将sklearn训练速度提升100多倍,美国「返利网」开源sk-dist框架
选自Medium
作者:Evan Harris
机器之心编译
在本文中,Ibotta(美国版「返利网」)机器学习和数据科学经理 Evan Harris 介绍了他们的开源项目 sk-dist。 这是一个分配 scikit-learn 元估计器的 Spark 通用框架,它结合了 Spark 和 scikit-learn 中的元素,可以将 sklearn 的训练速度提升 100 多倍。
项目地址:https://github.com/Ibotta/sk-dist

import timefrom sklearn import datasets, svm
from skdist.distribute.search import DistGridSearchCV
from pyspark.sql import SparkSession # instantiate spark session
spark = (
SparkSession
.builder
.getOrCreate()
)
sc = spark.sparkContext
# the digits dataset
digits = datasets.load_digits()
X = digits["data"]
y = digits["target"]
# create a classifier: a support vector classifier
classifier = svm.SVC()
param_grid = {
"C": [0.01, 0.01, 0.1, 1.0, 10.0, 20.0, 50.0],
"gamma": ["scale", "auto", 0.001, 0.01, 0.1],
"kernel": ["rbf", "poly", "sigmoid"]
}
scoring = "f1_weighted"
cv = 10
# hyperparameter optimization
start = time.time()
model = DistGridSearchCV(
classifier, param_grid,
sc=sc, cv=cv, scoring=scoring,
verbose=True
)
model.fit(X,y)
print("Train time: {0}".format(time.time() - start))
print("Best score: {0}".format(model.best_score_))
------------------------------
