盘一盘 Python 系列 1 - 入门篇 (上)


微信公众号终于可以插代码了,Python 可以走一波了。首先我承认不是硬核搞 IT 的,太高级的玩法也玩不来,讲讲下面基本的还可以,之后带点机器学习、金融工程和量化投资的实例也是可以。
Python 入门篇 (上)
Python 入门篇 (下)
数组计算之 NumPy
科学计算之 SciPy
数据结构之 Pandas
基本可视化之 Matplotlib
统计可视化之 Seaborn
交互可视化之 Bokeh
炫酷可视化之 PyEcharts
机器学习之 Sklearn
深度学习之 TensorFlow
深度学习之 Keras
深度学习之 PyTorch
深度学习之 MXnet
整个系列力求精简和实用 (可能不会完整,但看完此贴举一反三也不要完整,追求完整的建议去看书),到了「难点处」我一定会画图帮助读者理解。Python 系列的入门篇的目录如下,本帖是上篇,只涵盖前三个节,下篇接着后两节。

对于任何一种计算机语言,我觉得最重要的就是「数据类型」「条件语句 & 迭代循环」和「函数」,这三方面一定要打牢基础。此外 Python 非常简洁,一行代码 (one-liner) 就能做很多事情,很多时候都用了各种「解析式」,比如列表、字典和集合解析式。
在学习本贴前感受一下这个问题:如何把以下这个不规则的列表 a 里的所有元素一个个写好,专业术语叫打平 (flatten)?
a = [1, 2, [3, 4], [[5, 6], [7, 8]]]魔法来了 (这一行代码有些长,用手机的建议横屏看)
fn = lambda x: [y for l in x for y in fn(l)] if type(x) is list else [x]fn(a)
[1, 2, 3, 4, 5, 6, 7, 8]这一行代码,用到了迭代、匿名函数、递推函数、解析式这些技巧。初学者一看只会说“好酷啊,但看不懂”,看完本帖和下帖后,我保证你会说“我也会这样用了,真酷!”
Python 里面有自己的内置数据类型 (build-in data type),本节介绍基本的三种,分别是整型 (int),浮点型 (float),和布尔型 (bool)。
1.1
整型
整数 (integer) 是最简单的数据类型,和下面浮点数的区别就是前者小数点后没有值,后者小数点后有值。例子如下:
a = 1031print( a, type(a) )
1031 <class 'int'>通过 print 的可看出 a 的值,以及类 (class) 是 int。Python 里面万物皆对象(object),「整数」也不例外,只要是对象,就有相应的属性 (attributes) 和方法 (methods)。
通过 dir( X ) 和help( X ) 可看出 X 对应的对象里可用的属性和方法。
X 是 int,那么就是 int 的属性和方法
X 是 float,那么就是 float 的属性和方法
等等
dir(int)['__abs__',
'__add__',
...
'__xor__',
'bit_length',
'conjugate',
...
'real',
'to_bytes']红色的是 int 对象的可用方法,蓝色的是 int 对象的可用属性。对他们你有个大概印象就可以了,具体怎么用,需要哪些参数 (argument),你还需要查文档。看个bit_length的例子
a.bit_length()11该函数是找到一个整数的二进制表示,再返回其长度。在本例中 a = 1031, 其二进制表示为 ‘10000000111’ ,长度为 11。
1.2
浮点型
简单来说,浮点型 (float) 数就是实数, 例子如下:
print( 1, type(1) )print( 1., type(1.) )
1 <class 'int'>
1.0 <class 'float'>加一个小数点 . 就可以创建 float,不能再简单。有时候我们想保留浮点型的小数点后 n 位。可以用 decimal 包里的 Decimal 对象和 getcontext() 方法来实现。
import decimalfrom decimal import Decimal
Python 里面有很多用途广泛的包 (package),用什么你就引进 (import) 什么。包也是对象,也可以用上面提到的dir(decimal) 来看其属性和方法。比如 getcontext() 显示了 Decimal 对象的默认精度值是 28 位 (prec=28),展示如下:
decimal.getcontext()Context(prec=28, rounding=ROUND_HALF_EVEN, Emin=-999999,
Emax=999999, capitals=1, clamp=0, flags=[],
traps=[InvalidOperation, DivisionByZero, Overflow])让我们看看 1/3 的保留 28 位长什么样?
