若被制裁,中国AI会雪崩吗?

文 | 卖萌酱
大家好,我是卖萌酱。
昨天在卖萌屋的一个社群里产生了一段特别有意思的对话:
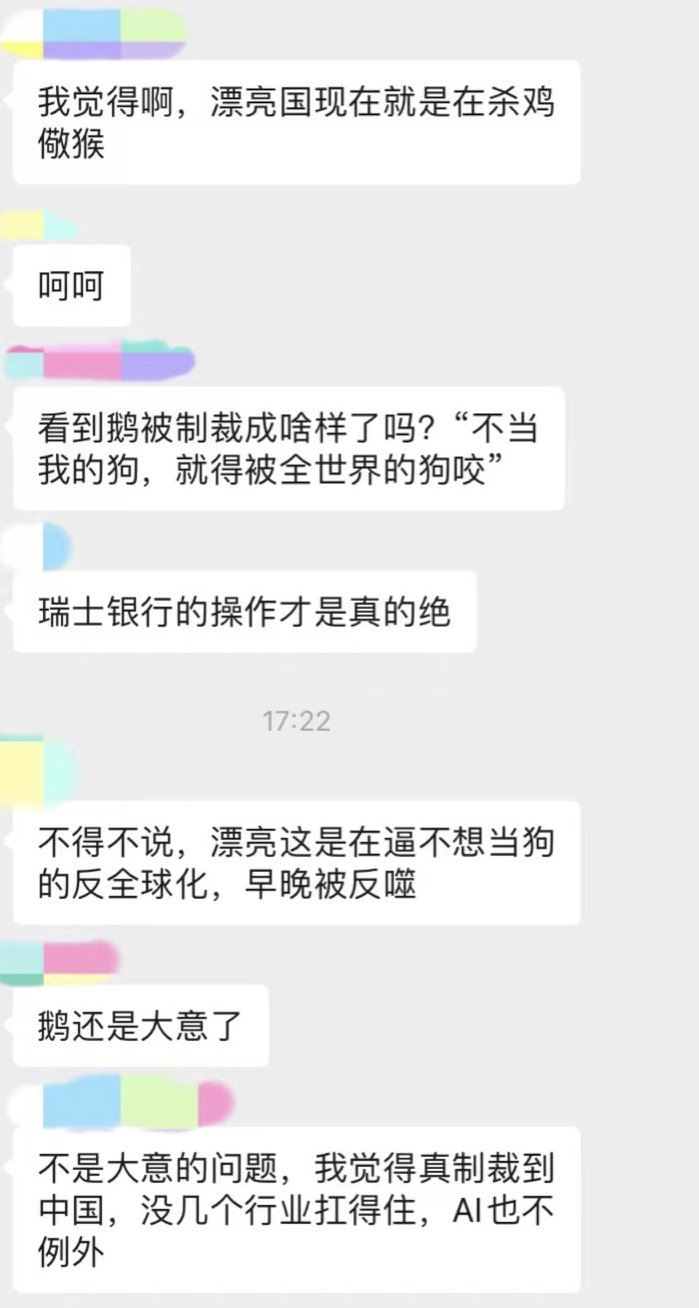
