ADL125《AI+DB》开始报名


大数据时代,人工智能(AI)与数据库(DB)分别在数据分析与数据查询处理方面承担着重要角色。AI+DB的基础和前沿,包括智能自治数据库、库内机器学习、面向AI的数据准备等技术,使DB更智能,AI更高效,有效推动了DB与AI的产业化进程。
CCF学科前沿讲习班
The CCF Advanced Disciplines Lectures
CCFADL第125期
主题 AI+DB
2022年6月25-27日 北京
本期CCF学科前沿讲习班ADL125《AI+DB》,将对AI与DB相结合的基础、前沿进展和典型应用进行系统性介绍。帮助学员在了解DB基本概念的基础上,从入门到前沿快速深入地掌握如何利用AI技术提升DB性能,以及业界如何应用AI解决DB问题。同时,帮助学员了解如何利用DB技术赋能AI,提升训练推理效率与模型性能。相信学员经过本次讲习班的学习,能够深入了解AI+DB的基本原理、主要挑战和应用场景,开阔科研视野,增强实践能力。
本期ADL讲习班邀请了本领域9位国内外著名高校与企业科研机构活跃在前沿领域的青年学者做主题报告。第1天,李国良将介绍如何使用机器学习技术来优化数据库;张策将介绍高效的数据库内机器学习。第2天,丁博麟与孙佶将分别介绍智能数据库分别在阿里巴巴与华为的应用落地;Tim Kraska将介绍Instance-optimized Data Systems;伍赛将介绍支持声明式AI服务的数据库系统。第3天,Arun Kumar将介绍如何利用DB技术来大众化(democratize)AI以期降低AI的使用门槛;范举将介绍面向人工智能的数据准备技术;姚权铭将介绍自动化机器学习(AutoML)的原理与方法。通过三天教学,旨在带领学员实现对AI+DB从基础理论,到前沿科研动态,再到典型应用场景的深入学习与思考。
学术主任:李国良 清华大学、柴成亮 清华大学
主办单位:中国计算机学会
活动日程
2022年6月25日(周六) |
|
9:00-9:15 |
开班仪式 |
9:15-9:30 |
全体合影 |
9:30-12:30 |
专题讲座1:机器学习赋能的数据库系统 李国良 清华大学教授,博导,计算机系副主任 |
12:30-13:30 |
午餐 |
13:30-16:30 |
专题讲座2:Efficient In-Database Machine Learning with Deep Physical Integration Ce Zhang Assistant Professor, ETH Zurich |
2022年6月26日(周日) |
|
9:00-10:20 |
专题讲座3:智能数据库技术:理论到实践、机遇和挑战 丁博麟 阿里巴巴-智能计算实验室资深技术专家 |
10:30-12:00 |
专题讲座4:openGauss:构建内外兼修的数据库智能自治能力 孙佶 华为高斯实验室数据库助理首席专家 |
12:00-13:30 |
午餐 |
13:30-14:50 |
专题讲座5:Towards instance-optimized data systems Tim Kraska Associate Professor,MIT |
15:00-16:30 |
专题讲座6:ZenDB: A Declarative AI-enhanced Database System 伍赛 浙江大学教授、博导 |
2022年6月27日(周一) |
|
9:00-10:20 |
专题讲座7:The New DBfication of ML/AI Arun Kumar Associate Professor,UCSD |
10:30-12:00 |
专题讲座8:面向人工智能的数据准备技术:机遇与挑战 范举 中国人民大学副教授,博导 |
12:00-13:30 |
午餐 |
13:30-16:30 |
专题讲座9:自动化机器学习的原理与方法 姚权铭 清华大学,助理教授,博导 |
16:30-17:00 |
小结 |
特邀讲者

李国良
清华大学
讲者简介:李国良,清华大学计算机系教授,系副主任。主要研究数据库、大数据挖掘与分析。在数据库顶级会议和期刊上发表论文150余篇,他引12000余次。主持国家杰青、优青、青年973、重点等项目。获得了VLDB杰出青年贡献奖 、IEEE 数据工程领域杰出新人奖、CCF青年科学家奖等奖项。SIGMOD 2021大会主席、VLDB 2021 Demo主席、ICDE 2022 Industry主席。获得过Best of VLDB 2020/ICDE 2018/KDD 2018, CIKM 2017 Best Paper。获得过国家科技进步二等奖、江苏省科技进步一等奖、国家电网科技进步一等奖等奖项。
报告题目:机器学习赋能的数据库系统
报告摘要:本报告主要讲述如何使用机器学习技术来优化数据库,包括(1)基于机器学习的优化器(学习型基数和代价估计、学习型查询重写、学习型物理优化);(2)基于机器学习的数据库配置优化(基于机器学习的分布键推荐、索引推荐、视图推荐、参数推荐);(3)学习型数据结构(学习型索引);(4)基于机器学习的查询与数据生成(SQL生成、数据生成、SQL预测);(5)基于机器学习的系统诊断(慢SQL诊断、系统诊断)等。本报告还将数据库优化问题分成NP优化问题、回归问题、预测问题,并讲述如何利用机器学习算法(深度学习、强化学习、元学习、图学习等)来解决这些问题。最后本报告还介绍研究趋势和未来挑战。

