“中文版GPT-3”来了:会算术、可续写红楼梦,用64张V100训练了3周
晓查 发自 凹非寺
量子位 报道 | 公众号 QbitAI
今年,OpenAI推出的自然语言模型GPT-3引起了巨大的轰动。
这是迄今为止最大的NLP模型,包含1750亿参数,光是训练就调用上万块GPU,花费了460万美元的成本。
但GPT-3是基于英语语料库进行训练,而且并不开源,业内一直期待着能有一个中文的超大型NLP模型。
现在,它终于来了!

最近,北京智源人工智能研究院和清华大学研究团队,合作开展了一项大规模预训练模型开源计划——清源CPM (Chinese Pretrained Models)。
11 月中旬,CPM将开放第一阶段的26亿参数规模的中文语言模型 (CPM-LM) 和217亿参数规模的结构化知识表示模型 (CPM-KM) 下载,以及相应的Demo。
该项目的源代码和模型已经在GitHub和官网开放下载。

CPM中文语言模型与GPT-3模型类似,仅需要通过少次、单次学习甚至零次学习,就能完成不同自然语言处理任务,具备一定的常识和认知的泛化能力。
官方表示,清源CPM计划所有模型免费向学术界和产业界开放下载,供研究使用。
模型特点
与已有的中文预训练模型相比,本次发布的清源 CPM 大规模预训练模型具有以下特点:

1、语料丰富多样:收集大量丰富多样的中文语料,包括百科、小说、对话、问答、新闻等类型。
2、模型规模大:本次发布的 CPM-LM 的参数规模为 26 亿,预训练中文数据规模100 GB,使用了 64 块 V100 GPU 训练时间约为 3 周。
3、学习能力强:能够在多种自然语言处理任务上,进行零次学习或少次学习达到较好的效果。
4、行文自然流畅:基于给定上文,模型可以续写出一致性高、可读性强的文本,达到现有中文生成模型的领先效果。
Demo展示
为了更直观地展示清源CPM预训练模型的效果,官方提供了一些文本生成的Demo。
GPT-3能胜任的常识性问答,CPM预训练模型一样可以应对:

它能够根据真实的天气预报内容,生成天气预报文本模板:

除了生成文字外,清源CPM还具有一定的数理推理,根据之前的规律生成计算结果:

甚至可以续写红楼梦片段:

另外,智源和清华团队还在几项基准测试中验证了清源CPM的实际性能。
1、中文成语填空
ChID 是 2019 年清华大学对话交互式人工智能实验室(CoAI)收集的中文成语填空数据集,其目标是对于给定的段落,在 10 个候选项中选择最符合段意的成语进行填空。

表中汇报了预测的准确率,可以看到,CPM(大) 在无监督的设定下甚至达到了比有监督的 CPM (小) 更好的结果,反应了清源 CPM 强大的中文语言建模能力。
2、对话生成
STC是2015年华为诺亚方舟实验室提出的短文本对话数据集,要求在给定上文多轮对话的条件下预测接下来的回复。

在无监督的设定下,清源 CPM 具有更好的泛化性,在有监督设定下,清源 CPM 能达到比 CDial-GPT 更优的效果,尤其在多样性指标上表现更佳。以下为生成的对话样例。

3、文本分类
清源 CPM 使用头条新闻标题分类 (TNEWS,采样为4分类),IFLYTEK应用介绍分类 (IFLYTEK,采样为4分类),中文自然语言推断 (OCNLI,3分类) 任务作为文本分类任务的基准。

