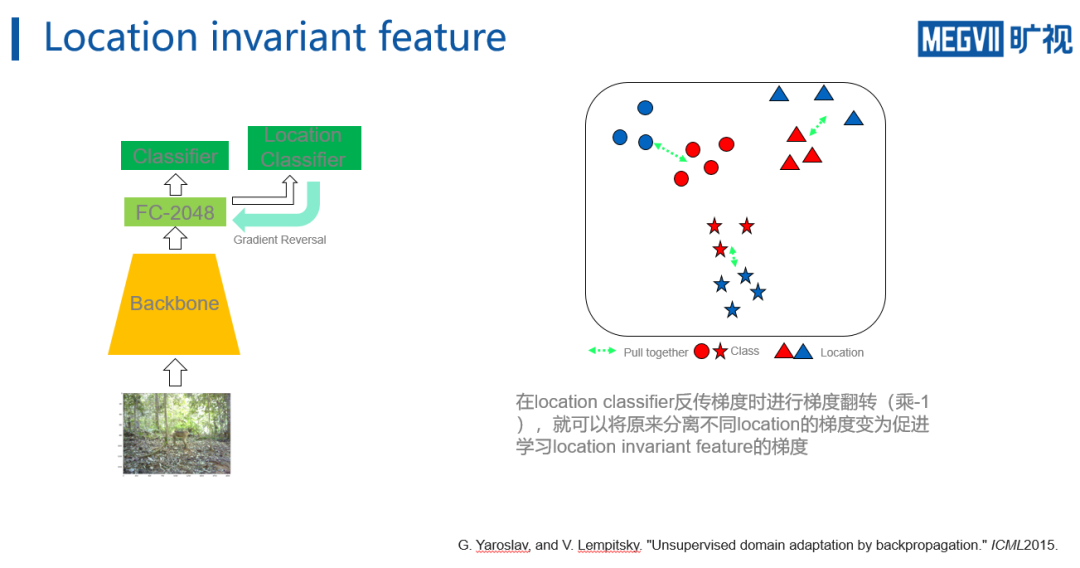
对此,文章提出一个非常简单的
梯度翻转
的技巧来实现location invariant。
如上方左图所示,在梯度反传经过location classifier时将梯度乘-1,从而实现翻转梯度的方向。
因此在右图可以看到,
原本的推开不同location之间特征的梯度经过翻转后,会将其一起拉近
。
在加上分类的约束后,可以保证网络学到的特征表示实现location invariant,并且还能保证分类的效果,提高网络对之前未见的location的泛化性能。
训练集图片均来自于蓝色点表示的区域,它和红色区域没有相交。
因此这会造成
domain shift
的问题。即
在训练地表现好的模型并不一定也会在test地有同样表现
。因为模型有可能学到一些和location相关的信息,而它们不是可以用于分类动物的通用信息。
此外,与正常的domain adaptation不同,
iWildCam 的训练集包括很多不同domain
(如果将每个camera trap地点作为一个domain,则训练集包含441个,而测试集包含111个)。
因此,如果能利用训练集中的位置标注来帮助网络学习location invariant的特征,那么网络就可捕捉更多与位置无关而和分类相关的信息。
对此,domain adaptation领域非常著名的论文
Unsupervised domain adaption by backpropagation
为团队提供了启发。
如上图首先可以假
设,如果在原来的2048维上加一个额外位置(location)的classifier,那么网络提取的特征就会倾向于将不同location的特征相互推远。如上方右图所示(不同形状表示不同类别,不同颜色表示不同)
