预热 | 英特尔通过预测变量实现策略性强化学习,夺冠 Doom 游戏竞赛(ICLR 2017)
AI科技评论按:ICLR 2017 将于4月24-26日在法国土伦举行,届时AI科技评论的编辑们也将前往法国带来一线报道。在这个深度学习会议举办之前,AI科技评论也将围绕会议议程及论文介绍展开一系列的覆盖和专题报道。
尽管目前强化学习(Reinforcenment learning)已经取得了重大的进展,但是依然存在两个关键性挑战。
一个是在复杂和动态的三维环境下从原生的感觉输入中实现感觉运动控制
(Sensorimotor control),以实现直接从经验中进行学习;
另一个则是获得可以灵活部署以实现大量动态目标任务的通用技能。
来自英特尔实验室(Intel Labs)的两名研究员提出了一种旨在辅助进步的感觉运动控制方法,以克服强化学习的两大挑战。以下为AI科技评论对其论文部分内容的编译。

论文摘要
来自英特尔实验室(Intel Labs)的两名研究员Alexey Dosovitskiy和Vladlen Koltum提出了一种在沉浸式环境中实现感觉运动控制(Sensorimotor control)的方法。据悉,该方法有效地综合利用了高维度的感官流(high-dimensional sensory stream)和较低维度的测量流(lower-dimensional measurement stream)。
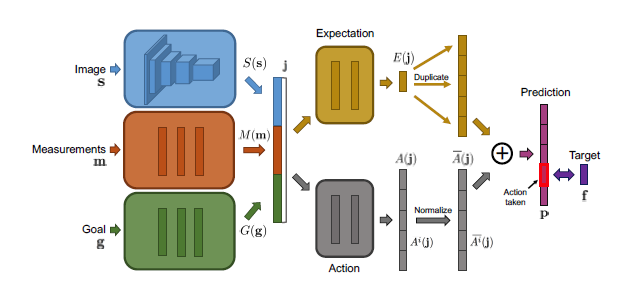
图1:网络结构。s表示图像数据,m表示测量,g表示目标。s,m,g首先通过三个输入模块分别进行处理。然后这些输入模块的输出结果将被连接成一个联合表示j。之后联合表示j被送入了两个并行的计算流进行单独处理,这两个计算流分别用于预测测量期望E(j)和归一化动作条件差异。最后两个计算流的输出将被组合到一起以获得针对每个动作的最终预测。
这些流的时间结构提供了丰富的监控信号,这使得可以通过与环境交互的方式训练运动控制模型。该模型通过监督学习技术进行训练,但是没有用到外部监督。它从来自于复杂三维环境的原始感官输入中学习动作。该方案使得模型在训练过程中不用设定固定的学习目标,并且在测试的时候可以探索动态变化的目标。
据悉,研究员们在经典的第一视角游戏——Doom所提供的的三维模拟环境中进行了大量的实验。而实验结果表明,英特尔实验室研究员所提出的方法优于先前提出的其它复杂方法,这一点在具有挑战性的任务中体现得更加明显。实验结果还表明训练好的模型在环境与目标之间具有很好的泛化能力。除此之外,通过该方法训练出来的模型还赢得了Full Deathmatch track of the Visual Doom AI Competition的胜利,该竞赛是在一个对于模型而言完全陌生的环境下举办的。
