什么是解耦表示学习?使用beta-VAE模型探究医疗和金融问题

作者 | Alexandr Honchar
译者 | 大鱼
编辑 | Rachel、琥珀
出品 | AI科技大本营(id:rgznai100)
【导语】本文对传统的人工数学建模和机器学习的优缺点进行了介绍和比较,并介绍了一种将二者优点相结合的方法——解耦表示学习。之后,作者利用 DeepMind 发布的基于解耦表示学习的 beta-VAE 模型,对医疗和金融领域的两个数据集进行了探索,展示了模型效果,并提供了实验代码。
实验中 GitHub 项目地址:
https://github.com/Rachnog/disentanglment
这篇文章会对传统数学建模与机器学习建模之间的联系进行讨论。传统数学建模是我们在学校里都学过的建模方法,该方法中,数学家们基于专家经验和对现实世界的理解进行建模。而机器学习建模则是另一种完全不同的建模方式,机器学习算法以一种更加隐蔽的方式来描述一些客观事实,尽管人类并不能够完全理解模型的描述过程,但在大多数情况下,机器学习模型要比人类专家构建的数学模型更加精确。当然,在更多应用领域(如医疗、金融、军事等),机器学习算法,尤其是深度学习模型并不能满足我们需要清晰且易于理解的决策。
本文会着重讨论传统数学建模和机器学习建模的优缺点,并介绍一个将两者相结合的方法 —— 解耦表示学习 (Disentangled Representation Learning)。
如果想在自己的数据集上尝试使用解耦表示学习的方法,可以参考 Github 上关于解耦学习的分享,以及 Google Research 提供的关于解耦学习的项目代码。
深度学习存在的问题
由于深度学习技术的发展,我们在许多领域都对神经网络的应用进行了尝试。在一些重要的领域,使用神经网络确实是合理的,并且获得了较好的应用效果,包括计算机视觉、自然语言处理、语音分析和信号处理等。在上述应用中,深度学习方法都是利用使用线性和非线性转换对复杂的数据进行自动特征抽取,并将特征表示为“向量”(vector),这一过程一般也称为“嵌入”(embedding)。之后,神经网络对这些向量进行运算,并完成相应的分类或回归任务:
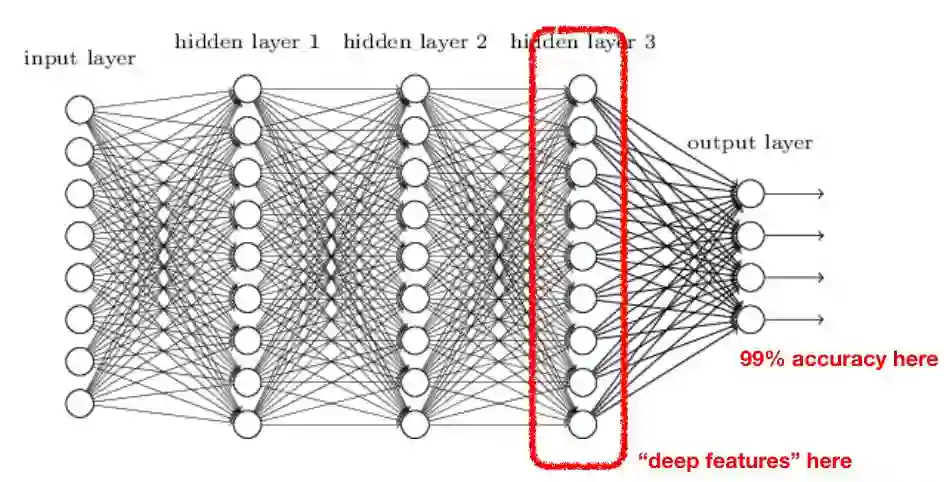
从特征提取和准确度来看,这种 “嵌入”的方法非常有效,但在许多方面也存在不足:
可解释性:嵌入所使用的N维向量无法对模型分析的原理和过程进行很好的解释,只有通过逆向工程才能找到输入数据中对分析影响更大的内容。
数据需求量庞大:如果只有 10~100 个样本,深度学习无法使用。
无监督学习:大多数深度学习模型都需要有标签的训练数据。
