这个懂中文的AI高手,画出的高山明月太惊艳!中英双语AltDiffusion模型已开源
![]()
新智元报道

新智元报道
【新智元导读】AIGC 如火如荼发展的当下,中文世界的创作者常有几大痛点:思考英文Prompts准确表达的绞尽脑汁,翻译软件词不达意的尴尬,精细构思的 Prompts 在画面生成中找不到一丝痕迹,亦或面对文化误解中的「中国风」哭笑不得……
日前,智源研究院大模型研究团队开源最新双语 AltDiffusion 模型,为中文世界带来专业级 AI 文图创作的强劲动力:
支持精细长中文 Prompts 高级创作;无需文化转译,从原汁原味中国话直达形神兼备中国画;且在绘画水平上达到低门槛中英对齐原版 Stable Diffusion 级震撼视效,可以说是讲中文的世界级 AI 绘画高手。

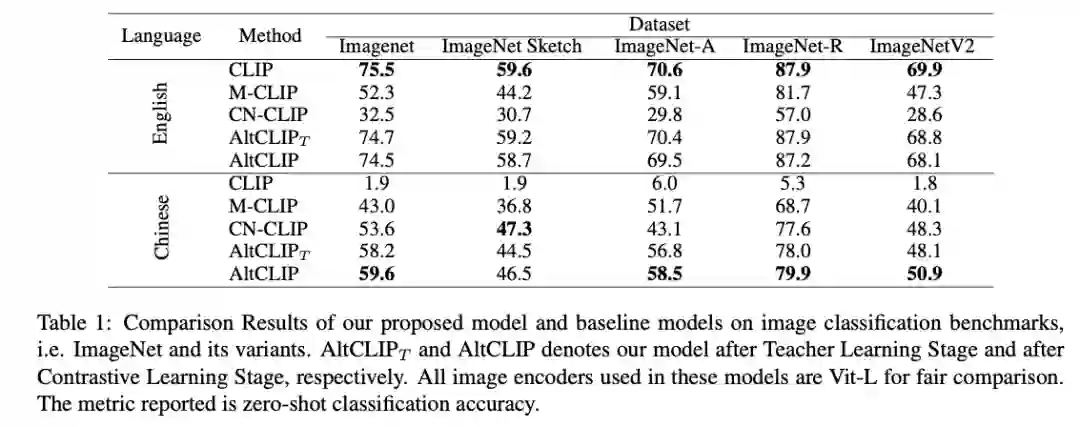
创新模型 AltCLIP 为这一工作的基石,为原 CLIP 模型补齐更强的跨语言三大能力。AltDiffusion 和 AltCLIP 模型均为多语言模型,中英双语为第一阶段工作,代码与模型已开源。
https://github.com/FlagAI-Open/FlagAI/tree/master/examples/AltDiffusion
https://github.com/FlagAI-Open/FlagAI/examples/AltCLIP
https://huggingface.co/spaces/BAAI/bilingual_stable_diffusion

https://arxiv.org/abs/2211.06679
专业级中文 AltDiffusion
——长Prompt精细绘画 + 原生中国风,满足中文AI创作高手的高需求
1. 长Prompt生成,画面效果毫不逊色
Prompt长短是检验模型文图生成能力的分水岭,越长的Prompt,越考验语言理解、图文对齐和跨语言这三大能力。
在同样的中英文长 Prompt 输入调校下,AltDiffusion 在不少图片生成案例中表现力甚至更胜一筹:元素构成丰富精彩、细节描摹细腻精准。
▽


