教师解放新前沿:让机器给作文打分
全球AI+智适应教育峰会
免费门票开放申请!
雷锋网联合乂学教育松鼠AI以及IEEE教育工程和自适应教育标准工作组,于11月15日在北京嘉里中心举办全球AI+智适应教育峰会。美国三院院士、机器学习泰斗Michael Jordan、机器学习之父Tom Mitchell已确认出席,带你揭秘AI智适应教育的现在和未来。
扫码免费注册

计算机智能的发展快速而高效。强大的工具迅速更迭,教师的工作效率也显著提高。其中自动为文章打分的智能软件便应用甚广。作文是大规模语言考试中的必备题型。通过作文可以综合检测应试者运用语言的水平。当今的研究人员正努力研发机器人瞬时为书面文章评分。机器人评分的受益者包含慕课(MOOC)供应者,还有那些在标准考试中含有作文测试的地区等。
关键问题是,计算机能够像文学家一样,识别出作文中微小而关键的那些差别吗?恰恰是这些微小的差别,区分出了普通的好文章和卓越精彩文章之间的差异。电脑能否捕捉到书面交流的关键要素,譬如合理性,道德立场,论证能力,和清晰程度?
自动评分的先驱——埃利斯·佩奇
1966年,计算机体积还很庞大,康涅狄格大学的研究员埃利斯·佩奇(Ellis Page)就率先开始了对自动评分的研究。计算机在那时是相对新颖的技术,主要用来处理最高级的任务。在佩奇同龄人眼中,利用计算机进行文本输入而非计算数据更是新奇的想法。在当时的环境下,不管是从实用的角度、还是从经济成本来看,利用计算机给作文评分这个想法都非常得不切实际。与同代的人相比,佩奇是个眼光真正长远的人。
埃利斯佩奇团队开发出第一套作文自动评分系统PEG(Project Essay Grader)。PEG(Project Essay Grade)、IEA(Intelligent Essay Assessor)和E-rater是国外最具代表性的三种作文自动评分系统。
国外作文自动评分系统述评
作文自动评分是近三年自然语言处理中的热点问题。大规模作文阅卷面临两大难题:其一,阅卷需要耗费大量人力、物力等资源;其二,评判作文质量具有很强的主观性,阅卷的信度和效度不强。近几十年来,随着计算机硬件和软件性能快速提高,自然语言处理等技术获得了长足的发展,国外一批作文自动评分系统相继问世,这两个长期困扰大规模作文阅卷的难题有望得到解决。
(一)PEG——一个重语言形式的评分系统
PEG于1966年由美国杜克大学的Ellis Page等人开发。PEG的设计者们认为,计算机程序没有必要 理解作文内容,大规模考试中尤其如此。因此,他们在其网站上公开申明:“PEG 不能理解作文的内容”。在PEG的开发者看来,作文质量的诸要素是作文的内在因素,无法直接测量,因此,最为合乎逻辑的方法是从作文文本中提取一些能够间接反映作文质量的文本表层特征项。
概括起来,PEG的技术大体包括两方面:其一, PEG使用的统计方法是多元线性回归,以此来确定各变量的beta值,这样,基于训练集作文而构建的统计模型便可以用来为新的作文进行自动评分。这一技术合理而容易理解,后期出现的作文自动评分系统大多采用这一技术。其二,自然语言处理技术是PEG提取变量的主要方法。基于这两种技术,PEG取得了很好的评分效果。
(二)IEA——一个重内容的评分系统
