机器智能芯片 10 大新秀!华为抢占一席,Google 占比最多!


当年,阿基米德爷爷说出“给我一个支点,我就能撬动地球”这句话时,估计没少遭受嘲讽。
然而后来的我们,都曾在物理课本上学过这句话。
事实证明,小,也可以很有力量。
芯片,便是小体积、大能量的典型代表之一。
近日,一位外国科技作者,总结了10个用于机器智能的新型硅芯片的详细信息,从这10个硅芯片来看,谷歌占比最多,国内仅有华为一个。
一起来看看,这10个硅芯片的完整信息吧!
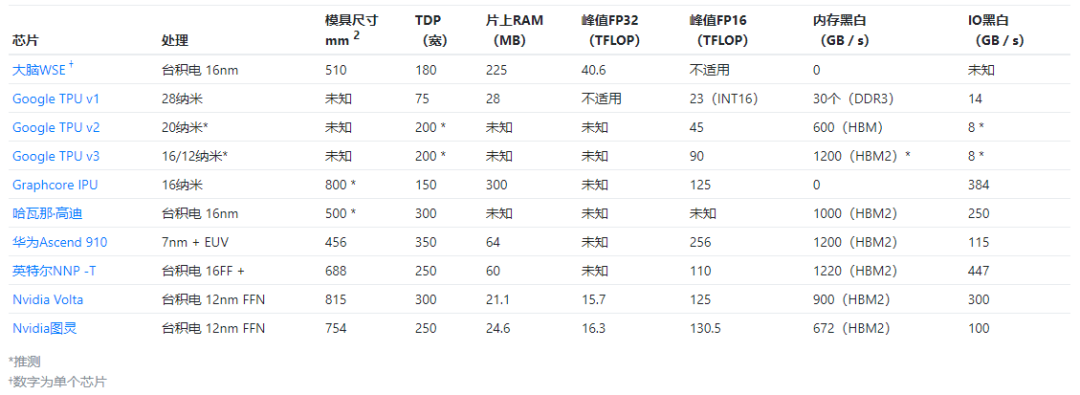
当当当当!先PO出一张图,来一个总览!

Cerebras晶圆级引擎芯片(Cerebras Wafer-Scale Engine)
Cerebras晶圆级引擎(WSE)芯片,无疑是最近出现的最大胆和创新的设计。晶圆级集成并不是一个新主意,但是与产量、功率传输和热膨胀有关的集成问题,使其难以商业化。
Cerebras使用这种方法将84个芯片与高速互连集成在一起,从而将基于2D网格的互连按比例缩放到很大比例。
这样可以为机器提供大量内存(18 GB)分布在大量计算中(3.3 Peta FLOP峰值)。
目前,尚不清楚该架构如何扩展到单个WSE之外。当前神经网络的趋势是拥有数十亿权重的大型网络,这将需要进行这样的缩放。
该芯片细节:
宣布于2019年8月。
TSMC 16 nm的46,225 mm 2晶圆级集成系统(215 mm x 215 mm)。
1.2T晶体管。
许多单独的筹码:总共84(12宽乘7高)。
总共18 GB的SRAM存储器,分布在内核之间。
426,384个简单计算核心。
硅缺陷可以通过使用冗余内核和链路绕过故障区域来修复。
推测的时钟速度约为1 GHz,功耗为15 kW。
互连和IO:
跨越划线的芯片之间的互连,以及在常规晶圆制造后的后处理步骤中添加的布线。
IO在晶圆的东西边缘带出,这受每个边缘的焊盘密度限制。不可能有高速SerDes,因为这些高速SerDes需要集成在每个芯片中,从而使晶圆区域中相当大的一部分与外围具有边缘的芯片成为多余。
基于2D网格的互连,支持单字消息。据官方白皮书表示:“ Cerebras软件将WSE上的所有核心配置为支持所需的精确通信”。
互连需要静态配置以支持特定的通信模式。
未在互连上传输零以优化稀疏性。
每个核心:
是〜0.1 mm 2的硅。
具有47 kB SRAM存储器。
零未从内存中加载,零未相乘。
假定FP32精度和标量执行(无法使用SIMD从内存中过滤零)。
FMAC数据路径(每个周期8个峰值操作)。
张量控制单元向FMAC数据路径提供来自内存的跨步访问或来自链接的入站数据。
有四个与其邻居相邻的8 GB / s双向链接。
每个骰子:
是17毫米x 30毫米= 510毫米2的硅。
具有225 MB SRAM 内存。
具有54 x 94 = 5,076个核心(由于修复方案而剩下4,888个可用核心,每行/列两个核心可能未使用)。
FP32的峰值FP32性能达到40 Tera FLOP。

Google TPU v3
目前由于没有关于Google TPU v3规格的详细信息,它可能是对TPU v2的增量改进:将性能提高一倍,添加HBM2内存以使容量和带宽增加一倍。
该芯片细节:
2018年5月宣布。
可能是16nm或12nm。
预计TDP为 200W 。
BFloat16的105个TFLOP,可能是将MXU加倍到四个。
每个MXU都具有对8 GB内存的专用访问权限。
集成在四芯片模块(如图)中,峰值性能达420个TFLOP。
IO:
32 GB HBM2集成内存,访问带宽为1200 GBps(假定)。
假定PCIe-3 x8为8 GBps。