d = Decimal(1) / Decimal(3)d
Decimal('0.3333333333333333333333333333')那保留 4 位呢?用 getcontext().prec 来调整精度哦。
decimal.getcontext().prec = 4e = Decimal(1) / Decimal(3)e
Decimal('0.3333')高精度的 float 加上低精度的 float,保持了高精度,没毛病。
d + eDecimal('0.6666333333333333333333333333')1.3
布尔型
布尔 (boolean) 型变量只能取两个值,True 和 False。当把布尔变量用在数字运算中,用 1 和 0 代表 True 和 False。
T = TrueF = Falseprint( T + 2 )print( F - 8 )
3
-8除了直接给变量赋值 True 和 False,还可以用 bool(X) 来创建变量,其中 X 可以是
基本类型:整型、浮点型、布尔型
容器类型:字符、元组、列表、字典和集合
print( type(0), bool(0), bool(1) )print( type(10.31), bool(0.00), bool(10.31) )print( type(True), bool(False), bool(True) )
<class 'int'> False True
<class 'float'> False True
<class 'bool'> False Truebool 作用在基本类型变量的总结:X 只要不是整型 0、浮点型 0.0,bool(X) 就是 True,其余就是 False。
print( type(''), bool( '' ), bool( 'python' ) )print( type(()), bool( () ), bool( (10,) ) )print( type([]), bool( [] ), bool( [1,2] ) )print( type({}), bool( {} ), bool( {'a':1, 'b':2} ) )print( type(set()), bool( set() ), bool( {1,2} ) )
<class 'str'> False True
<class 'tuple'> False True
<class 'list'> False True
<class 'dict'> False True
<class 'set'> False Truebool 作用在容器类型变量的总结:X 只要不是空的变量,bool(X) 就是 True,其余就是 False。
确定bool(X) 的值是 True 还是 False,就看 X 是不是空,空的话就是 False,不空的话就是 True。
对于数值变量,0, 0.0 都可认为是空的。
对于容器变量,里面没元素就是空的。
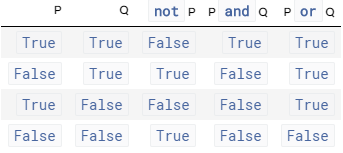
此外两个布尔变量 P 和 Q 的逻辑运算的结果总结如下表:
上节介绍的整型、浮点型和布尔型都可以看成是单独数据,而这些数据都可以放在一个容器里得到一个「容器类型」的数据,比如:
字符 (str) 是一容器的字节 char,注意 Python 里面没有 char 类型的数据,可以把单字符的 str 当做 char。
元组 (tuple)、列表 (list)、字典 (dict) 和集合 (set) 是一容器的任何类型变量。
2.1
字符
字符用于处理文本 (text) 数据,用「单引号 ’」和「双引号 “」来定义都可以。
t1 = 'i love Python!'print( t1, type(t1) )t2 = "I love Python!"print( t2, type(t2) )
i love Python! <class 'str'>
I love Python! <class 'str'>字符中常见的内置方法 (可以用 dir(str) 来查) 有
capitalize():大写句首的字母
split():把句子分成单词
find(x):找到给定词 x 在句中的索引,找不到返回 -1
replace(x, y):把句中 x 替代成 y
strip(x):删除句首或句末含 x 的部分
t1.capitalize()'I love python!'t2.split()['I', 'love', 'Python!']print( t1.find('love') )print( t1.find('like') )
2
-1t2.replace( 'love Python', 'hate R' )'I hate R!'print( 'http://www.python.org'.strip('htp:/') )print( 'http://www.python.org'.strip('.org') )
www.python.org
http://www.pythons = 'Python'print( s )print( s[2:4] )print( s[-5:-2] )print( s[2] )print( s[-1] )
Python
th
yth
t