,虽然每个类别的特征之间有分类的可分性约束,但是location之间的相互排斥也会导致一些location图片的特征被推到一个不太有利于分类的局面,从而导致网络学到的特征并不能实现location invariant,从而在测试集上表现欠佳。
对此,文章提出一个非常简单的
梯度翻转
的技巧来实现location invariant。
如上方左图所示,在梯度反传经过location classifier时将梯度乘-1,从而实现翻转梯度的方向。
因此在右图可以看到,
原本的推开不同location之间特征的梯度经过翻转后,会将其一起拉近
。
在加上分类的约束后,可以保证网络学到的特征表示实现location invariant,并且还能保证分类的效果,提高网络对之前未见的location的泛化性能。
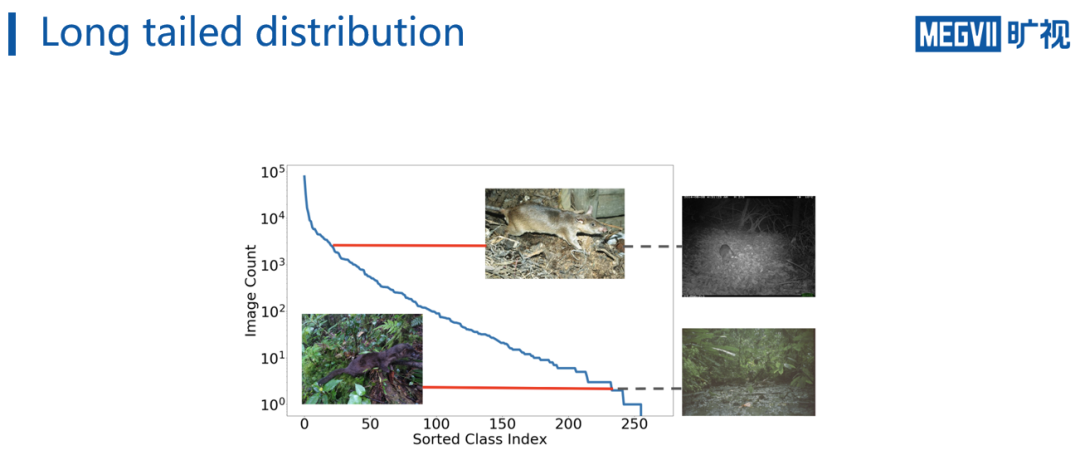
上方指数图展示的
是数据的分布情况,可以
看到数目最多的类别有超过十万张图,而最少的类别可能只有不到十张图片,一般而言,将类别数多的类别称为
head类
,类别数少的类别称为
tail类
。
因此,如果直接随机采样batch来训练分类模型,会见到很多head类样本,而tail类样本则很少见到,这样会使得模型更偏向于预测head类而不是tail类,从而损伤网络的表示能力。
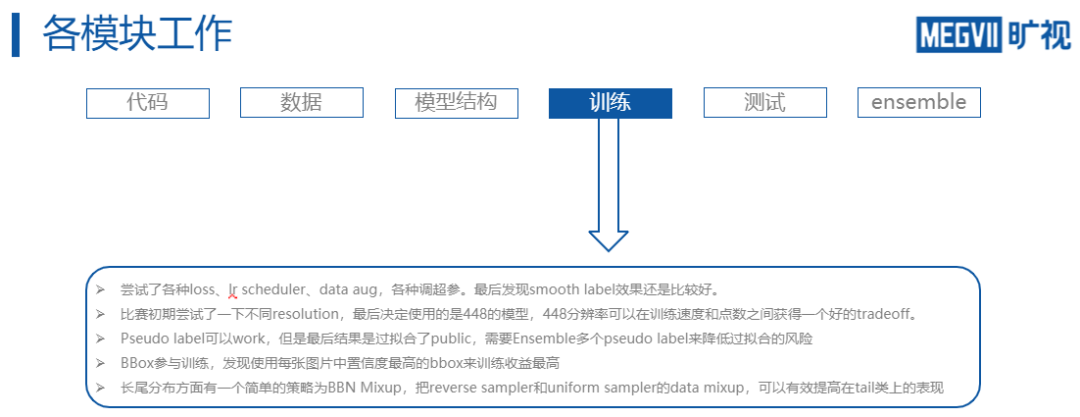
因此,
对于长尾分布,一般有两种解决方案,一种是Re-Sampling, 另外一种是Re- Weighting
。
所谓Re-Sampling,即指改进data sampler对数据的采样概率,来保证用来训练的数据的平衡性。
具体做法如上方右图,对所有的class以相同概率进行采样,采样出class之后在每个class内部再进行数据采样,这样便可以保证每个类在网络训练时的次数是相同的。
