巴赫涂鸦创作者Anna Huang现身上海,倾情讲解「音乐生成」两大算法
编辑 | 唐里
1. Anna Huang 与巴赫涂鸦



论文地址: https://arxiv.org/abs/1903.07227
2. Coconet
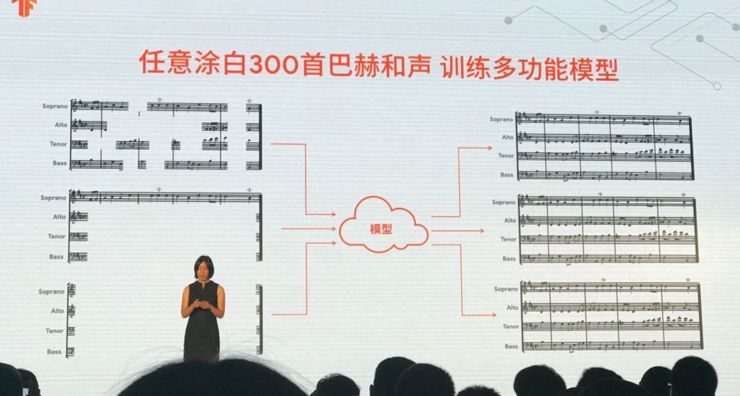

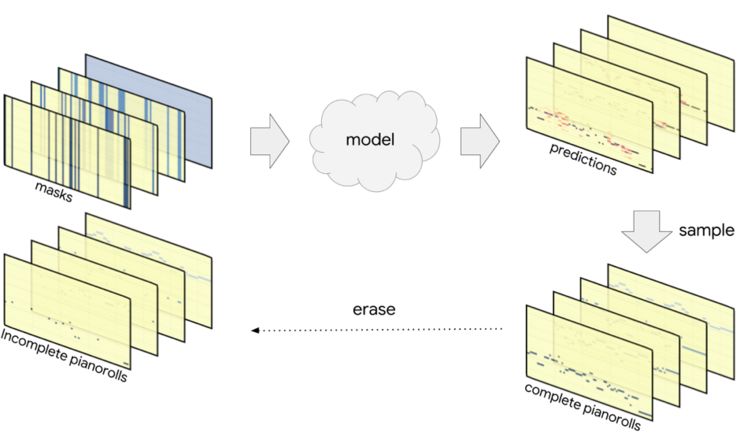


论文地址: https://arxiv.org/abs/1809.04281
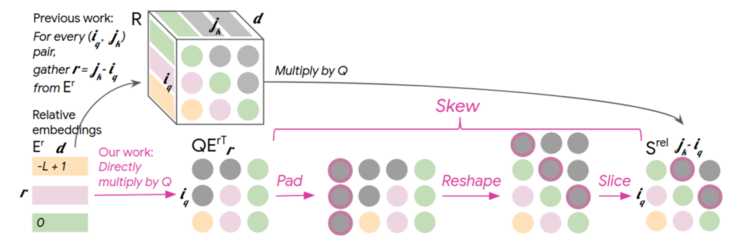
3. Music Transformer
-
时间片t的计算依赖t-1时刻的计算结果,这样限制了模型的并行能力; -
顺序计算的过程中信息会丢失,尽管LSTM等门机制的结构一定程度上缓解了长期依赖的问题,但是对于特别长期的依赖现象,LSTM依旧无能为力。

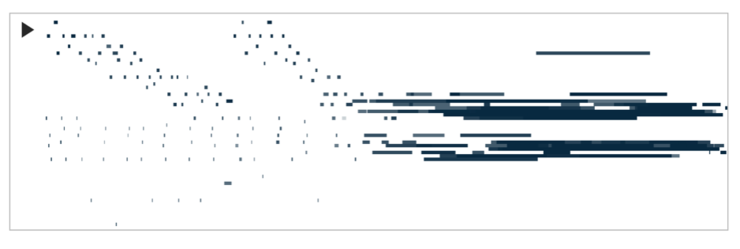



在报告之后,AI科技评论荣幸参与了对Anna Huang的采访,以下是部分采访纪要:
更多内容
「LSTM之父」 Jürgen Schmidhuber访谈:畅想人类和 AI 共处的世界 | WAIC 2019
历年 AAAI 最佳论文(since 1996)
一份完全解读:是什么使神经网络变成图神经网络?

登录查看更多
相关内容

专知会员服务
16+阅读 · 2020年4月8日




相关VIP内容
专知会员服务
16+阅读 · 2020年4月8日
相关资讯
相关论文