2. 更懂中国话,更善中国画
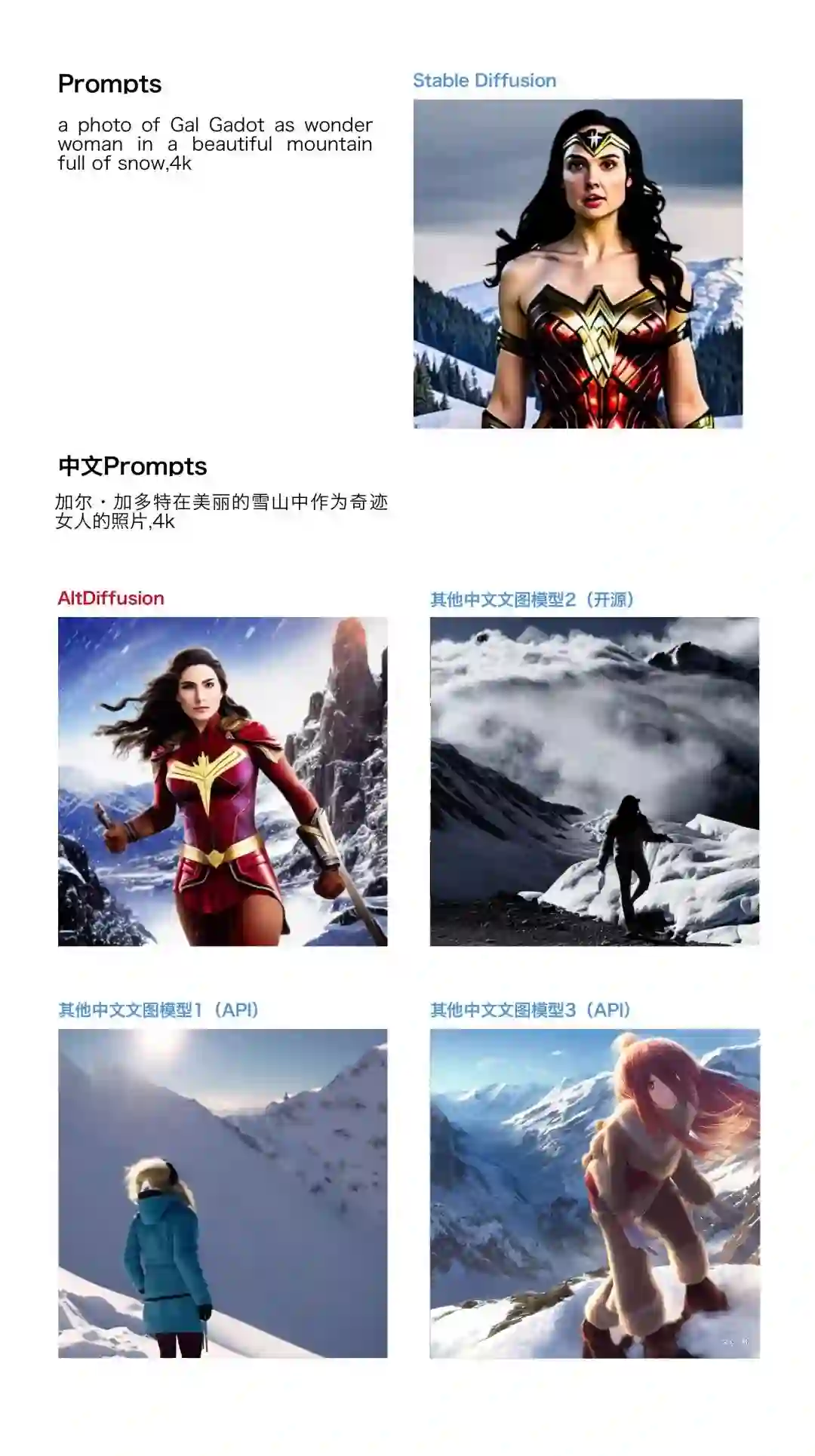
除中英文 Prompts 输入表现近似之外,AltDiffusion 还能补齐西方世界里中国画风的不足,利用中文图文对继续微调出中文特色的生成,例如国画风格生成模型,产出真正的「中国风」。