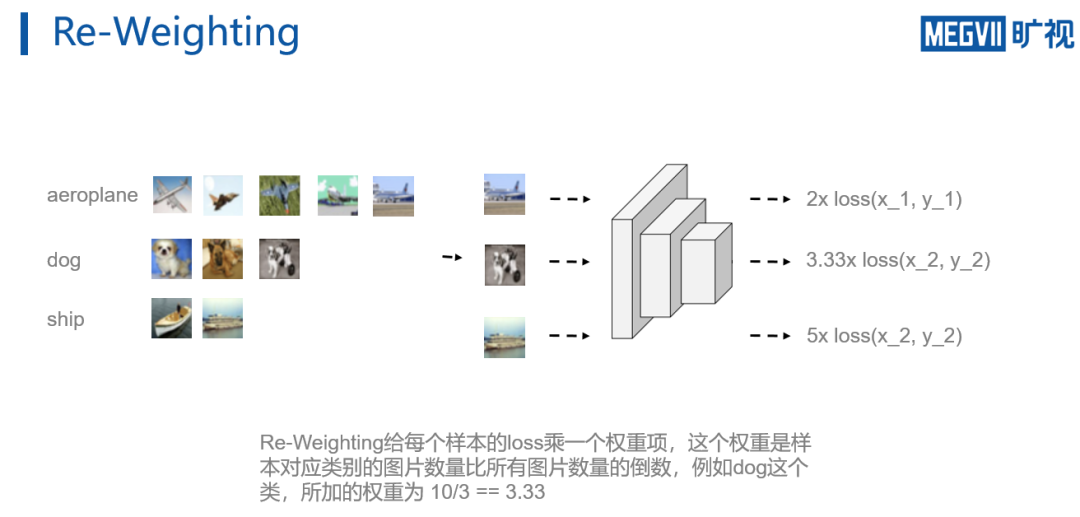
Re-Weighting指的是对数据进行随机采样,且再计算loss时,对不同类的样本乘上不同权重
。
该权重等于,每个样本对应类别的数量比上所有图片数量的倒数。例如对于对于aeroplane,有五张图片,总共十张图片,则对于aeroplane的加权就是10/5=2。如此操作,tail类的图片虽然被采样到的机会少,但是loss的加权大,从而可以实现平衡。
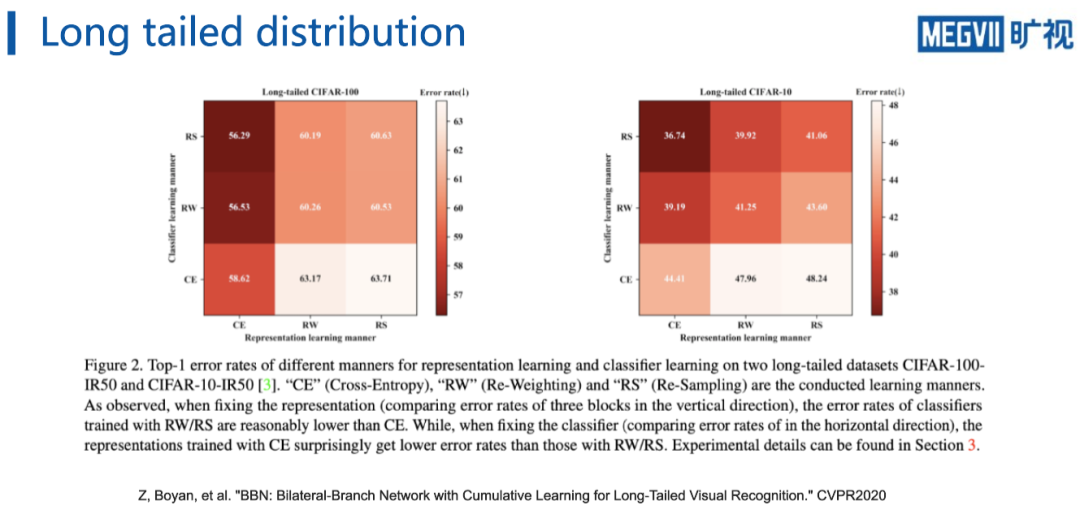
不过对于这两种解决长尾问题的策略,旷视南京研究院在CVPR 2020上的 Oral论文“BBN”指出,
虽然RW和RS可以改善分类器性能,但是会影响backbone对数据的表示能力
。
如这上图所示,为了
研究RS和RW对CNN 特征表示的影响和对分类器的影响,文章先用一种训练策略训练CNN backbon
e,然后再把backbone固定,重新训练分类器。
可以发现当分类的训练方式不变时,backbone使用CE的训练方式点数最高,而当backbone的训练方式固定不变时,使用RW和RS的方式训练分类器效果比较好。
这说明
RW和RS的方法虽然可以提高网络对长尾数据的表现,但是同时也会一定程度上损害网络的表示能力
。
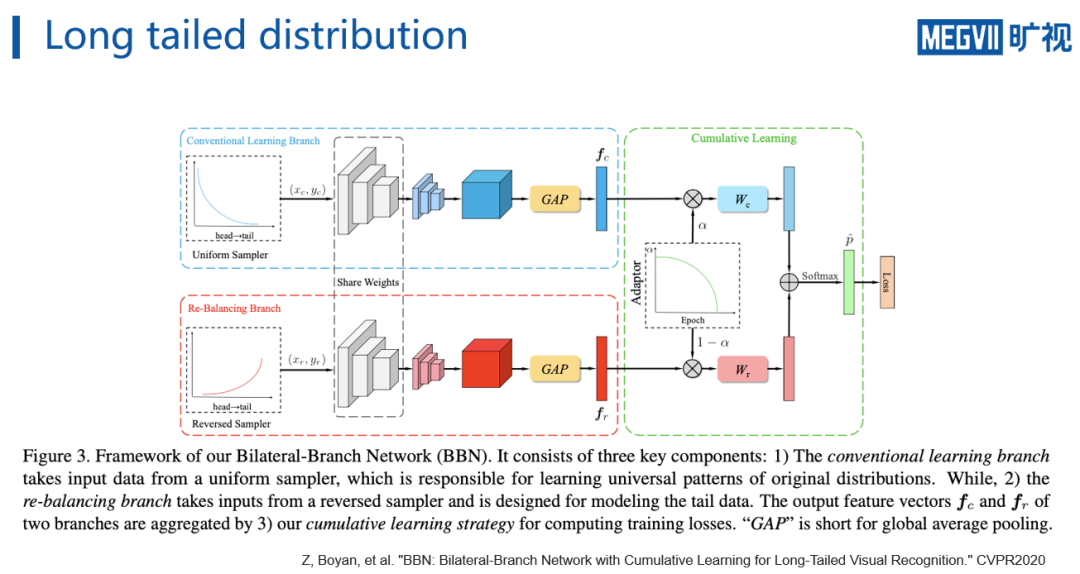
为此,BBN解决该问题的做法是,
将网络分成两个分支,一个分支接受从uniform sampler 采样出的数据,另外一个分支接受从reversed sampler 采样出的数据
。所谓reverse sampler,就是把每个类别被采样到的概率取倒数,从而使得tail类更容易被采样出来。