零样本学习:这是一个很关键的问题,基于一个数据集所训练出的神经网络,若不经过重新训练,很难直接应用在另一个数据集上。
对象生成:除了 GANs(生成对抗网络)以外,其他模型都很难生成一个真实的对象。
对象操作:难以通过嵌入调整输入对象的具体属性。
理论基础:虽然我们已经掌握了比较通用的逼近理论,但这还不够。
这些问题很难用机器学习框架来解决,但在最近,我们取得了一些新的进展。
数学建模的优势
在 20 年、50 年 甚至 100 年以前,大多数数学家都没有遇到过上述问题。其中原因在于,他们主要关注数学建模(mathematical modeling),并通过数学抽象来描述现实世界中的对象和过程,如使用分布、公式和各种各样的方程式。在这个过程中,数学家定义了我们在标题中提到的常微分方程(ordinary differential equations, ODE)。我们通过对比深度学习存在的问题,对数学建模的特点进行了分析。需要注意的是,在下面的分析中,“嵌入”代表数学模型的参数,如微分方程的自由度集合。
可解释性:每个数学模型都是基于科学家对客观事物的描述而建立的,建模过程包含数据家对客观事物的描述动机和深入理解。例如,对于物理运动的描述, “嵌入” 包括物体质量、运动速率和坐标空间,不涉及到抽象的向量。
数据需求量大:大多数数学建模上的突破并不需要基于巨大的数据集进行。
无监督学习:对数学建模来说也不适用。
零样本学习:一些随机微分方程(如几何布朗运动)可以应用于金融、生物或物理领域,只需要对参数进行重新命名。
对象生成:不受限制,对参进行采样即可。
对象操作:不受限制,对参数进行操作即可。
理论基础:上百年的科学基础。
我们没有使用微分方程解决所有问题的原因在于,对于大规模的复杂数据来说,微分方程的表现与深度学习模型相比要差得多,这也是深度学习得到飞速发展的原因。但是,我们仍然需要人工的数学建模。
将机器学习与基于人工的建模方法相结合
如果在处理复杂数据时,我们能把表现较好的神经网络和人工建模方法结合起来,可解释性、生成和操作对象的能力、无监督特征学习和零样本学习的问题,都可以在一定程度上得到解决。举个例子,视频1中呈现的是对于人像的特征提取方法。
对于微分方程和其他人工建模方法来说,图像处理很难进行,但通过和深度学习进行结合,上述模型允许我们进行对象的生成和操作、可解释性强,最重要的是,该模型可以在其他数据集上完成相同的工作。该模型唯一的问题是,建模过程不是完全无监督的。另外,对于对象的操作还有一个重要的改进,即当我改变 ”胡须“ 这一特征时,程序自动让整张脸变得更像男人了,也就是意味着,模型中的特征虽然具有可解释性,但特征之间是相关联的,换句话说,这些特征是耦合在一起的。
β -VAE