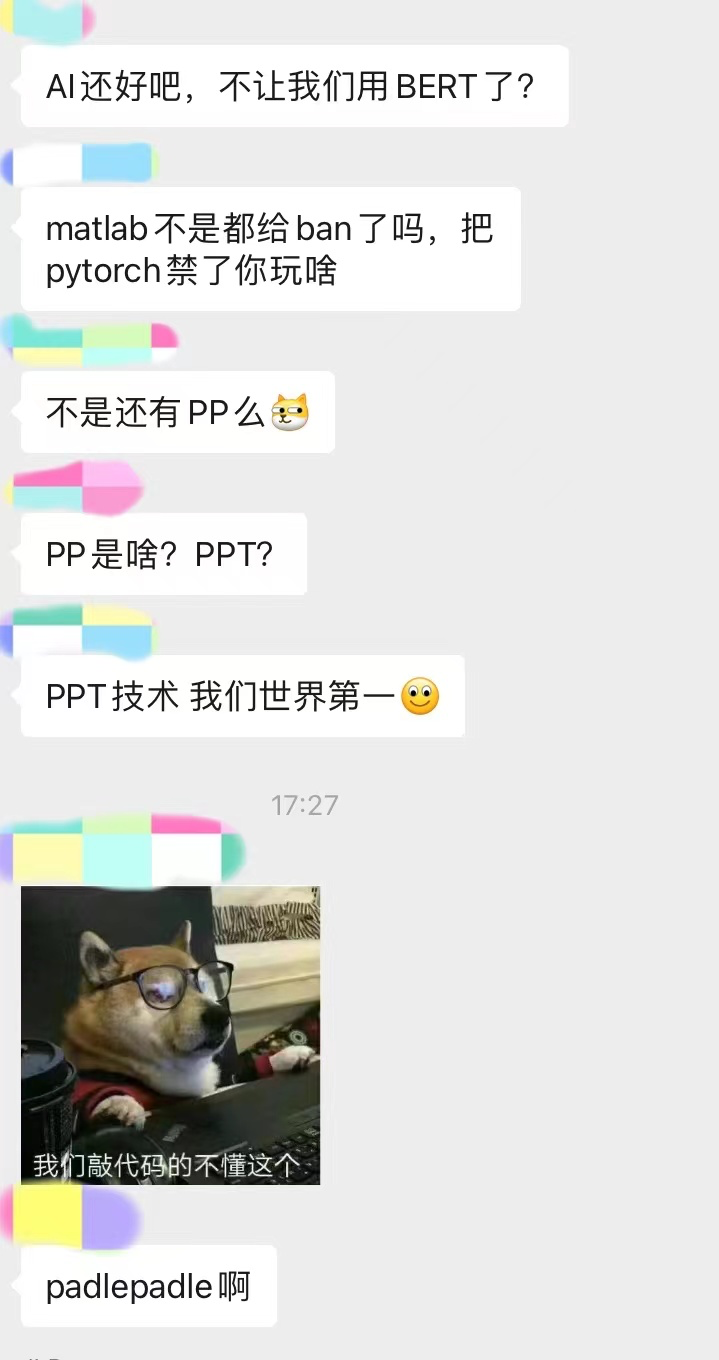

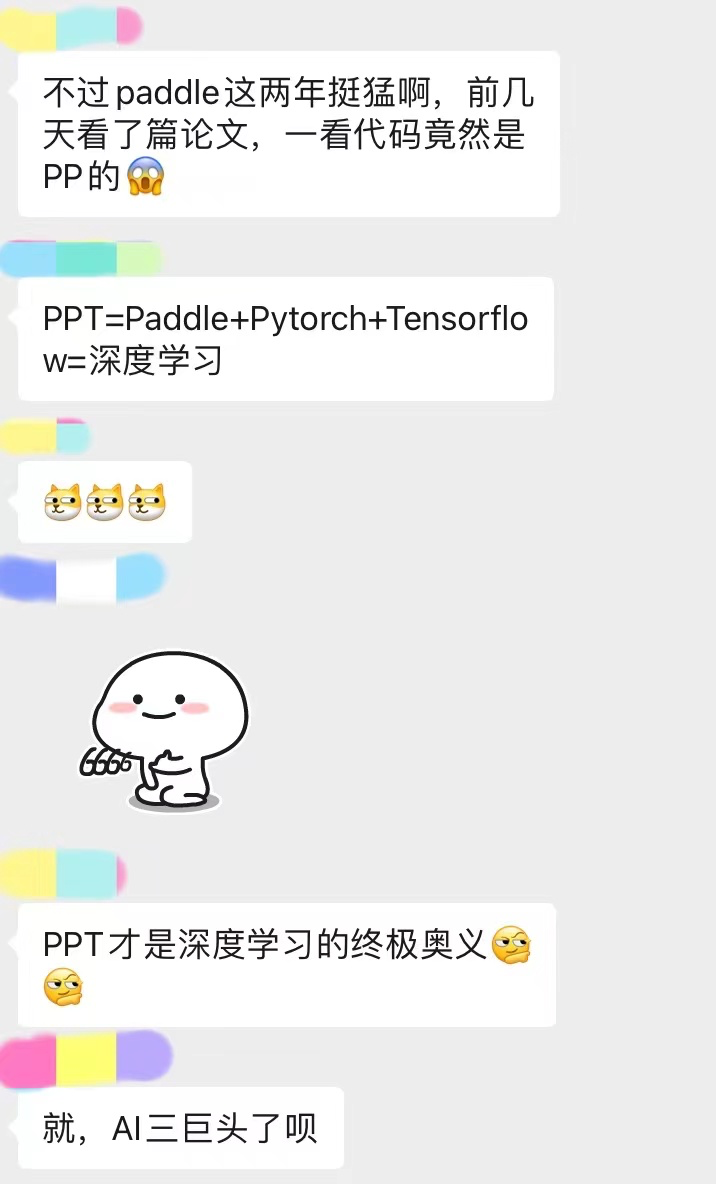
聊天太长了,截了最精彩的一部分。不得不说卖萌屋读者的创造力还是蛮nb的...