IEA是一种基于潜伏语义分析的作文自动评分系统,由美国科罗拉多大学的ThomasLandauer等学者开发。与PEG显著不同的是,IEA的设计者们在其网站上申明:“IEA是唯一能够测量语义和作文内容的程序”。据IEA的设计者们报告,潜伏语义分析主要分析文本的内容和学生作文中所传达的知识,而不是作文的风格或语言。
将潜伏语义分析用于学生作文自动评分时,待评分的作文与预先选定的范文(训练集)被视作为矢量, 对矢量进行比较之后,可以得到每一篇待评分作文与范文在内容上的相似度得分。该得分被直接视为机器评分或经过转换后得到机器评分。
(三)E-rater——一个模块结构的混合评分系统
E-rater是由美国教育考试处于20世纪90年代开发,其目的是评估GMAT考试中的作文质量。据Burstein et a.l(2001)、Cohen et a.l(2003)和Valenti et a.l(2003)的描述,E-rater自1999 年以来已经进入操作阶段,至2003年,共评定作文 750,000篇。
E-rater的开发者们声称,他们的作文评分系统利用了多种技术,其中包括统计技术、矢量空间模型技术和自然语言处理技术(Valenti et a.l2003)。凭借这些技术,E-rater不光能够像PEG那样评判作文的语言质量,还能够像IEA那样评判作文的内容质量。除此之外,E-rater还对作文的篇章结构进行分析。
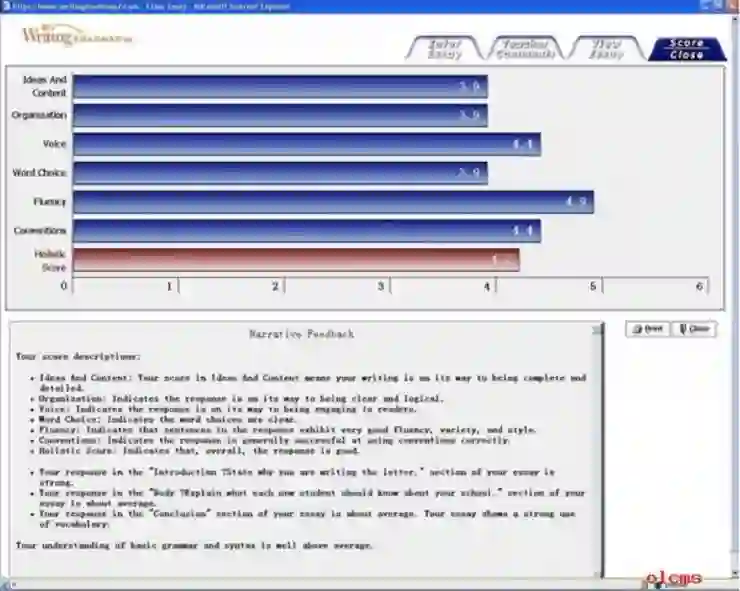
国内主要英语作文自动评价工具软件
在国内,业已颁布的《国家中长期教育改革和发展规划纲要(2010-2020年)》明确指出,信息技术对教育发展具有革命性的影响,必须给于高度重视。到2020年,全国范围内应该力争基本建成覆盖城乡各级各类学校的教育信息化体系,以促进教育内容、教学手段和方法现代化。就受众群体庞大的英语教学领域而言,国内关于英语作文自动评价系统的研究起步晚,缺乏系统性的综述研究。
(一)句酷批改网
由北京词网科技有限公司研发,于2011年4月开始展开大规模使用。它是一个基于语料库和云计算技术的英语作文在线自动批改服务网站。批改网的核心算法是计算学生作文和标准语料库之间的距离,再通过一个映射将距离转化成作文分数和评语。核心技术点是将每一篇输入的作文分析成可测量的192个维度,分析过程充分利用了先进的自然语言技术和机器学习的方法,每篇作文先被自动切分成句子,然后对每个句子进行深度的语义分析,从中抽取词、搭配、词组等结构化单元。主要功能包括:分数即刻显现、图文报表式作文分析结果、错误自动批改、点评细致入微、阶段性进度报告、抄袭检测等。
批改网是完全自主研发的国产软件,从核心引擎到批改应用都是完全自主知识产权的。它体现写作教学的多样性,鼓励学生的自主性学习、探索性学习、团队式学习、研究型学习等教与学新模式。
(二)冰果英语智能作文评阅系统
杭州增慧网络科技有限公司联合浙江大学、外语教学与研究出版社,以及中外人工智能专家队伍,依据语言教学理论、计算机网络教育技术、大规模数据挖掘技术,研发出这一个性化智能化的作文评阅软件。它可以即时给出作文评分,并从词汇、语法、文风、内容等方面给出反馈。但是,该系统目前无法做到用户同一篇作文多次反复修改,多次提交给系统,并得到系统的即时评阅和反馈。
(三)TRP教学资源平台