AltDiffusion 更懂中文,在中国文化语境中的意义描摹上指哪打哪,秒懂创作者意图。例如对「唐朝盛景」的描绘,避免出现因文化误解而产生的跑题情况。

尤其对原生于中国文化的概念,理解与表现更为精确,得以避免「日本风」与「中国风」混淆,令人啼笑皆非的状况。例如,与Stable Diffusion在中英文输入对应唐装人物风格的Prompts,差异一目了然:


在特定风格的生成中,会原生以中文文化语境为身份主体,进行风格创作,例如对于下面带有「古建筑」的prompt,会默认生成中国古代建筑。在创作风格上更加贴合中文创作者身份。
▽

3. 中英双语,生成效果对齐
AltDiffusion基于Stable Diffusion,通过将原来Stable Diffusion中的CLIP替换成AltCLIP,并且用中英文图文对对模型进行进一步的训练得到。得益于 AltCLIP 强大的语言对齐能力,AltDiffusion 的生成效果在英文上与 Stable Diffusion 很接近,在中英文双语的表现上也体现了一致性。
如「戴帽子小狗」的同义中英文Prompts输入AltDiffusion后,生成画面效果基本对齐,一致性极高:
▽

在对「男孩」的画面增加描述词为「中国男孩」之后,在原小男孩形象基础上,精准调整成典型「中国」孩子,在语言控制生成中展现出极佳语言理解能力和精准的生成表达结果。
▽


打通StableDiffusion原生态
——丰富生态工具与PromptsBook应用,可玩性极佳
特别值得一提的是 AltDiffusion 的生态打通能力:
所有支持Stable Diffusion的工具如Stable Diffusion WebUI,DreamBooth等都可应用在我们的中英双语 Diffusion 模型上,为中文AI创作提供了丰富选择:
1. Stable Diffusion WebUI
一个优秀的文图生成、文图编辑的网页工具;当我们把北大夜景图霍格沃茨(prompt: Hogwarts)化,瞬间即可呈现梦幻的魔法世界;
左滑直通霍格沃茨