sample出两个batch的数据之后前传经过两个网络分支,进一步对两个分支的特征进行mixup,最后做分类loss。需要注意的是,BBN为了不损害特征表示,设计了一个adaptor,该adaptor会随着训练epoch的增加越来越倾向于增大reverse sampler 分支在mixup中的比重。
这样BBN可以保证在训练初期,网络通过正常的uniform sampler对数据学到一个良好的表征,在训练后期,这个表征会对reverse sampler 采样出的数据进行进一步的学习。
虽然BBN可以很大程度上减缓长尾数据对网络特征表示的影响,但是与此同时,
BBN需要同时训练两个网络分支,占用两倍于原来的显存,并且因为这样batchsize小了,训练时间需要更长
,对于比赛而言略需改进。
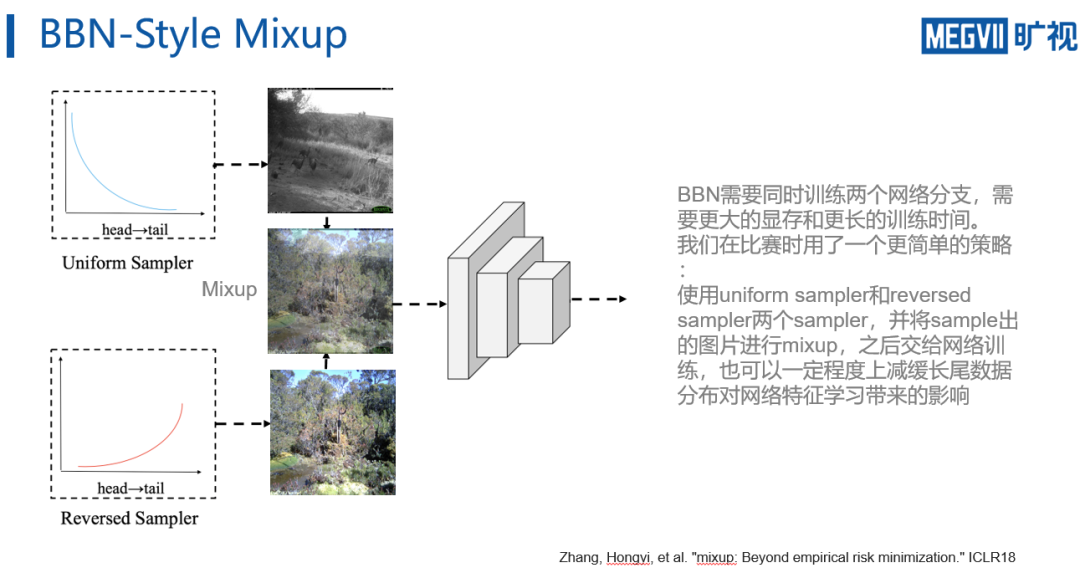
因此,参赛团队为了快速迭代,使用了一个
BBN-style 的mixup策略
。通过分别从uniform sampler和reversed sampler中采样,之后将两个sampler sample出的batch进行mixup之后交给网络训练,这样网络在训练时可以一定程度上见到足够多的head类和tail类样本,并且mixup本身也可以起到增强网络泛化性的效果,从而可以提高网络对长尾数据的表现。
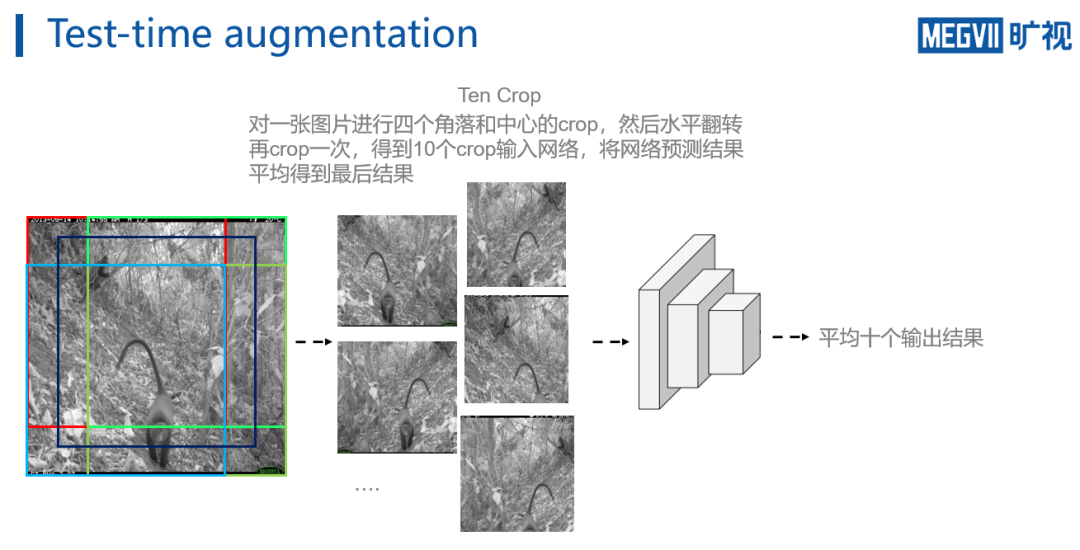
除上述工作外,在测试阶段,团队还使用了一个
增强策略tencrop
。它将输入图片的四个角落和中心进行crop获得原图的五个crop,之后将图片进行翻转再crop,总获得十个crop。通过将这些crop输入给网络进行前传,然后将十个预测结果进行平均,从而能够得到最后的预测结果。
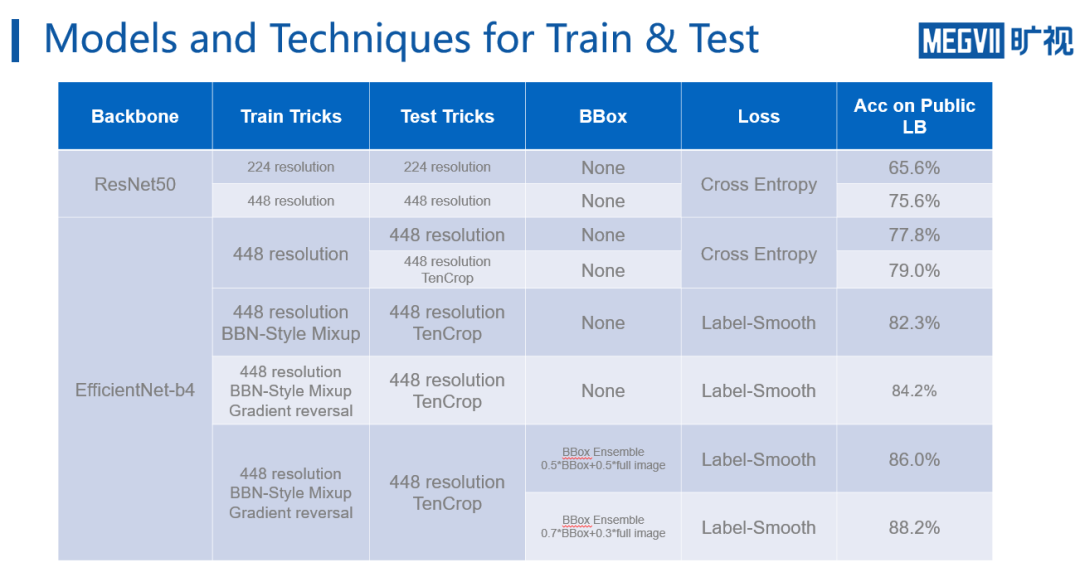
下图展示了旷视南京研究院参赛团队使用的所有的策略和它们在leaderboard对应的得分。