这些天鹅被花式制裁的新闻层出不穷,卖萌酱已经看麻了。
看着读者在群内讨论甚欢,卖萌酱不禁也思考起来——如果制裁真的发生在中国,发生在AI行业,我们是否有应对的能力?
尽管AI行业是一个很大概念,但从技术的角度,卖萌酱画了一张图

拿计算机体系结构做比喻的话:
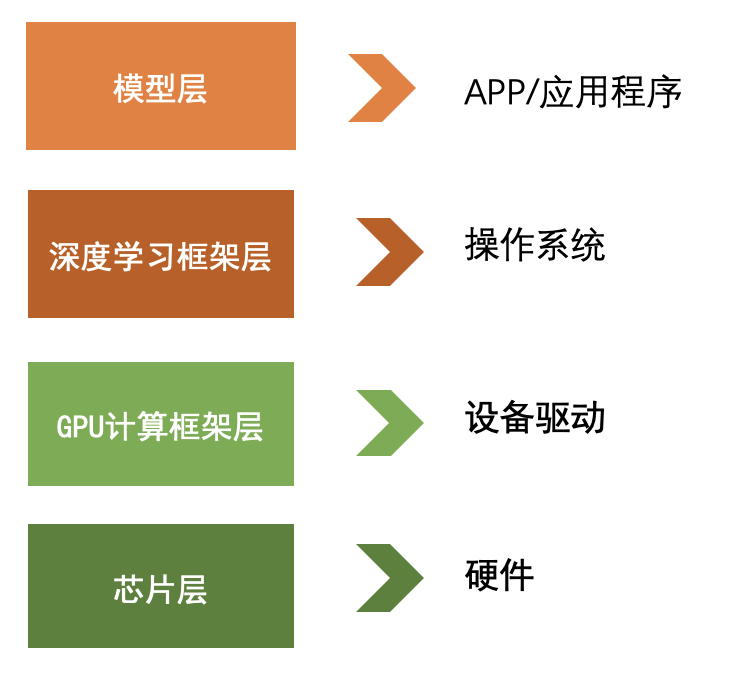
目前来看,
模型层要看细分场景,例如对于未开源的GPT-3,我们想要复现就极其困难,但我们又有自己的中文大模型。模型层面相对而言不太容易出现垄断优势,目前还看不到能够在产业层面卡脖子的模型。
深度学习框架层则是一个技术难度很高的环节,框架的计算性能、易用性、稳定性、模型生态对深度学习框架来说都至关重要,缺一不可。欣慰的是,国内至少有飞桨(paddlepaddle)同时解决了这四大难题,卖萌屋恰好也有多位作者在百度工作,卖萌酱跑去问百度大佬怎么看现在的pp,大佬回复:
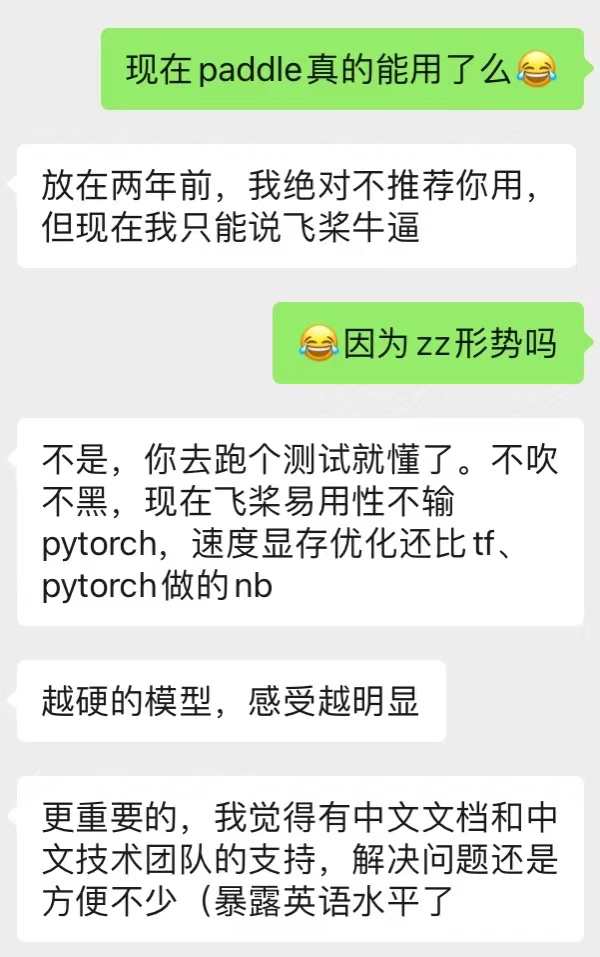
由此,卖萌酱想起了一句话:
士别三日当刮目相待
不得不说,当年百度研发深度学习框架,放在今天看,确实做对了。这种事情可能真的需要强大的技术信仰才能支撑下来吧(毕竟卖萌酱到现在也没搞懂深度学习框架怎么盈利,但对国内开发者、行业存亡和国家来说,真的是举足轻重)
尽管现在飞桨框架放在全球,尤其是在学术界来看,普及率还是没有Pytorch来得高。但据说在国内的产业界落地上,飞桨已经实现了极高市场份额的占领。这样哪怕发生最糟糕的情况,Pytorch和Tensorflow像matlab那样被美国ban掉,也不至于导致中国的AI产业和被AI赋能的传统产业被釜底抽薪,大范围出问题。
可以说,飞桨是国内AI行业的一份自信。