Spark context found; running with spark
Fitting 10 folds for each of 105 candidates, totalling 1050 fits
Train time: 3.380601406097412
Best score: 0.981450024203508
该示例说明了一个常见情况,其中将数据拟合到内存中并训练单个分类器并不重要,但超参数调整所需的拟合数量很快就会增加。以下是运行网格搜索问题的内在机制,如上例中的 sk-dist:
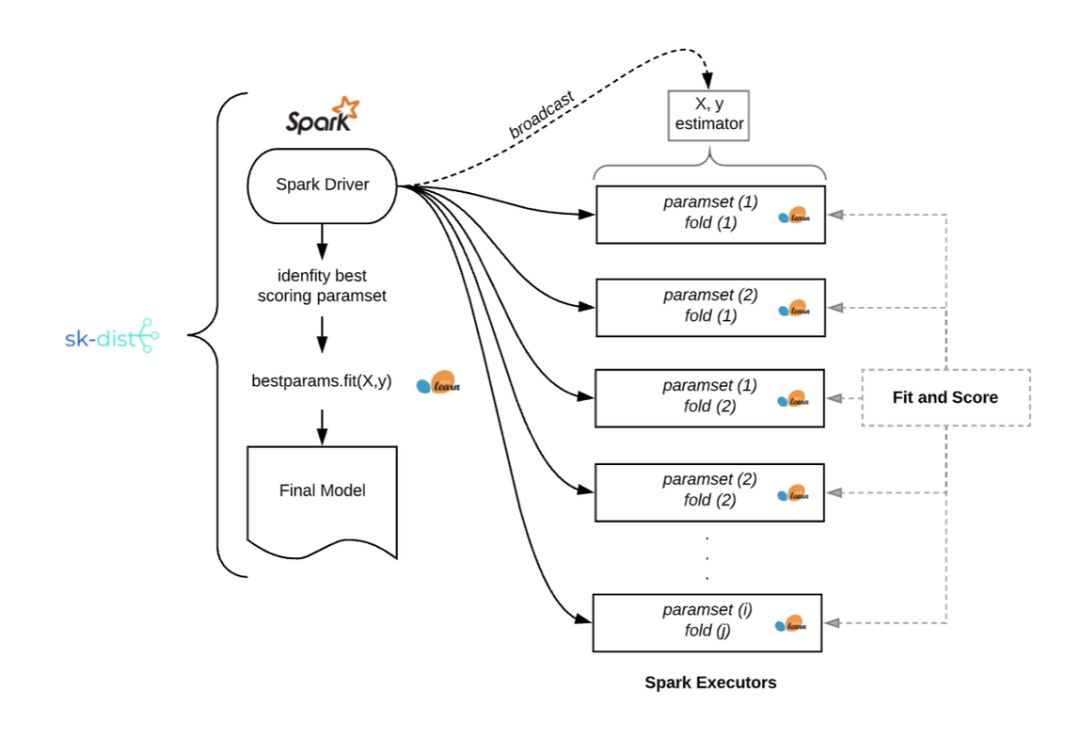
使用 sk-dist 进行网格搜索
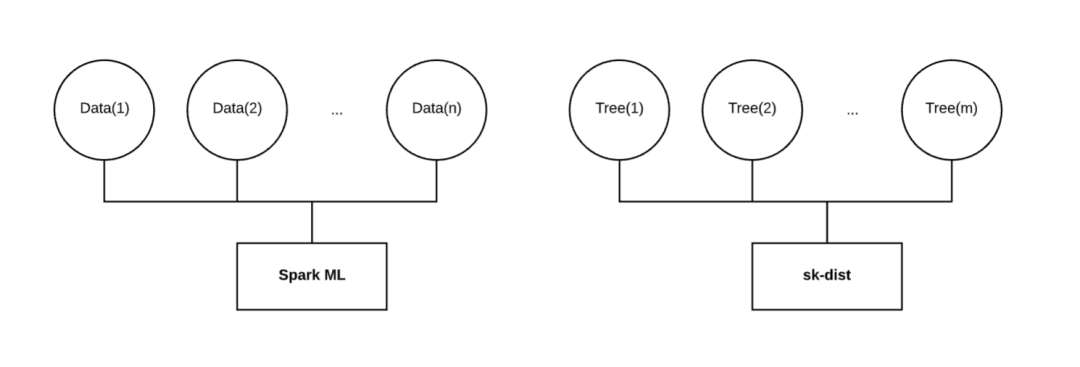
传统机器学习 :广义线性模型、随机梯度下降、最近邻算法、决策树和朴素贝叶斯适用于 sk-dist。这些都可在 scikit-learn 中实现,可以使用 sk-dist 元估计器直接实现。
中小型数据 :大数据不适用于 sk-dist。请记住,训练分布的维度是沿着模型变化,而不是数据。数据不仅需要适合每个执行器的内存,还要小到可以广播。根据 Spark 配置,最大广播大小可能会受到限制。
Spark 定位与访问:sk-dist 的核心功能需要运行 Spark。对于个人或小型数据科学团队而言,这并不总是可行的。此外,为了利用 sk-dist 获得最大成本效益,需要进行一些 Spark 调整和配置,这需要对 Spark 基础知识进行一些训练。
原文地址:https://medium.com/building-ibotta/train-sklearn-100x-faster-bec530fc1f45
登录查看更多
相关内容

Scikit-learn项目最早由数据科学家David Cournapeau 在2007 年发起,需要NumPy和SciPy等其他包的支持,是Python语言中专门针对机器学习应用而发展起来的一款开源框架。
专知会员服务
117+阅读 · 2019年12月6日
Arxiv
5+阅读 · 2018年7月21日
Arxiv
5+阅读 · 2018年4月5日
Arxiv
5+阅读 · 2018年4月3日
Arxiv
3+阅读 · 2018年2月20日




相关VIP内容
专知会员服务
117+阅读 · 2019年12月6日
相关资讯
相关论文
Arxiv
5+阅读 · 2018年7月21日
Arxiv
5+阅读 · 2018年4月5日
Arxiv
5+阅读 · 2018年4月3日
Arxiv
3+阅读 · 2018年2月20日