首先是224分辨率的
ResNet50 baseline
。该baseline使用交叉熵loss进行训练,可以在leaderboard得到65.6%的分数;第二个模型对分辨率扩大了一倍,使用448分辨率输入,使用交叉熵loss训练,可以看到扩大分辨率带来的收益非常大,在leaderboard上涨了接近十个点。 因此扩大分辨率这也是比赛很通用的CV的策略,基本上都可以实现涨点。
当换用
EfficientNet-b4
,输入分辨率也固定在了448,可以发现b4相对于ResNet50 的性能更好,同样设置下涨了两个点。 进一步,当在b4上加入测试时的tencrop,结果提升了一个多点。
当开始
将loss函数替换为
label-smooth
,且开始在训练时加入
BBN style的mixup
,网络继续上涨3个点。 此后一段时间内,点数都没有再得到提升,经过讨论,团队开始考虑location信息的影响,并设计出使用gradient reversal layer进行对location信息的混淆,突破了这个瓶颈,继续上涨2个点。
最后一个改进点涉及
MegaDetector的BBox信息
,使用上文提到的BBox Ensemble策略进一步实现了涨点。并且在这过程中,团队还观察到,随着Ensemble的进行,权重应该适当偏向于BBox内的物体,这样性能会更好。 到此时,团队的得分在总榜上位列第一,并持续了近1个月。期间虽然也尝试对模型进行改进,但并没有更新的发现。
到5月22日(最终截止日期前5天),Facebook团队突然以大比分反超。作为应对,旷视南京研究院团队紧急应对现有模型方法进行了全面分析,并发现之前一直没有利用的一个重要信息,即
视频的序列信息
。
事实证明,当利用了序列信息后,模型的性能大幅提升了近10个点。对此赵冰辰也半开玩笑地说道:“