经过对一线教师的调研及需求分析,高等教育出版社与清华大学杨永林教授的科研团队合作研究,2010年10月正式对外发布了《体验英语写作教学资源平台》。 2012年3月,该平台的升级版产品《TRP教学资源平台》面世。它根据写作教学需求,将数字化、网络化与区域化教学平台进行了有机的整合,并涵盖了资源建设、平台构建、写作学习、句型练习、语法测验、作文评分、写作研究、评语生成、作为考试等功能。为高校英语教学的进一步改革提供了“专本硕博,四级贯通”的可操作平台。特别一提的是,学术写作是该写作软件系统的特色版块,从这一点来讲,TRP教学资源平台似乎对于研究型高校的学习者来说具有更加特殊的意义。
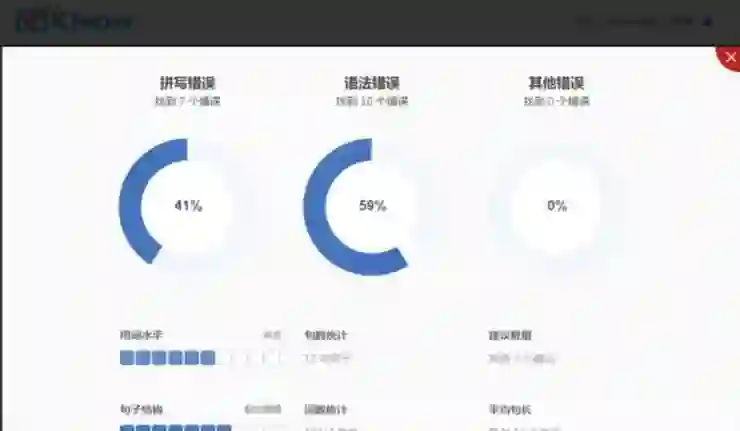
国内中文作文自动评价工具软件概述
根据作文自动评分的原理,可以得到计算机评分的工作机制:首先提取出反映写作水平的特征,然后利用这些特征和数学模型计算出分数。并且确保这个分数最大程度的接近人工评分的结果。
汉语文字的计算机识别及加工能技术难题需要计算机领域的专家来攻克,而汉语的计算机自然语言处理技术有了突飞猛进的发展。例如由于中文词语之间没有空格分割,使用计算机进行分词是进行自动评分研究需要解决的首要问题。随着中文自然语言处理研究的发展,目前这一困难基本得到解决。中国科学院计算技术研究所在多年研究基础上,研制出了基于多层隐马模型的汉语词法分析系统ICTCLAS(Institute of Computing Technology, Chinese Lexical Analysis System),该系统不仅完全具备了中文分词的功能,还有词性标注和未登录词识别的功能。ICTCLAS分词的正确率高达97.58%(最近的973专家组评测结果)。另外北京大学、北京语言大学都有汉语自然语言处理工具成功开发,为汉语作文自动评分研究打下了基础。
自动评分很好地做到了作文评价的客观化,可以做到在不同的时间地点,在不同的计算机环境里面对于同一篇作文的评价结果完全相同。使用这些系统进行作文评分,不仅提高了作文评价效率、降低了人工成本,而且从根本上消除了评分者之间的不一致。可以说,使用计算机进行自动评分是评价科学化发展的必由之路,是提高作文评分准确性和评分效率的最有效途径。在美国Erater已经成功的在ETS组织的托福等考试中应用,而日本Jess研制的目的就是处理日本大学入试的作文评分。最近台湾也研发出了一套“中文写作自动化评分系统”(ACES),该软件能自动分析初中基准测试考生的作文程度,并给于6个等级的评分。
人工与智能,效率与质量的较量
当今时代,利用计算机自动评分的需求正在猛增。在人工审核流程中,每篇文章必须要有两名教师打分,这样的批阅成本很高,含有写作部分的标准化测试批阅成本也愈发昂贵。这种高昂的成本已经致使许多州在标准考试中,放弃了重要的写作测试。目前,自动评分系统还处在人机耦合的阶段。许多低年级的标准化考试使用自动评分系统,已经带来不错的收效。然而,孩子们的命运并非完全掌握在计算机手中。大多数情况下,在标准化测试中,机器人评分员只是取代了其中一位必要的评分员。如果自动评分员的意见截然不同,这样的文章就会被标记,并转发给另一位人工评分员作进一步评估。这个步骤的目的是保证评估质量,同时也有助于提高自动评分技能。