nPython 里面索引有三个特点 (经常让人困惑):
从 0 开始 (和 C 一样),不像 Matlab 从 1 开始。
切片通常写成 start:end 这种形式,包括「start 索引」对应的元素,不包括「end索引」对应的元素。因此 s[2:4] 只获取字符串第 3 个到第 4 个元素。
索引值可正可负,正索引从 0 开始,从左往右;负索引从 -1 开始,从右往左。使用负数索引时,会从最后一个元素开始计数。最后一个元素的位置编号是 -1。
这些特点引起读者对切片得到什么样的元素感到困惑。有个小窍门可以帮助大家快速锁定切片的元素,如下图。
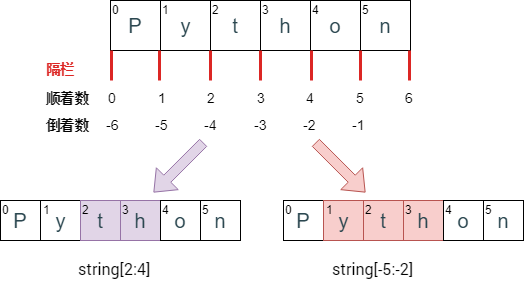
与其把注意力放在元素对应的索引,不如想象将元素分开的隔栏,显然 6 个元素需要 7 个隔栏,隔栏索引也是从 0 开始,这样再看到 start:end 就认为是隔栏索引,那么获取的元素就是「隔栏 start」和「隔栏 end」之间包含的元素。如上图:
string[2:4] 就是「隔栏 2」和「隔栏 4」之间包含的元素,即 th
string[-5:-2] 就是「隔栏 -5」和「隔栏 -2」之间包含的元素,即 yth
正则表达式 (regular expression) 主要用于识别字符串中符合某种模式的部分,什么叫模式呢?用下面一个具体例子来讲解。
input = """'06/18/2019 13:00:00', 100, '1st';'06/18/2019 13:30:00', 110, '2nd';'06/18/2019 14:00:00', 120, '3rd'"""input
"\n'06/18/2019 13:00:00', 100, '1st';
\n'06/18/2019 13:30:00', 110, '2nd';
\n'06/18/2019 14:00:00', 120, '3rd'\n"假如你想把上面字符串中的「时间」的模式来抽象的表示出来,对照着具体表达式 '06/18/2019 13:00:00' 来看,我们发现该字符串有以下规则:
开头和结束都有个单引号 '
里面有多个 0-9 数字
里面有多个正斜线 / 和分号 :
还有一个空格
因此我们用下面这样的模式
pattern = re.compile("'[0-9/:\s]+'")再看这个抽象模式表达式 '[0-9/:\s]+',里面符号的意思如下:
最外面的两个单引号 ' 代表该模式以它们开始和结束
中括号 [] 用来概括该模式涵盖的所有类型的字节
0-9 代表数字类的字节
/ 代表正斜线
: 代表分号
\s 代表空格
[] 外面的加号 + 代表 [] 里面的字节出现至少 1 次
有了模式 pattern,我们来看看是否能把字符串中所有符合 pattern 的日期表达式都找出来。
pattern.findall(input)["'06/18/2019 13:00:00'",
"'06/18/2019 13:30:00'",
"'06/18/2019 14:00:00'"]结果是对的,之后你想怎么盘它就是你自己的事了,比如把 / 换成 -,比如用 datetime 里面的 striptime() 把日期里年、月、日、小时、分钟和秒都获取出来。
2.2
元组
「元组」定义语法为
(元素1, 元素2, ..., 元素n)
关键点是「小括号 ()」和「逗号 ,」
小括号把所有元素绑在一起
逗号将每个元素一一分开
创建元组的例子如下:
t1 = (1, 10.31, 'python')t2 = 1, 10.31, 'python'print( t1, type(t1) )print( t2, type(t2) )
(1, 10.31, 'python') <class 'tuple'>
(1, 10.31, 'python') <class 'tuple'>创建元组可以用小括号 (),也可以什么都不用,为了可读性,建议还是用 ()。此外对于含单个元素的元组,务必记住要多加一个逗号,举例如下:
print( type( ('OK') ) ) # 没有逗号 ,print( type( ('OK',) ) ) # 有逗号 ,
<class 'str'>
<class 'tuple'>看看,没加逗号来创建含单元素的元组,Python 认为它是字符。
当然也可以创建二维元组:
nested = (1, 10.31, 'python'), ('data', 11)nested
((1, 10.31, 'python'), ('data', 11))元组中可以用整数来对它进行索引 (indexing) 和切片 (slicing),不严谨的讲,前者是获取单个元素,后者是获取一组元素。接着上面二维元组的例子,先看看索引的代码:
nested[0]print( nested[0][0], nested[0][1], nested[0][2] )
(1, 10.31, 'python')
1 10.31 python再看看切片的代码:
nested[0][0:2] (1, 10.31)元组有不可更改 (immutable) 的性质,因此不能直接给元组的元素赋值,例子如下 (注意「元组不支持元素赋值」的报错提示)。
t = ('OK', [1, 2], True)t[2] = False