存在一个强大对手的最好价值在于,它让你不安于现状,逼你跳出舒适圈,看到更好的自己。
”
由此,旷视南京研究院团队实现了被Facebook大幅超越,并在48小时内又以更大比分优势重新登顶,
最终夺得iWildCam全球冠军壮举
!
另外,为了帮助大家在参与顶会竞赛时更好地进行团队配合、项目管理,赵冰辰在下方还展
示了其团队在比赛期间各个模块的工作,以供
同学们参考。
下载1
在CVer公众号后台回复:OpenCV书籍,即可下载《Learning OpenCV 3》书籍和源代码。注:这本书是由OpenCV发起者所写,是官方认可的书籍。其中涵盖大量图像处理的基础知识介绍,虽然API还是基于OpenCV 3.x,但结合此书和最新API,可以很好的学习OpenCV。
![]()
下载2
在CVer公众号后台回复:CVPR2020,即可下载CVPR2020 2020代码开源的论文合集
在CVer公众号后台回复:ECCV2020,即可下载ECCV 2020代码开源的论文合集
重磅!CVer-论文写作与投稿交流群成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满2000+人,旨在交流顶会(CVPR/ICCV/ECCV/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI等)、SCI、EI等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
![]()
▲长按加微信群
![]()
▲长按关注CVer公众号
整理不易,请给CVer点赞和在看!![]()






 一个典型的camera trap设备
一个典型的camera trap设备


 训练集图片均来自于蓝色点表示的区域,它和红色区域没有相交。
训练集图片均来自于蓝色点表示的区域,它和红色区域没有相交。