可以看出,清源CPM能够在无监督的设定下达到比随机预测 (TNEWS/IFLYTEK/OCNLI 随机预测精确度分别为0.25/0.25/0.33) 好得多的精确度。
4、自动问答
CPM 使用 DuReader 和CMRC2018 作为自动问答任务的基准,要求模型从给定的段落中抽取一个片段作为对题目问题的答案。其中DuReader 由百度搜索和百度知道两部分数据组成。
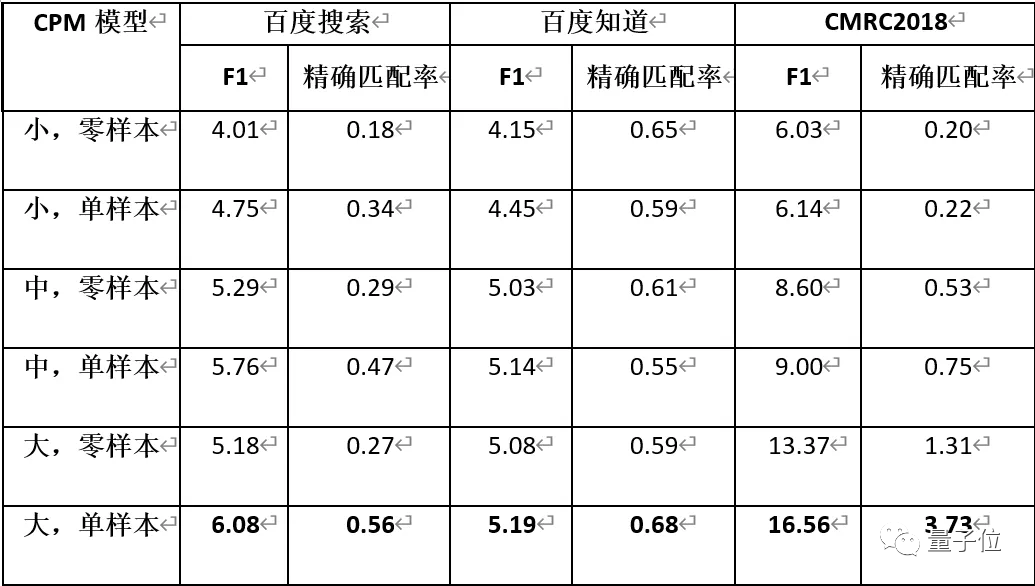
在单样本设定下,CPM 能从给定的样本中学习到生成答案的模式,因此效果总是比零样本设定更好。由于模型的输入长度有限,多样本输入的场景将在未来进行探索。
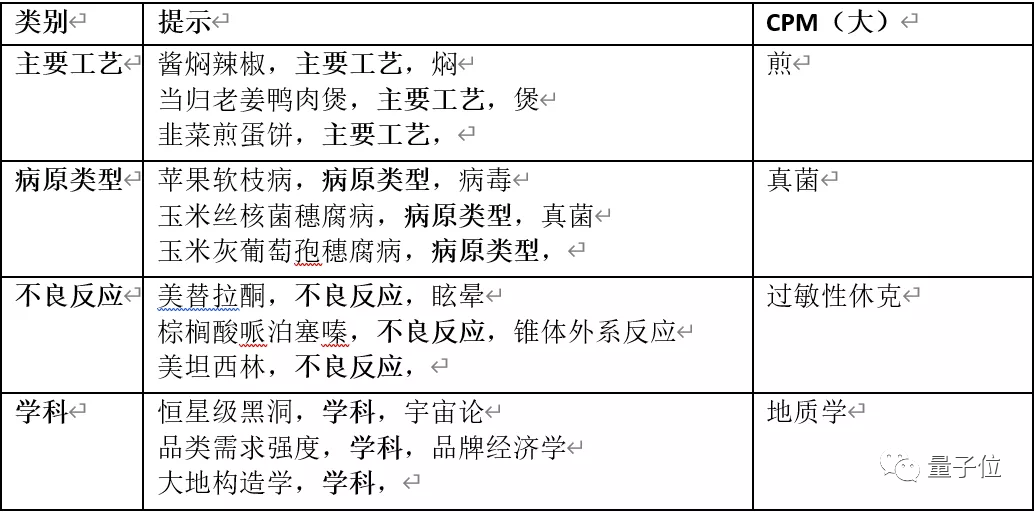
5、实体生成
CPM 采用 XLORE 中的几种常见的关系三元组作为实体生成任务的基准。在少样本设定 (把少量真实样本拼在待预测样本前作为提示) 下,不同规模的 CPM 模型的 BLEU-1 值如下表所示。