TypeError: 'tuple' object does not support item assignment但是只要元组中的元素可更改 (mutable),那么我们可以直接更改其元素,注意这跟赋值其元素不同。如下例 t[1] 是列表,其内容可以更改,因此用 append 在列表后加一个值没问题。
t[1].append(3)('OK', [1, 2, 3], True)元组大小和内容都不可更改,因此只有 count 和 index 两种方法。
t = (1, 10.31, 'python')print( t.count('python') )print( t.index(10.31) )
1
1这两个方法返回值都是 1,但意思完全不同
count('python') 是记录在元组 t 中该元素出现几次,显然是 1 次
index(10.31) 是找到该元素在元组 t 的索引,显然是 1
元组拼接 (concatenate) 有两种方式,用「加号 +」和「乘号 *」,前者首尾拼接,后者复制拼接。
(1, 10.31, 'python') + ('data', 11) + ('OK',)(1, 10.31, 'python') * 2
(1, 10.31, 'python', 'data', 11, 'OK')
(1, 10.31, 'python', 1, 10.31, 'python')解压 (unpack) 一维元组 (有几个元素左边括号定义几个变量)
t = (1, 10.31, 'python')(a, b, c) = tprint( a, b, c )
1 10.31 python解压二维元组 (按照元组里的元组结构来定义变量)
t = (1, 10.31, ('OK','python'))(a, b, (c,d)) = tprint( a, b, c, d )
1 10.31 OK python如果你只想要元组其中几个元素,用通配符「*」,英文叫 wildcard,在计算机语言中代表一个或多个元素。下例就是把多个元素丢给了 rest 变量。
t = 1, 2, 3, 4, 5a, b, *rest, c = tprint( a, b, c )print( rest )
1 2 5
[3, 4]如果你根本不在乎 rest 变量,那么就用通配符「*」加上下划线「_」,刘例子如下:
a, b, *_ = tprint( a, b )
1 2优点:占内存小,安全,创建遍历速度比列表快,可一赋多值。
缺点:不能添加和更改元素。
等等等,这里有点矛盾,元组的不可更改性即使优点 (安全) 有时缺点?确实是这样的,安全就没那么灵活,灵活就没那么安全。看看大佬廖雪峰怎么评价「不可更改性」吧
immutable 的好处实在是太多了:性能优化,多线程安全,不需要锁,不担心被恶意修改或者不小心修改。
后面那些安全性的东西我也不大懂,性能优化这个我可以来测试一下列表和元组。列表虽然没介绍,但是非常简单,把元组的「小括号 ()」该成「中括号 []」就是列表了。我们从创建、遍历和占空间三方面比较。
%timeit [1, 2, 3, 4, 5]%timeit (1, 2, 3, 4, 5)
62 ns ± 13.2 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)
12.9 ns ± 1.94 ns per loop (mean ± std. dev. of 7 runs, 100000000 loops each)创建速度,元组 (12.9ns) 碾压列表 (62ns)。
lst = [i for i in range(65535)]tup = tuple(i for i in range(65535))%timeit for each in lst: pass%timeit for each in tup: pass
507 µs ± 61.1 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
498 µs ± 18.7 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)遍历速度两者相当,元组 (498 µs) 险胜列表 (507 µs)。
from sys import getsizeofprint( getsizeof(lst) )print( getsizeof(tup) )
578936
524328列表比元组稍微废点内存空间。
2.3
列表
「列表」定义语法为
[元素1, 元素2, ..., 元素n]
关键点是「中括号 []」和「逗号 ,」
中括号把所有元素绑在一起
逗号将每个元素一一分开
创建列表的例子如下:
l = [1, 10.31,'python']print(l, type(l))
[1, 10.31, 'python'] <class 'list'>不像元组,列表内容可更改 (mutable),因此附加 (append, extend)、插入 (insert)、删除 (remove, pop) 这些操作都可以用在它身上。
l.append([4, 3])print( l )l.extend([1.5, 2.0, 'OK'])print( l )