有一个方法可以帮助我们实现解耦表示,也就是让嵌入中的每个元素对应一个单独的影响因素,并能够将该嵌入用于分类、生成和零样本学习。该算法是由 DeepMind 实验室基于变分自编码器开发的,相比于重构损失函数(restoration loss),该算法更加注重潜在分布与先验分布之间的相对熵。
若想了解更多细节,可阅读beta-VAE的论文(https://openreview.net/forum?id=Sy2fzU9gl);也可参考这个视频2中的介绍,详细解释了 beta-VAE 的内在思想,以及该算法在监督学习和强化学习中的应用。
beta-VAE 可以从输入数据中提取影响变量的因素,提取的因素包括物理运动的方向、对象的大小、颜色和方位等等。在强化学习应用中,该模型可以区分目标和背景,并能够基于已有的训练模型在实际环境中进行零样本学习。
实验过程
我主要研究医疗和金融领域的模型应用,在这些领域的实际问题中,上述模型能够在很大程度上解决模型解释性、人工数据生成和零样本学习问题。因此在下面的实验中,我使用 beta-VAEs 模型对心电图(ETC)数据和和比特币(BTC)的价格数据进行了分析。该实验的代码在 Github上可以找到。
首先,我使用veta-VAE(一个非常简单的多层神经网络)对PTB诊断数据中的心电图数据进行了建模,该数据包含三类变量:心电图图表,每个人随着时间变化的脉搏数据,以及诊断结果(即是否存在梗塞)。在 VAE 训练过程中,epoch 大小设置为 50,bottleneck size 设置为 10,学习率为 0.0005,capacity 参数设置为 25(参数设置参考了这个GitHub项目)。模型的输入是心跳。经过训练,该模型学习到了数据集中影响变量的实际因素。
下图展示了我使用其中一个单一特征对心跳数据进行操作的过程,其中黑线代表心跳,使用的特征数据值从 -3 逐渐增大至 3。在这一过程中,其他特征始终保持不变。不难发现,第 5 个特征对心跳形式的影响很大,第 8 个代表了心脏病的情况(蓝色心电图代表有梗塞症状,而红色则相反),第 10 个特征可以轻微地影响脉博。
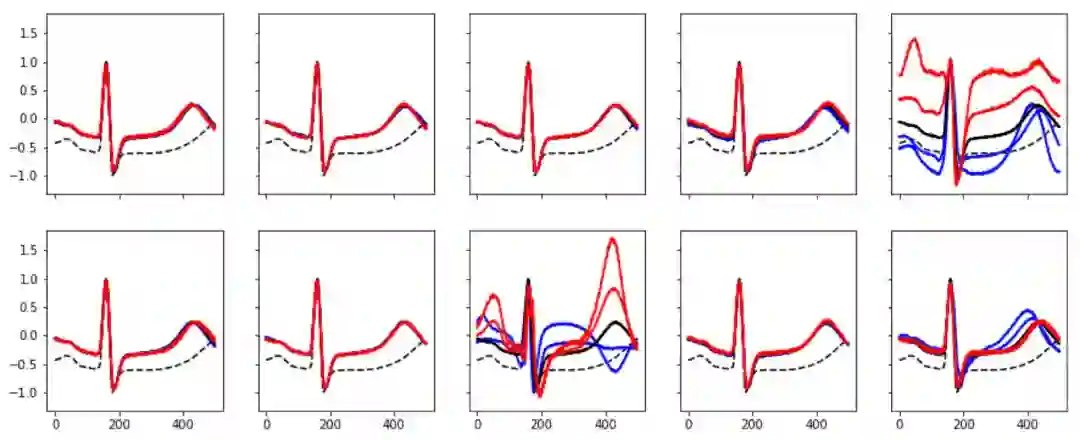
图:对心电图的心跳进行解耦
正如预期的一样,金融数据的实验效果没有这么明显。模型的训练参数设置与上一实验相似。使用的数据为 2017 年收集的比特币价格数据集,该数据集包含一个时间长度为 180 分钟的比特币价格变化数据。预期的实验效果为使用 beta-VAE 学习一些标准的金融时间序列模型,如均值回归的时间序列模型,但实际很难对所获得的表示进行解释。在实验结果中可以发现,第 5 个特征改变了输入的时间序列的趋势,第 2、4、6 个特征增加/减少了时间序列上不同阶段的波动,或者说使其更加趋于稳定或动荡。
