读完本文,轻松玩转数据处理利器Pandas 1.0
选自Medium
2020 年 1 月 9 日 Pandas 1.0.0rc 版本面世,Facebook 数据科学家 Tom Waterman 撰文概述了其新功能。本文助你轻松玩转 Pandas 1.0。

常用数据科学库 Pandas 刚刚年满十二岁,现在已经发布到 1.0.0 版。首个 Pandas 1.0 候选版本显示出,现在的 Pandas 在遇到缺失值时会接收一个新的标量,遵循语义化版本控制(Semantic Versioning)形成了新的弃用策略,网站也经过了重新设计……
pip install --upgrade pandas==1.0.0rc0$ pip --version
pip 19.3.1 from /usr/local/lib/python3.7/site-packages/pip (python 3.7)$ python --version
Python 3.7.5>>> import pandas as pd
>>> pd.__version__
1.0.0rc0
>>> df = pd.DataFrame({
...: 'A': [1,2,3],
...: 'B': ["goodbye", "cruel", "world"],
...: 'C': [False, True, False]
...:})
>>> df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3 entries, 0 to 2
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 A 3 non-null int64
1 B 3 non-null object
2 C 3 non-null object
dtypes: int64(1), object(2)
memory usage: 200.0+ bytes>>> df.to_markdown()
| | A | B | C |
|---:|----:|:--------|:------|
| 0 | 1 | goodbye | False |
| 1 | 2 | cruel | True |
| 2 | 3 | world | False |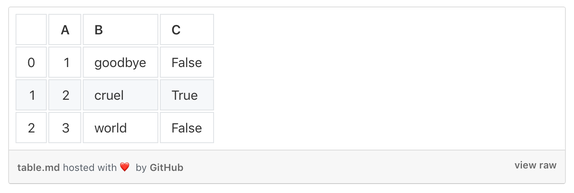
>>> B = pd.Series(["goodbye", "cruel", "world"], dtype="string")
>>> C = pd.Series([False, True, False], dtype="bool")
>>> df.B = B, df.C = C
>>> df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3 entries, 0 to 2
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 A 3 non-null int64
1 B 3 non-null string
2 C 3 non-null bool
dtypes: int64(1), object(1), string(1)
memory usage: 200.0+ bytesdf.select_dtypes("string")
登录查看更多
相关内容





相关VIP内容
相关资讯
相关论文