[1, 10.31, 'python', [4, 3]]
[1, 10.31, 'python', [4, 3], 1.5, 2.0, 'OK']严格来说 append 是追加,把一个东西整体添加在列表后,而 extend 是扩展,把一个东西里的所有元素添加在列表后。对着上面结果感受一下区别。
l.insert(1, 'abc') # insert object before the index positionl
[1, 'abc', 10.31, 'python', [4, 3], 1.5, 2.0, 'OK']insert(i, x) 在编号 i 位置前插入 x。对着上面结果感受一下。
l.remove('python')l
[1, 'abc', 10.31, [4, 3], 1.5, 2.0, 'OK']p = l.pop(3) # removes and returns object at index. Only only pop 1 index position at any time.print( p )print( l )
[4, 3]
[1, 'abc', 10.31, 1.5, 2.0, 'OK']remove 和 pop 都可以删除元素
前者是指定具体要删除的元素,比如 'python'
后者是指定一个编号位置,比如 3,删除 l[3] 并返回出来
对着上面结果感受一下,具体用哪个看你需求。
索引 (indexing) 和切片 (slicing) 语法在元组那节都讲了,而且怎么判断切片出来的元素在字符那节也讲了,规则如下图:
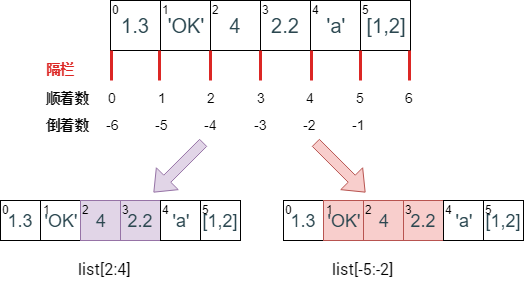
对照上图看下面两个例子 (顺着数和倒着数编号):
l = [7, 2, 9, 10, 1, 3, 7, 2, 0, 1]l[1:5]
[2, 9, 10, 1]l[-4:][7, 2, 0, 1]列表可更改,因此可以用切片来赋值。
l[2:4] =l
[7, 2, 999, 1000, 1, 3, 7, 2, 0, 1]切片的通用写法是
start : stop : step
这三个在特定情况下都可以省去,我们来看看四种情况:
print( l )print( l[3:] )print( l[-4:] )
[7, 2, 999, 1000, 1, 3, 7, 2, 0, 1]
[1000, 1, 3, 7, 2, 0, 1]
[7, 2, 0, 1]以 step 为 1 (默认) 从编号 start 往列表尾部切片。
print( l )print( l[:6] )print( l[:-4] )
[7, 2, 999, 1000, 1, 3, 7, 2, 0, 1]
[7, 2, 999, 1000, 1, 3]
[7, 2, 999, 1000, 1, 3]以 step 为 1 (默认) 从列表头部往编号 stop 切片。
print( l )print( l[2:4] )print( l[-5:-1] )
[7, 2, 999, 1000, 1, 3, 7, 2, 0, 1]
[999, 1000]
[3, 7, 2, 0]以 step 为 1 (默认) 从编号 start 往编号 stop 切片。
print( l )print( l[1:5:2] )print( l[:5:2] )print( l[1::2] )print( l[::2] )print( l[::-1] )
[7, 2, 999, 1000, 1, 3, 7, 2, 0, 1]
[2, 1000]
[7, 999, 1]
[2, 1000, 3, 2, 1]
[7, 999, 1, 7, 0]
[1, 0, 2, 7, 3, 1, 1000, 999, 2, 7]以具体的 step 从编号 start 往编号 stop 切片。注意最后把 step 设为 -1,相当于将列表反向排列。
和元组拼接一样, 列表拼接也有两种方式,用「加号 +」和「乘号 *」,前者首尾拼接,后者复制拼接。
[1, 10.31, 'python'] + ['data', 11] + ['OK'][1, 10.31, 'python'] * 2
[1, 10.31, 'python', 'data', 11, 'OK']
[1, 10.31, 'python', 1, 10.31, 'python']优点:灵活好用,可索引、可切片、可更改、可附加、可插入、可删除。
缺点:相比 tuple 创建和遍历速度慢,占内存。此外查找和插入时间较慢。
2.4
字典
「字典」定义语法为
{元素1, 元素2, ..., 元素n}
其中每一个元素是一个「键值对」- 键:值 (key:value)
关键点是「大括号 {}」,「逗号 ,」和「分号 :」
大括号把所有元素绑在一起
逗号将每个键值对一一分开
分号将键和值分开
创建字典的例子如下:
d = {'Name' : 'Tencent','Country' : 'China','Industry' : 'Technology','Code': '00700.HK','Price' : '361 HKD'}print( d, type(d) )
{'Name': 'Tencent', 'Country': 'China',