2. DreamBooth
通过少量样本对模型进行调试以生成特定的风格的工具;通过这一工具,在AltDiffusion上利用少量中文图片即可生成特定风格,比如「大闹天宫」风格。
▽

3. 充分利用社区Stable Prompts Book
Prompts 对于生成模型非常重要,社区用户通过大量 prompts 尝试,积累出丰富的生成效果案例。这些宝贵的 prompts 经验,对于 AltDiffusion 用户几乎全都适用!
此外,还可以通过混合中英文方式去搭配一些神奇的风格和元素,或继续挖掘对AltDiffusion适用的中文Prompts。
4. 方便中文创作者微调
开源的AltDiffusion提供了中文生成模型的一个基础,大家可以在这个基础上用更多特定领域的中文数据进行模型微调,方便中文创作者表达。
以首个双语 AltCLIP 为基石
——全面增强跨语言三大能力,中英对齐、中文更优,极低门槛
语言理解,图文对齐,跨语言能力,是跨语言研究必备的三种能力。
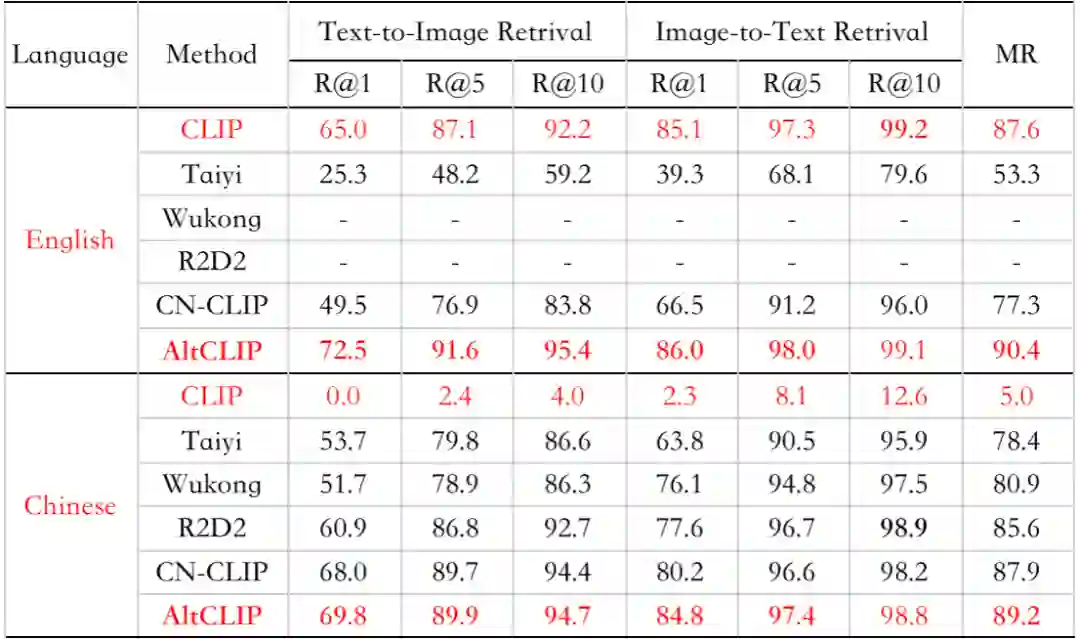
AltDiffusion 的诸多专业级能力,源于 AltCLIP 以创新性换塔思路,在这三大能力上全面增强:与原 CLIP 中英文语言对齐能力大大提高,可以无缝接入 Stable Diffusion 等所有建立在原 CLIP 上的模型和生态工具;同时赋予其强悍的中文能力,在多项数据集取得中文更优效果。(详细解读请参考技术报告)
值得一提的是,这种对齐方法对训练多语言多模态表征模型的门槛大大降低,相对于重新去做中文或者英文的图文对预训练,只需约 1% 的计算资源与图文对数据。
▽
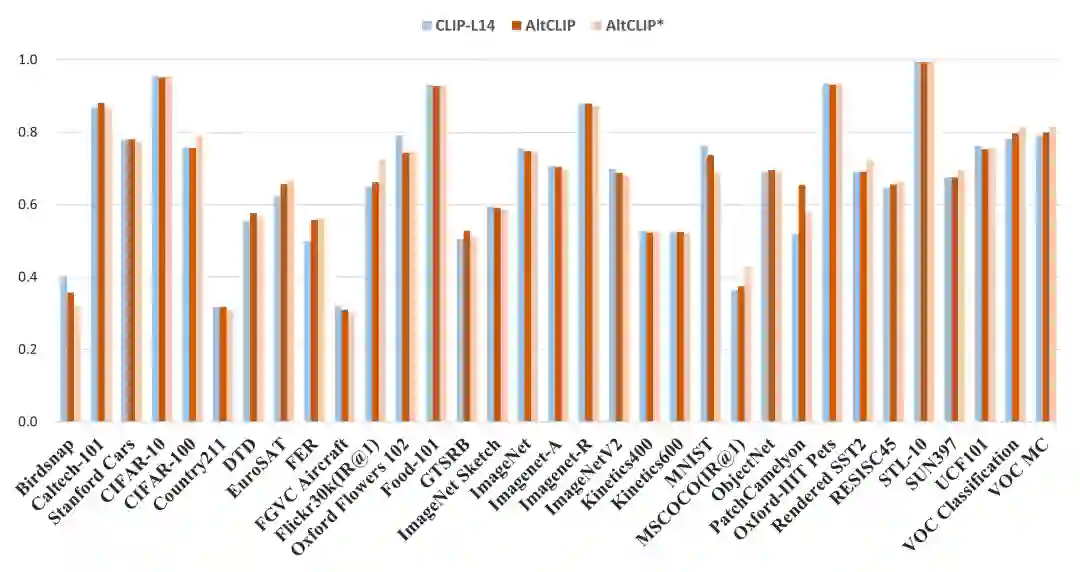
Flicker-30K上表现效果超过原版CLIP
▽
▽