EdX总裁Anant Agarwal称,智能自动评分的优点不仅仅是能节省宝贵的时间。新技术所实现的即时反馈对学习也有积极影响。当今,人工给作文评分要花费好几天、甚至是好几周的时间才能完成,但是有了即时反馈,学生对自己的文章记忆犹新,可以立即弥补弱项,而且效率更高。
机器学习软件刚开始应用时,教师必须将已经评好的几篇文章输入系统,作为好文章和坏文章的示例。随着越来越多文章输入,软件就越来越擅长这种评分工作,最终几乎就能提供专门的即时反馈。Anant Agarwal称,需要做的工作还有很多,不过自动评分的质量已经很快接近真正教师的评分。随着更多学校的参与,EdX系统的发展越来越快。截至今天,已有11所重点大学对这款不断发展的评分软件贡献了力量。
自动评分的应用效果及发展前景
为了改善这种趋势,2012年,威廉和弗洛拉休利特基金会(William and Flora Hewlett Foundation)赞助了一项自动评分的竞赛,以数千篇作文为样本,用六万美金作为奖励,鼓励能智能取代教师评分的最佳方案。休利特基金会教育项目负责人芭芭拉·周表示:“我们听说机器算法已经达到和人工评分同样的水平,但我们希望创建一个中立且公平的平台来评估供应商的各种声明。事实证明,那些说法并非炒作。”
自动评分的发展也吸引了慕课供应商的极大兴趣。影响线上教育普及的最大问题之一就在于个人评估文章。一位教师可以为5000名学生提供授课资源,但却不能对每位学生单独进行评估。有人说现行教育体制已不完善,而解决这一问题正是向打破这种体制所迈出的一大步。在过去短短几年中,评分软件的发展突飞猛进,现在的评分软件已可以在大学中上线测试使用。其中一个领先者就是慕课供应商EdX,同时也是哈佛和麻省理工旨在提高线上教育的联合发起者。
休斯顿大学大学教育学院院长Mark Shermis教授被视为世界上自动评分领域的顶尖专家之一。在2012年,他指导了休利特竞赛,对参赛者的表现印象非常深刻。154个团队参加了竞赛,一万六千多篇文章拿来做了对比。冠军团队与人工评分者的一致度高达81%。Shermis的意见非常积极,他表示这项技术肯定会在未来的教育中占据一席之地。从这次比赛以来,自动评分领域的研究已经取得了积极进展。
自动评分目前仍有几项瓶颈和技术局限
(一)评分标准未统一
自动评分系统还没有科学深入地研究人类分级机之间的评估差异,且个体间的差异性很可能非常大。很明显的是,从最初主要依赖计算字数、检测句子和单词复杂性和结构的简单工具,自动分级技术蒸蒸日上,有了很大的进展。
自动作文评分系统供应商是如何提出各种算法的这一问题深深隐藏于知识产权规章背后。然而,莱斯·派勒尔曼(Les Perelman),长期怀疑论者和麻省理工学院前本科生论文处主任有了一些答案。他花费十年时间用各种方法恶搞不同的自动分级软件,并且在某种程度上发动了一场有关全面抵制这些系统的运动。分级软件必须将不同文章进行比较,区分重点与非重点部分,然后将文章压缩至一个数字以进行评级。相应的,文章必须是在一个完全不同的主题下与不同文章具有可比性。谷歌在比较不同目标文本和图片与不同搜索术语的匹配度时使用了相似的策略。问题在于谷歌应用了数百万数据样本进行估值。而一所学校最多只能输入几千篇文章。只有拥有庞大的数据库,这个问题才能逐渐得到解决。
(二)基于规则的弊端