'Industry': 'Technology', 'Code': '00700.HK',
'Price': '361 HKD'} <class 'dict'>字典里最常用的三个内置方法就是 keys(), values() 和 items(),分别是获取字典的键、值、对。
print( list(d.keys()),'\n' )print( list(d.values()), '\n' )print( list(d.items()) )
['Name', 'Country', 'Industry', 'Code', 'Price', 'Headquarter']
['Tencent', 'China', 'Technology', '00700.HK', '359 HKD', 'Shen Zhen']
[('Name', 'Tencent'), ('Country', 'China'),
('Industry', 'Technology'), ('Code', '00700.HK'),
('Price', '359 HKD'), ('Headquarter', 'Shen Zhen')]此外在字典上也有添加、获取、更新、删除等操作。
比如加一个「总部:深圳」
d['Headquarter'] = 'Shen Zhen'd
{'Name': 'Tencent',
'Country': 'China',
'Industry': 'Technology',
'Code': '00700.HK',
'Price': '361 HKD',
'Headquarter': 'Shen Zhen'}比如想看看腾讯的股价是多少 (两种方法都可以)
print( d['Price'] )print( d.get('Price') )
359 HKD
359 HKD比如更新腾讯的股价到 359 港币
d['Price'] = '359 HKD'd
{'Name': 'Tencent',
'Country': 'China',
'Industry': 'Technology',
'Code': '00700.HK',
'Price': '359 HKD',
'Headquarter': 'Shen Zhen'}比如去掉股票代码 (code)
del d['Code']d
{'Name': 'Tencent',
'Country': 'China',
'Industry': 'Technology',
'Price': '359 HKD',
'Headquarter': 'Shen Zhen'}或像列表里的 pop() 函数,删除行业 (industry) 并返回出来。
print( d.pop('Industry') )d
Technology
{'Name': 'Tencent',
'Country': 'China',
'Price': '359 HKD',
'Headquarter': 'Shen Zhen'}字典里的键是不可更改的,因此只有那些不可更改的数据类型才能当键,比如整数 (虽然怪怪的)、浮点数 (虽然怪怪的)、布尔 (虽然怪怪的)、字符、元组 (虽然怪怪的),而列表却不行,因为它可更改。看个例子
d = {2 : 'integer key',10.31 : 'float key',True : 'boolean key',('OK',3) : 'tuple key'}d
{2: 'integer key',
10.31: 'float key',
True: 'boolean key',
('OK', 3): 'tuple key'}虽然怪怪的,但这些 2, 10.31, True, ('OK', 3) 确实能当键。有个地方要注意下,True 其实和整数 1 是一样的,由于键不能重复,当你把 2 该成 1时,你会发现字典只会取其中一个键,示例如下:
d = {1 : 'integer key',10.31 : 'float key',True : 'boolean key',('OK',3) : 'tuple key'}d
{1: 'boolean key',
10.31: 'float key',
('OK', 3): 'tuple key'}那么如何快速判断一个数据类型 X 是不是可更改的呢?两种方法:
麻烦方法:用 id(X) 函数,对 X 进行某种操作,比较操作前后的 id,如果不一样,则 X 不可更改,如果一样,则 X 可更改。
便捷方法:用 hash(X),只要不报错,证明 X 可被哈希,即不可更改,反过来不可被哈希,即可更改。
先看用 id() 函数的在整数 i 和列表 l 上的运行结果:
i = 1print( id(i) )i = i + 2print( id(i) )
1607630928
1607630992l = [1, 2]print( id(l) )l.append('Python')print( id(l) )
2022027856840
2022027856840整数 i 在加 1 之后的 id 和之前不一样,因此加完之后的这个 i (虽然名字没变),但是不是加前的那个 i 了,因此整数是不可更改的。
列表 l 在附加 'Python' 之后的 id 和之前一样,因此列表是可更改的。
先看用 hash() 函数的在字符 s,元组 t 和列表 l 上的运行结果:
hash('Name')7230166658767143139hash( (1,2,'Python') )3642952815031607597hash( [1,2,'Python'] )TypeError: unhashable type: 'list'字符 s 和元组 t 都能被哈希,因此它们是不可更改的。列表 l 不能被哈希,因此它是可更改的。
优点:查找和插入速度快
缺点:占内存大
2.5
集合
「集合」有两种定义语法,第一种是
{元素1, 元素2, ..., 元素n}
关键点是「大括号 {}」和「逗号 ,」
大括号把所有元素绑在一起
逗号将每个元素一一分开
第二种是用 set() 函数,把列表或元组转换成集合。
set( 列表 或 元组 )
创建集合的例子如下 (用两者方法创建 A 和 B):
A = set(['u', 'd', 'ud', 'du', 'd', 'du'])B = {'d', 'dd', 'uu', 'u'}print( A )print( B )
{'d', 'du', 'u', 'ud'}
{'d', 'dd', 'u', 'uu'}从 A 的结果发现集合的两个特点:无序 (unordered) 和唯一 (unique)。由于 set 存储的是无序集合,所以我们没法通过索引来访问,但是可以判断一个元素是否在集合中。
B[1]TypeError: 'set' object does not support indexing'u' in BTrue用 set 的内置方法就把它当成是数学上的集,那么并集、交集、差集都可以玩通了。
print( A.union(B) ) # All unique elements in A or Bprint( A | B ) # A OR B
{'uu', 'dd', 'd', 'u', 'du', 'ud'}
{'uu', 'dd', 'd', 'u', 'du', 'ud'}print( A.intersection(B) ) # All elements in both A and Bprint( A & B ) # A AND B
{'d', 'u'}
{'d', 'u'}print( A.difference(B) ) # Elements in A but not in Bprint( A - B ) # A MINUS B
{'ud', 'du'}
{'ud', 'du'}print( B.difference(A) ) # Elements in B but not in Aprint( B - A ) # B MINUS A
{'uu', 'dd'}
{'uu', 'dd'}print( A.symmetric_difference(B) ) # All elements in either A or B, but not bothprint( A ^ B ) # A XOR B
{'ud', 'du', 'dd', 'uu'}
{'ud', 'du', 'dd', 'uu'}优点:不用判断重复的元素
缺点:不能存储可变对象
你看集合的「唯一」特性还不是双刃剑,既可以是优点,又可以是缺点,所有东西都有 trade-off 的,要不然它就没有存在的必要了。
在编写程序时,我们要
在不同条件下完成不同动作,条件语句 (conditional statement) 赋予程序这种能力。
重复的完成某些动作,迭代循环 (iterative loop) 赋予程序这种能力。
3.1
条件语句
条件语句太简单了,大体有四种格式
if 语句
if-else 语句
if-elif-else 语句
nested 语句
看了下面四幅图 (包含代码) 应该秒懂条件语句,其实任何会说话的人都应该懂它。
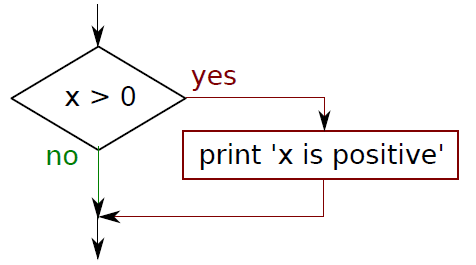
if x > 0:print( 'x is positive' )
给定二元条件,满足做事,不满足不做事。
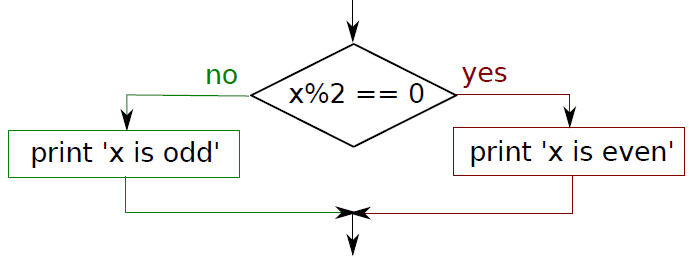
if x % 2 == 0:print( 'x is even' )else :print( 'x is odd' )
给定二元条件,满足做事 A,不满足做事 B。
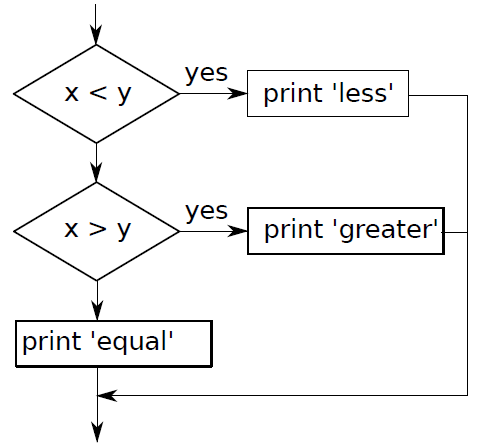
if x < y:print( 'x is less than y' )elif x > y:print( 'x is greater than y' )else:print( 'x and y are equal' )
给定多元条件,满足条件 1 做事 A1,满足条件 2 做事 A2,..., 满足条件 n 做事 An。直到把所有条件遍历完。
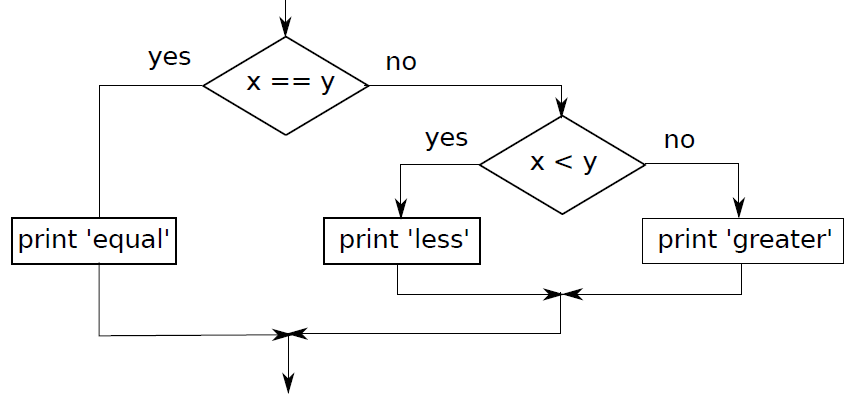
if x == y:print( 'x and y are equal' )else:if x < y:print( 'x is less than y' )else:print( 'x is greater than y' )
给定多元条件,满足条件 1 做事 A1,不满足就
给定多元条件,满足条件 2 做事 A2,不满足就
...