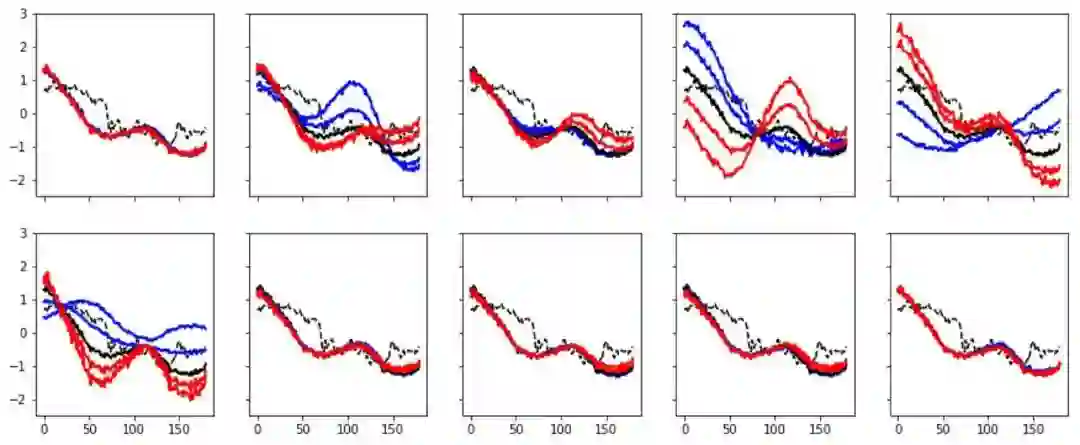
图:对比特币的收盘价格进行解耦
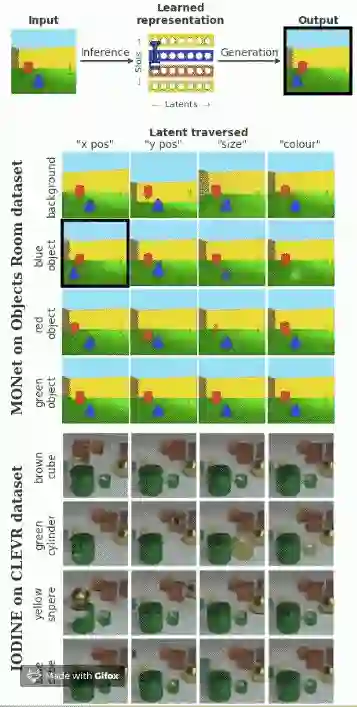
多个对象的解耦
假设在图像中包含多个对象,我们想要找出每一个对象的影响因素。下面的动图展示了模型的效果。

总结
下面针对于机器学习存在的问题列表对 beta-VAE 模型进行总结:
可解释性:特征完全可解释,我们只需要对每个具体嵌入的元素进行验证。
数据需求量大:由于该模型属于深度学习框架,数据需求量依然较大。
无监督学习:可以实现完全的无监督学习。
零样本学习:可以进行,在文中展示的强化学习应用就属于这一类。
对象生成:和普通的 VAE 一样易于对参数进行采样。
对象操作:可以轻松操作任何感兴趣的变量。
理论基础:有待研究。
上文的模型几乎具备了数学建模的全部优质特性,也具有深度学习在分析复杂数据时的高准确度。那么,如果能使用完全无监督的方式,从复杂数据中学习到如此好的表示结果,是不是意味着传统数学建模的终结?如果一个机器学习模型就可以对复杂模型进行构建,而我们只需要进行特征分析,那还需要基于人工的建模吗?这个问题还有待讨论。
这里列出了文中视频的网址链接和百度网盘链接,供参考:
视频1:
链接:https://youtu.be/O1by05eX424
百度网盘:链接: https://pan.baidu.com/s/11qsgCVlRF0R4jm7ZLlzF2w 提取码: f76s
视频2:
链接:https://youtu.be/yV698Fi2XzE
百度网盘:链接: https://pan.baidu.com/s/153FBz8YWaw3PWrqJAbPj2A 提取码: ee8v
原文链接:
https://towardsdatascience.com/gans-vs-odes-the-end-of-mathematical-modeling-ec158f04acb9
(本文为 AI科技大本营编译文章,转载请微信联系 1092722531)
◆
CTA核心技术及应用峰会
◆
5月25-27日,由中国IT社区CSDN与数字经济人才发展中心联合主办的第一届CTA核心技术及应用峰会将在杭州国际博览中心隆重召开,峰会将围绕人工智能领域,邀请技术领航者,与开发者共同探讨机器学习和知识图谱的前沿研究及应用。
更多重磅嘉宾请识别海报二维码查看,目前会议早鸟票发售中(原票价1099元),点击阅读原文即刻抢购。添加小助手微信15101014297,备注“CTA”,了解票务以及会务详情。

推荐阅读