对于GPU计算层和芯片层来说,问题可能就没那么乐观了。
芯片层是公认的被美国卡脖子的环节,而GPU计算层又是跟芯片层高度绑定的。你用了哪一家的GPU,就得用哪一家的并行计算框架。而在AI方面,NVIDIA卡+CUDA的组合已经形成了绝对的垄断,不仅国内,哪怕是NVIDIA隔壁的AMD,也难从NVIDIA口中抢走AI赛道的哪怕一小块肉。
不过,经过华为中兴事件,显然国内的巨头们早就深刻意识到了芯片的重要性,因此百度、阿里、华为等互联网公司和科技公司纷纷下场造芯。本次俄乌事件中,台积电也毫不意外的对俄罗斯断供了芯片。
然而,芯片毕竟还是跟操作系统不一样的。
芯片工程涉及芯片设计、晶圆制造、封装测试、基础软件支持等多个环节,难以仅靠一家公司就能把这份全流程走完。因此要在芯片层面打破国外的技术封锁,仅靠互联网公司搞搞芯片设计是不行的,还要有工艺、技术能与台积电、ASML叫板的下游企业才行。
今天的国产芯片,就像2018年的飞桨框架,顶着来自竞品的巨大压力、内外部客户的吐槽、甚至部分国人的质疑和不解,负重前行。
但正如今天的飞桨终于凭借硬实力换来了口碑和市场,相信国产芯也终于一天迎来属于自己的高光时刻。
正如文章开头的聊天记录中,依然有人质疑飞桨是否真的扛起了框架大旗,这确实需要大家去自行体验了。学习一个新框架需要时间,改变从业者的刻板印象更加需要时间。
但不要忘记,技术是有国界的。在深度学习框架三巨头“PPT”中,就有一个字母是来自中国。
这是属于中国AI人的自信。
期待,我们有一天能把这份自信输出到全世界。

加入卖萌屋NLP、CV与搜推广求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!