直到把所有条件遍历完。
3.2
迭代循环
对于迭代循环,Python 里面有「while 循环」和「for 循环」,没有「do-while 循环」。
n = 5while n > 0:print(n)n = n-1print('I love Python')
5
4
3
2
1
I love PythonWhile 循环非常简单,做事直到 while 后面的语句为 False。上例就是打印从 n (初始值为 5) 一直到 1,循环执行了 5 次。
一般来说,在 「while 循环」中,迭代的次数事先是不知道的,因为通常你不知道 while 后面的语句从 True 变成 False了。
更多时候我们希望事先直到循环的次数,比如在列表、元组、字典等容器类数据上遍历一遍,在每个元素层面上做点事情。这时候就需要「for 循环」了。
languages = ['Python', 'R', 'Matlab', 'C++']for language in languages:print( 'I love', language )print( 'Done!' )
I love Python
I love R
I love Matlab
I love C++
Done!读读 Python 里面的「for 循环」是不是很像读英文。通用形式的 for loop 如下
for a in A
do something with a
其中 for 和 in 是关键词,A 是个可迭代数据 (list, tuple, dic, set),a 是 A 里面的每个元素,上句翻译成中文是
对于 A 里面的每个 a
对 a 搞点事
回到具体例子,for loop 里面的 language 变量在每次循环中分别取值 Python, R, Matlab 和 C++,然后被打印。
最后介绍一个稍微有点特殊的函数 enumerate(),和 for loop 一起用的语法如下
for i, a in enumerate(A)
do something with a
发现区别了没?用 enumerate(A) 不仅返回了 A 中的元素,还顺便给该元素一个索引值 (默认从 0 开始)。此外,用 enumerate(A, j) 还可以确定索引起始值为 j。 看下面例子。
languages = ['Python', 'R', 'Matlab', 'C++']for i, language in enumerate(languages, 1):print( i, 'I love', language )print( 'Done!' )
1 I love Python
2 I love R
3 I love Matlab
4 I love C++
Done!学习任何一种都要从最基本开始,基本的东西无外乎数据类型、条件语句和递推循环。
数据类型分两种:
单独类型:整型、浮点型、布尔型
容器类型:字符、元组、列表、字典、集合
按照 Python 里「万物皆对象」的思路,学习每一个对象里面的属性 (attributes) 和方法 (methods),你不需要记住所有,有个大概印象有哪些,通过 dir() 来锁定具体表达式,再去官网上查询所有细节。这么学真的很系统而简单。此外学的时候一定要带着“它的优缺点是什么”这样的问题,所有东西都有 trade-off,一个满身都是缺点的东西就没有存在的必要,既然存在肯定有可取之处。
条件语句 (if, if-else, if-elif-else, nested if) 是为了在不同条件下执行不同操作,而迭代循环 (while, for) 是重复的完成相同操作。
抓住上面大框架,最好还要以目标导向 (我学 python 就是为了搞量化交易希望能躺着赚钱),别管这目标难度如何,起码可以保证我累得时候还鸡血满满不会轻言放弃。这样我就足够主动的去学一样东西并学精学深,目标越难完成,我主动性就越强。
之后所有的细节都可以慢慢来,虽然我觉得本篇已经挖了不少细节了,像 hashability,但肯定还有更多等着去挖,半篇帖子就想覆盖 Python 所有内容不是开玩笑吗?但
抓住大框架,有目标导向,对有效学习任何内容都适用。
下篇接着函数 (function) 和解析式 (comprehension)。Stay Tuned!
按二维码关注王的机器
迟早精通机学金工量投