Google TPU v2
Google TPU V2是专为训练和推理而生的芯片。它通过浮点算法改进了TPU v1,并通过HBM集成存储器增强了存储容量和带宽 。
该芯片细节:
2017年5月宣布。
可能是20nm。
预计TDP为 200-250W 。
45 TFLOP的BFloat16。
具有标量和矩阵单元的两个核心。
还支持FP32。
集成在四芯片模块(如图)中,具有180个TFLOP峰值性能。
每个核心:
具有BFloat16乘法和FP32累加的128x128x32b脉动矩阵单元(MXU)。
8GB专用HBM,访问带宽为300 GBps。
BFloat16的峰值吞吐量为22.5 TFLOP。
IO:
16 GB HBM集成内存,带宽为600 GBps(假定)。
PCIe-3 x8(8 GBps)。

Google TPU v1
Google的第一代TPU仅用于推理,并且仅支持整数运算。
它通过在PCIe-3上发送指令来为主机CPU提供加速,以执行矩阵乘法和应用激活功能。这是一个显着的简化,可以节省很多设计和验证时间。
该芯片细节:
在2016年宣布。
331 mm 2在28nm工艺上死亡。
时钟频率为700 MHz,TDP为 28-40W 。
28 MB片上SRAM存储器:24 MB用于激活,4 MB用于累加器。
芯片面积的比例:35%的内存,24%的矩阵乘法单元,41%的逻辑剩余空间。
256x256x8b脉动矩阵乘法单元(64K MAC /周期)。
INT8和INT16算术(分别为峰值92和23 TOPs / s)。
IO:
可通过两个端口以34 GB / s的速度访问8 GB DDR3 -2133 DRAM。
PCIe-3 x 16(14 GBps)。

Graphcore IPU
Graphcore IPU架构与大量带有小内存的简单处理器的高度并行,并通过高带宽的所有“交换”互连进行连接。
该体系结构在体同步并行(BSP)模型下运行,由此程序的执行按一系列计算和交换阶段进行。
该BSP模型是一个强大的编程抽象,因为它排除并发危害,BSP执行允许计算和交换阶段充分利用芯片的电力资源。通过连接10个IPU间,可以构建更大的IPU芯片系统链接。
该芯片细节:
16 nm,236亿个晶体管,〜800mm 2芯片尺寸。
1216个处理器块。
具有FP32累加功能的125个TFLOP峰值FP16算法。
300 MB的总片上内存分布在处理器内核之间,提供45 TBps的总访问带宽。
所有模型状态都保存在芯片上,没有直接连接的DRAM。
150 W TDP(300 W PCIe卡)。
IO:
2个PCIe-4主机IO链接。
10x卡间“ IPU 链接”。
总共384 GBps IO带宽。
每个核心:
混合精度浮点随机算法。
最多运行六个程序线程。

哈瓦那实验室高迪(Habana Labs Gaudi)
哈瓦那的Gaudi AI培训处理器与现代GPU具有相似之处,特别是广泛的SIMD并行性和HBM2内存。
该芯片集成了十个100G以太网链路,这些链路支持远程直接内存访问(RDMA)。
与Nvidia的NVLink或OpenCAPI相比,这种 IO功能使大型系统可以使用商用网络设备构建。
该芯片细节:
2019年6月宣布。
采用CoWoS的TSMC 16 nm,假定管芯尺寸为〜500mm 2。
异构架构,具有:
一个GEMM操作引擎;
8个Tensor处理核心(TPC);
共享的SRAM存储器(可通过RDMA管理和访问的软件)。
PCIe卡为200W TDP,夹层卡为300W TDP。
未知的总片上存储器。
芯片之间的显式内存管理(无一致性)。
TPC核心:
VLIW SIMD并行性和本地SRAM 存储器。
混合精度:FP32,BF16以及整数格式(INT32,INT16,INT8,UINT32,UINT8)。
随机数生成。
超越函数:Sigmoid,Tanh,高斯误差线性单位(GeLU)。
张量寻址和跨步访问。
每个TPC未知的本地内存。
IO:
4个HBM2 -2000 DRAM堆栈,以1 TBps的速度提供32 GB。
片上集成了10个100GbE接口,支持基于融合以太网(RoCE v2)的RDMA。
IO使用20个56 Gbps PAM4 Tx / Rx SerDes实现,也可以配置为20个50 GbE。这样最多可连接64个芯片,并且吞吐量无阻塞。
PCIe-4 x16主机接口。