可以看出参数量越大时,模型对于预测实体效果越好。同时,模型在给定 2 个样本时就可以达到不错的效果,大部分时候 N=2 和 N=4 的效果是接近的。
64块V100训练3周
智源和清华本次发布的大规模预训练模型,难以在单块GPU上运行,因此需要将模型在多个 GPU之间分配参数,进行并行化训练。
CPM正是基于英伟达的大规模并行计算训练项目Megatron-LM。
CPM模型预训练过程分布在多块 GPU 上,采用层内并行的方法进行训练,并基于当前已有的成熟技术,减少同步提高通讯速率。
本次发布的CPM-LM的参数规模为26亿,预训练中文数据规模100GB,使用64块英伟达V100 GPU,训练时间约为3周。
而CPM-KG的参数规模为217亿,预训练结构化知识图谱为WikiData全量数据,包含近 1300 个关系、8500万实体、4.8 亿个事实三元组,使用了8块英伟达V100 GPU训练时间约为2周。
未来计划
今年年底开源的两个项目只是清源NLP研究计划的第一步,据了解,清源 CPM 未来一年的研究和开源计划是:

阶段1 (2020年10月-12月):中文大规模预训练语言模型,含约 30 亿参数,训练数据包括 100GB 中文数据。
阶段2 (2021年01月-06月):以中文为核心多语言大规模预训练语言模型,含约 200 亿参数,训练数据包括 500GB 以中文为核心的多语言数据。
阶段3 (2021年07月-09月):知识指导的大规模预训练语言模型,含约 1000 亿参数,训练数据包括 1TB 以中文为核心的多语言数据和亿级实体关系图谱。
清源 CPM 计划将积极配备算力、数据和人力,注重开展原创研究,尽早实现与国际顶尖机构在超大规模预训练模型技术方面并跑,提升中文自然语言的深度理解和生成能力。
与此同时,智源研究院也将积极与产业界合作,在智能客服、个性推荐、文本生成、自动编程等方面,探索新型的人工智能应用和商业模式。
关于清源CPM计划
清源CPM计划是以中文为核心的大规模预训练模型。
首期开源内容包括预训练中文语言模型和预训练知识表示模型,可广泛应用于中文自然语言理解、生成任务以及知识计算应用。
清源CPM计划由北京智源人工智能研究院和清华大学研究团队合作开展。“自然语言处理”是智源研究院重点支持的重大研究方向之一。
智源在该方向上集结了大量国内权威学者,这些学者在NLP领域积累了丰富的研究成果。
如清华大学孙茂松、刘知远团队和李涓子、唐杰团队提出了知识指导的预训练模型 ERNIE 和 KEPLER,循环智能杨植麟团队提出了性能显著优于 BERT 的 XLNet 模型,清华大学朱小燕和黄民烈团队提出了面向情感分析的预训练模型 SentiLARE,融合常识知识的预训练语言生成模型 StoryGPT,面向中文对话生成的 CDial-GPT模型,等等。
研究团队将在智源研究院大规模算力平台的支持下,开展以中文为核心的超大规模预训练模型研究,包括跨语言学习、文本生成、知识融合、模型并行和压缩等前沿课题,并将相关模型及时通过智源社区开源共享。
传送门
清源CPM项目主页:
https://cpm.baai.ac.cn/
清源CPM源代码主页:
https://github.com/TsinghuaAI/CPM-Generate
— 完 —
本文系网易新闻•网易号特色内容激励计划签约账号【量子位】原创内容,未经账号授权,禁止随意转载。
量子位年度智能商业峰会启幕,
李开复等AI大咖齐聚,
邀你共探新形势下智能产业发展之路


量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见~



