【伯克利博士论文】通过对齐表示和图像来跨域自适应,95页pdf

深度卷积网络的出现推动了视觉识别领域的新一波进步。这些学习到的表示大大优于手工设计的特征,在视觉任务上获得更高的性能,同时在数据集上有更好的泛化性。尽管这些模型看起来很普遍,但当它们所训练的数据与所要求操作的数据之间存在不匹配时,它们仍然会受到影响。领域适应提供了一种潜在的解决方案,允许我们将网络从源领域训练到新的目标领域。在这些领域中,标记数据是稀疏的或完全缺失的。然而,在端到端可学习表示出现之前,视觉域适应技术很大程度上局限于在固定的、手工设计的视觉特征上训练的分类器。在这篇论文中,我们展示了如何将视觉域适应与深度学习相结合,以直接学习能够适应域移动的表示,从而使模型能够泛化到源域之外。
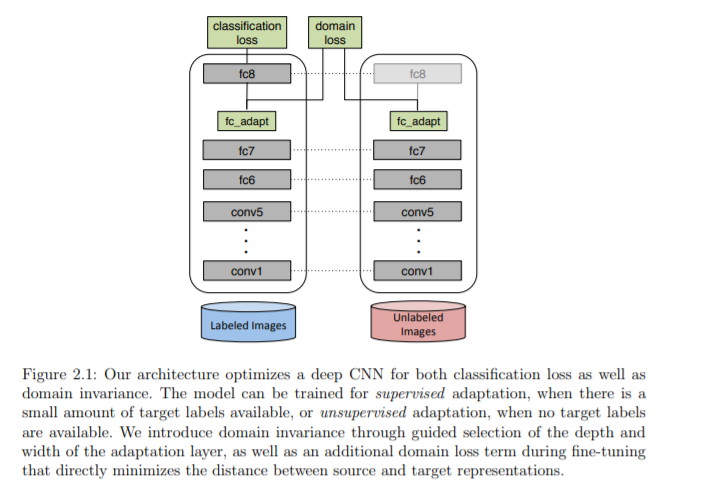
在第2章中,我们将演示如何设计损失,以衡量两个领域的不同程度。我们表明,通过优化表示来最小化这些损失,我们可以学习从源到目标更好地泛化的表示。在第3章和第4章中,我们展示了我们可以训练模型来尝试测量域差异,而不是手工设计这些域损失。由于这些模型本身是端到端可学习的,我们可以通过它们反向传播来学习表示,从而最小化学习的差异。这在概念上与生成式对抗网络类似,我们还探索了两者之间的关系,以及我们如何在对抗环境中使用为GANs开发的技术。最后,在第5章和第6章中,我们证明了适应性不需要局限于深度网络的中间特征。对抗适应技术也可以用于训练模型,直接改变图像的像素,将它们转换成跨域的类似物。然后,这些转换后的图像可以用作标记的伪目标数据集,以学习更适合目标领域的监督模型。我们表明,这种技术是基于特征的适应性的补充,当两者结合时产生更好的性能。
https://www2.eecs.berkeley.edu/Pubs/TechRpts/2020/EECS-2020-69.html



专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“表示对齐” 可以获取《【伯克利博士论文】通过对齐表示和图像来跨域自适应,95页pdf》专知下载链接索引