论文结果展示
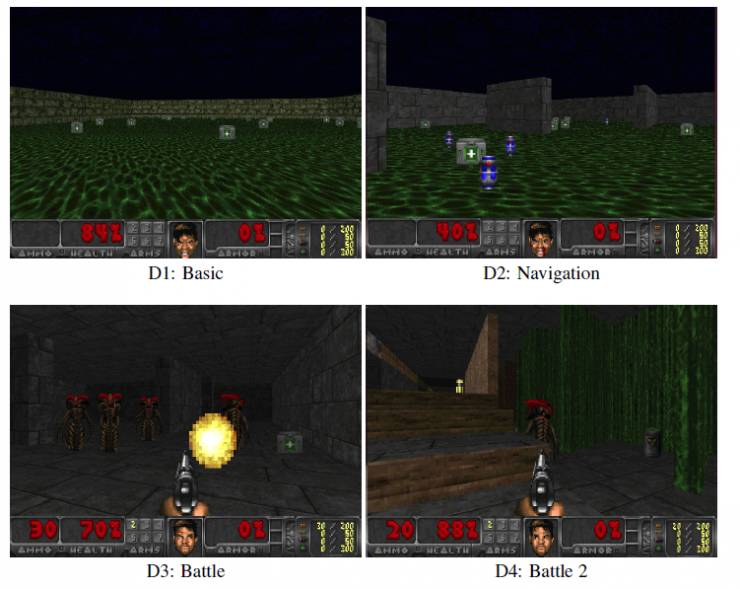
图2:展示了来自于四个场景的样例。D1展示了在一个正方形房间里收集医疗包(“Basic”)。D2展示了在迷宫中收集医疗包并且还要避开毒药(“Navigation”)。D3展示了在迷宫中收集医疗包和弹药并同时攻击敌人(“Battle”)。D4展示了在一个更加复杂的迷宫中收集医疗包和弹药并同时攻击敌人(“Battle 2”)。
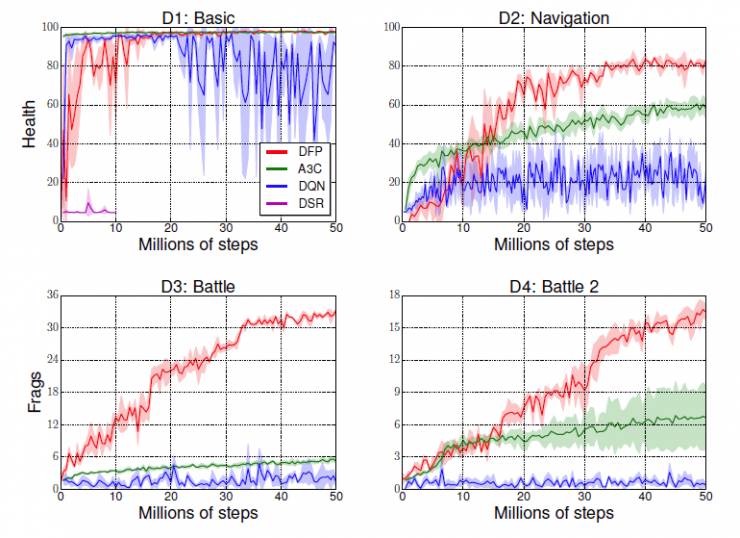
图3:不同方法在训练中的表现。DQN,A3C和DFP在基础的场景中都取得了类似的表现结果。但是DFP在其它三个场景中取得的表现结果都超过了另外三个方法。并且在最复杂的两个场景下(D3与D4),DFP的表现结果远远优于另外三个方法。
ICLR评论
ICLR委员会最终决定
评价:这篇论文详细介绍了作者在VizDoom竞赛中获胜的方法。这是一种预测辅助变量的策略性强化学习方法,并且使用了内在动机。同时该方法也是通用价值函数的一种特殊情况。该方法事实上是其它不同策略的一个集合,但是它产生了令人印象深刻的实验结果,并且论文也写的很清晰。
决定:接受(Oral)
令人信服的经验驱动成果
打分:7分:好论文,接受
评价:深度强化学习(在强化学习算法中使用深度神经网络进行函数近似)在解决大规模状态空间下的强化学习问题中已经取得了许多的成功。而这种经验驱动的工作正是建立在这些方法的基础之上进行的。这篇论文介绍了一种新颖的算法,该算法在原生感觉数据(Raw sensory data)的全新3D环境中表现得更好,并且能在目标和环境之间获得更好的泛化能力。值得注意的是,该算法可是Visual Doom AI竞赛的获胜者。
(没有标题)
打分:8分:在所有被接受的论文中排前50%,确定接受
评价:本文提出了一种具有附加辅助内在变量的策略深度强化学习方法。
该方法是一种基于通用价值函数方法的特殊例子,并且作者也在引用中标注出了正确的参考。也许这篇文章最大的技术贡献是提炼了许多现有的方法来解决3D导航问题。我认为论文的贡献应该在摘要中更加详细地论述出来。
我本来希望看到该方法的失败模式。就是在什么情况下该模型会出现改变目标的问题?并且因为这是一种策略性的方法,所以还存在其它的概念问题。比如,如果算法中的代理不在过去的目标上反复进行训练的话,将会出现灾难性的遗忘。
由于本文的主要贡献是整合了几个关键思想并且展示了经验的优势,所以我还希望看到其它领域的测试结果,比如Atari(也许使用ROM作为内在变量)。