华为Ascend 910
华为的Ascend与具有宽SIMD算术和3D矩阵单元的最新GPU相似。该芯片包括用于H.264 / 265的128通道视频解码引擎的附加逻辑。
在华为官方的Hot Chips演示中,华为描述了将多维数据集和向量操作重叠以获得高效率以及内存层次结构的挑战,其中L1高速缓存(核心)的带宽与吞吐量之比降低10倍,L2高速缓存降低100倍(共享核心)和2000x用于外部DRAM。
该芯片细节:
宣布于2019年8月。
456 mm 2逻辑芯片在7+ nm EUV工艺上进行。
与四个96 mm 2 HBM2堆栈和“ Nimbus” IO处理器芯片共同封装。
32个达芬奇核心。
峰值256个TFLOP(32 x 4096 x 2)FP16性能,是INT8的两倍。
32 MB共享片上SRAM(二级缓存)。
350W TDP。
互连和IO:
内核在6 x 4 2D网状分组交换网络中互连,每个内核提供128 GBps的双向带宽。
对L2缓存的访问速度为4 TBps。
1.2 TBps HBM2访问带宽。
3个30 GBps的芯片间IO。
2个25 GBps RoCE网络接口。
每个达芬奇核心:
3D 16x16x16矩阵乘法单元,提供4,096个FP16 MAC和8,192个INT8 MAC。
FP32(x64),FP16(x128)和INT8 (x256)的2,048位SIMD矢量操作。
支持标量运算。

英特尔NNP -T
继至强融核之后,该芯片是英特尔针对机器学习加速器的第二次尝试。像Habana Gaudi芯片一样,它集成了少量的宽矢量核,HBM2集成存储器和类似的100 Gbit IO 链接。
该芯片细节:
270亿个晶体管。
在带有CoWoS的TSMC 16FF + TSMC上,688 mm 2模具。
四个8 GB堆栈中的32 GB HBM2 -2400 集成在1200 mm 2的无源硅中介层上。
60 MB的片上SRAM存储器分布在内核之间,并 受ECC保护。
最高1.1 GHz核心时钟。
150-250W TDP。
24个Tensor处理群集(TCP)内核。
TPC以2D网状网络拓扑连接。
用于不同类型数据的独立网络:控制,存储器和芯片间通信。
支持多播。
119个最佳性能峰值。
IO:
HBM2带宽为1.22TBps 。
芯片间IO的64个SerDes通道的峰值带宽为3.58Tbps(每个通道的每个方向28 Gbps)。
x16 PCIe-4主机接口(还支持OAM和Open Compute)。
TPC核心:
2个32x32 BFloat16乘法器阵列,支持FMAC操作和FP32累加。
向量FP32和BFloat16操作。
支持先验功能,随机数生成,减少和累积。
可编程FP32查找表。
用于非MAC计算的独立卷积引擎。
2.5 MB的两端口专用内存,具有1.4 TBps的读/写带宽。
内存支持张量转置操作。
通信接口支持网状网络上的动态数据包路由(虚拟通道,可靠的传输)。
缩放比例:
多达1024个具有直接互连的芯片,提供相同的分布式内存编程模型(显式内存管理,同步原语,消息传递)。
扩展展示了以环形拓扑连接的多达32个芯片。

Nvidia Volta
据了解,Volta从Pascal架构引入Tensor Cores、HBM2和NVLink 2.0 。
该芯片细节:
2017年5月宣布。
815毫米2上TSMC 12海里FFN,21.1 BN晶体管。
300 W TDP(SXM2尺寸)。
6 MB二级缓存。
84个SM,每个SM包含:64个FP32 CUDA内核,32个FP64 CUDA内核和8个Tensor内核(5376 FP32内核,2688 FP64内核,672个TC)。
Tensor Core执行4x4 FMA,实现64 FMA运算/周期和128 FLOP。
每个SM 128 KB L1数据高速缓存/共享内存和四个16K 32位寄存器。
IO:
32 GB HBM2 DRAM,900 GBps带宽
NVLink 2.0(300 GBps)。

Nvidia图灵
Turing是Volta的体系结构修订版,采用相同的16 nm工艺制造,但具有更少的CUDA和Tensor内核。
因此,它具有更小的管芯尺寸和更低的功率范围。除ML任务外,它还设计用于执行实时射线追踪,为此它还使用了Tensor Core。
该芯片细节:
2018年9月宣布。
台积电12nm FFN,754 mm 2芯片,186亿个晶体管。
260瓦TDP。
72个SM,每个SM包含:64个FP32内核和64个INT32内核,8个Tensor内核(4608 FP32内核,4608 INT32内核和576个TC)。
带有升压时钟的峰值性能:16.3 TFLOPs FP32、130.5 TFLOPs FP16、261 TFLOPs INT8、522 TFLOPs INT4。
24.5 MB片上存储器,介于6 MB L2高速缓存和256 KB SM寄存器文件之间。
1455 MHz基本时钟。
IO:
12个32位GDDR6内存,可提供672 GBps的聚合带宽。
2个NVLink x8链接,每个链接提供高达26 GBps的双向速度。
以上10个芯片,你认为哪个最有前景?赶快在评论区留言吧!
参考:https://www.jameswhanlon.com/new-chips-for-machine-intelligence.html#google-tpu-1
【END】

☞快手王华彦:端上视觉技术的极致效率及其短视频应用实践 | AI ProCon 2019