由于计算机无法读取,解决过度拟合最可行的方法是为计算机明确指定一套具体的规则,来检测文本是否讲得通。这一方法在其他软件上都行得通。目前,自动评级供应商大量投入来制定这样的规则,因为要制定出一条检测诸如论文这样创造性文本质量的规则十分困难。计算机倾向于用常见的方式解决问题:计算。
在自动评分系统中,例如,评分预测器可以是句子长度、单词数量、动词数量、复杂单词的数量等。这些规则是否能做出合理的评估?至少派勒尔曼不这样认为。他说,预测规则通常非常死板局限,限制了评估的质量。例如,他发现:
—长篇文章的评级会比短篇的评级高(自动评级倡导者马克舍米斯教授认为这只是个巧合。)
—同复杂思想相关的具体词汇,例如“并且”“然而”,都会使文章得到更高的评级。
—使用“贪婪”这种复杂词汇会比使用“贪心”这种简单词汇评级高。
他发现规则很难应用或者根本没有应用的另一些例子是这个软件不能分辨真实性。
(三)信度和效度有待提高
作文自动评分的目的是利用多学科技术有效地模拟人工评分,以达到快速评定作文质量的目的。因此,在对计算机评分模型进行训练时,训练集作文人工评分的信度至关重要。只有有效地模拟具有较高信度的人工评分,计算机评分才有意义。根据Barrett(2001)和Stemler(2004)的研究,评分员间的信度达到r=0.70左右才是可以接受的,但现有作文评分系统在对训练集作文进行人工评分时常常达不到这样的信度要求,可能使得计算机评分模型很难模拟到人工评分的精髓。
评价对学生作文的评分是否合理,所需考察的另一个方面是评分的效度。对作文进行评分一般至少需要从作文的语言质量、内容质量和篇章结构质量三个主要方面对作文的整体质量加以衡量。自动评分系统在评分过程中并未能够很好地兼顾这三个主要方面,因而评分的结构效度值得质疑。PEG虽然对作文的语言质量有着较强的分析能力,但忽略了作文的内容质量和篇章结构质量,因而其评分结果存在较大的效度问题。与此相类似,IEA突出了评分过程中作文内容的重要性,但忽略了作文的语言质量和篇章结构质量,显然也存在较大的效度问题。与这两种系统相比,E-rater虽然以其模块结构兼顾了作文质量的三个主要方面,但每个模块的分析能力尚可进一步提高。
参考:
AI In Education — Automatic Essay Scoring
https://edx-ora-2.readthedocs.io/en/latest/architecture/ai_grading.html
◆ ◆ ◆
推荐阅读
17 位行业领袖:我们眼中的北京安博会
亚马逊继续“激进” :Q3吐出超10倍净利
全球AI+智适应教育峰会
大会官网(免费门票开放申请):https://gair.leiphone.com/gair/aiedu2018
雷锋网联合乂学教育松鼠AI以及IEEE教育工程和自适应教育标准工作组,在嘉里中心举办全球AI+智适应教育峰会。
确认出席的嘉宾
美国三院院士、机器学习泰斗Michael Jordan、机器学习之父Tom Mitchell、SRI斯坦福国际研究院副总裁Robert Pearlstein等顶尖学者;
VIPKID、作业帮、沪江网等国内著名教育创业公司创始人;
Knewton、Byju's、DreamBox、Duolingo、ALEKS、AltSchool等国外最具影响力的AI智适应教育公司。

免费门票开放中,点击“阅读原文”立即申请!