总而言之,我认为这篇论文确实展现了利用所提出的潜在公式的明显经验优势,并且本文的实验见解可能对未来的代理研究具有价值。
(没有标题)
打分:8分:在所有被接受的论文中排前50%,确定接受
评论:这篇论文提出了一种策略性方法来预测未来的内在测量。所有的实验都是在名为Doom(更准确来说是vizDoom)的这款游戏上展开的。与一般性地预测游戏输赢或者是游戏得分不同,本文的作者训练了模型来预测一系列的三元组(健康,弹药,得分),并且由作为输入提供的一系列“目标”三元组加权。改变目标三元组的加权是执行/指导探索的一种方式。在测试期间,只能通过最大化长期目标来实现代理的行动。
这个结果令人印象深刻,因为该模型赢得了2016年vizDoom大赛。并且本文的实验部分看起来很合理:
实验中包含了DFP与A3C、DQN方法的比较,而且也尝试了同DSR方法(与本文相类似的一种方法,由Kulkarni等人在2016年提出)进行比较。DFP方法在各个实验中都超越(或者至少也是持平)了其它方法。
有一项消融研究(Ablation study)能够证明文中所有对模型“增加复杂性”的做法都是有效的。
预测内在动机(Singh et al. 2004)、辅助变量和前向建模都是强化学习中有着较好研究成果的领域。我阅读的那个版本(12月4日修订版)中充分参考了以前的工作,虽然还没有做到非常全面。
我认为这篇应该被接受。可能有些人认为该论文的实验可以在不同的环境下进行或者新颖性有限,但是我认为这篇“正确的”并且“里程碑式的”论文应该得到发表。
报名 |【2017 AI 最佳雇主】榜单

在人工智能爆发初期的时代背景下,雷锋网联合旗下人工智能频道AI科技评论,携手《环球科学》和 BOSS 直聘,重磅推出【2017 AI 最佳雇主】榜单。
从“公司概况”、“创新能力”、“员工福利”三个维度切入,依据 20 多项评分标准,做到公平、公正、公开,全面评估和推动中国人工智能企业发展。
本次【2017 AI 最佳雇主】榜单活动主要经历三个重要时段:
2017.4.11-6.1 报名阶段
2017.6.1-7.1 评选阶段
2017.7.7 颁奖晚宴
最终榜单名单由雷锋网、AI科技评论、《环球科学》、BOSS 直聘以及 AI 学术大咖组成的评审团共同选出,并于7月份举行的 CCF-GAIR 2017大会期间公布。报名期间欢迎大家踊跃自荐或推荐心目中的最佳 AI 企业公司。
报名方式
如果您有意参加我们的评选活动,可以点击【阅读原文】,进入企业报名通道。提交相关审核材料之后,我们的工作人员会第一时间与您取得联系。
【2017 AI 最佳雇主】榜单与您一起,领跑人工智能时代。