Ce Zhang
ETH Zurich
讲者简介:Ce is an Assistant Professor in Computer Science at ETH Zurich. The mission of his research is to make machine learning techniques widely accessible——while being cost-efficient and trustworthy——to everyone who wants to use them to make our world a better place. He believes in a system approach to enabling this goal, and his current research focuses on building next-generation machine learning platforms and systems that are data-centric, human-centric, and declaratively scalable. Before joining ETH, Ce finished his PhD at the University of Wisconsin-Madison and spent another year as a postdoctoral researcher at Stanford, both advised by Christopher Ré. His work has received recognitions such as the SIGMOD Best Paper Award, SIGMOD Research Highlight Award, Google Focused Research Award, an ERC Starting Grant, and has been featured and reported by Science, Nature, the Communications of the ACM, and a various media outlets such as Atlantic, WIRED, Quanta Magazine, etc.
报告题目:Efficient In-Database Machine Learning with Deep Physical Integration
报告摘要:Today, training machine learning inside databases using libraries such as MADlib could be orders of magnitude slower than its non-DB counterpart (e.g., PyTorch over files). Is this slowdown an inevitable price that we have to pay in order to enjoy all the other great benefits that a database provides? We hope the answer is no —— in this talk, I will present our efforts in optimizing ML training inside database systems. We integrated ML training as a collection of physical operators, a very different design decision compared with other in-DB ML solutions. This deep integration, along with several novel algorithms, allows us to close this DB/non-DB gap for a range of ML models.

丁博麟
阿里巴巴
讲者简介:丁博麟,阿里巴巴-智能计算实验室资深技术专家。于中国人民大学完成数学与应用数学本科学习,后前往香港中文大学和美国伊利诺伊大学香槟分校,分别获得系统工程硕士和计算机科学博士。研究方向包括:数据隐私保护,智能系统(AI4AI,AI4DB,AI4Econ),机器学习算法理论及应用。2018年4月加入阿里巴巴。之前就职于美国微软研究院任研究员。项目成果被授予十余项美国技术专利,多项成果直接应用于业界重要软件和服务。研究成果发表于SIGMOD,VLDB,ICDE,KDD,NIPS,ICML,ICLR,CHI等多个领域的顶尖国际会议。
报告题目:智能数据库技术:理论到实践、机遇和挑战
报告摘要:为了提高大数据系统的竞争力,优化数据库运行效率和降低资源消耗是两个关键技术发力点,也是数据管理系统研究方向一直以来的研究热点。在最近五年,研究人员开始探索如何利用机器学习技术优化数据库系统(AI4DB),其中不少成果在实验室环境中的标准benchmark上有非常优异的表现,但是一直未能有成熟的技术大规模落地应用于实际场景中的大数据系统并创造商业和生产价值。我们希望继续在该方向进行科研探索,并探究现在这个方向上前沿技术和研究成果与实际系统应用的差距。这次报告会介绍我们在AI4DB几个方向上研究的进展和思考,包括基于机器学习的参数估计、数据索引、查询优化,从理论和实践的角度分别探讨为什么基于机器学习的数据库技术具备潜力和可行性,以及需要什么样的系统支持。

孙佶
华为
讲者简介:孙佶,任职于华为高斯实验室,数据库助理首席专家。于北京邮电大学计算机学院获得工学学士学位,后于清华大学计算机系获得工学博士学位。研究方向包括:AI与数据库交叉技术(AI4DB,DB4AI)、数据库近似检索技术以及机器学习算法理论及应用。研究成果发表于SIGMOD,VLDB,ICDE等数据库顶尖国际会议。曾获得CCF优秀博士论文奖,北京市优秀毕业生, Sigmod Programming Contest优胜奖等荣誉。
报告题目:openGauss:构建内外兼修的数据库智能自治能力
报告摘要:随着生产环境中的负载和数据的复杂性以及运行环境的异构性,依赖于简单规则和专家经验的传统数据库系统,在执行效率、可维护性以及可用性上面临巨大的挑战。比如负载和数据的复杂性很容易导致数据库配置参数失效以及代价估计系统奔溃;而运行环境的异构性则导致了数据库性能问题诊断和治愈难度陡增。针对这些数据库痛点,学术界在近几年尝试使用机器学习的方法进行解决,取得了令人瞩目的实验效果;工业界也进行了AI和数据库交叉技术的实践,并且诞生了一些利用AI算法进行数据库辅助调优的产品,取得了很好的商业效果。openGauss作为一款针对智能自治能力构建设计的数据库,具备强大的性能自监控以及原生AI计算能力,我们研发出的数据库运行管理和内核优化组件服务于云平台以及客户生产环境中。本次报告介绍openGauss中的AI原生架构、自监控自诊断能力以及智能优化器(ABO)的研发进展,并且介绍我们对AI原生数据库的挑战以及未来发展方向的思考。

Tim Kraska
MIT
讲者简介:Tim Kraska is an Associate Professor of Electrical Engineering and Computer Science in MIT's Computer Science and Artificial Intelligence Laboratory, co-director of the Data System and AI Lab at MIT (DSAIL@CSAIL), and co-founder of Einblick Analytics. Currently, his research focuses on building systems for machine learning, and using machine learning for systems. Before joining MIT, Tim was an Assistant Professor at Brown, spent time at Google Brain, and was a PostDoc in the AMPLab at UC Berkeley after he got his PhD from ETH Zurich. Tim is a 2017 Alfred P. Sloan Research Fellow in computer science and received several awards including the VLDB Early Career Research Contribution Award, the VMware Systems Research Award, the university-wide Early Career Research Achievement Award at Brown University, an NSF CAREER Award, as well as several best paper and demo awards at VLDB, SIGMOD, and ICDE.
报告题目:Towards instance-optimized data systems
报告摘要:Recently, there has been a lot of excitement around ML-enhanced (or learned) algorithms and data structures. For example, there has been work on applying machine learning to improve query optimization, indexing, storage layouts, scheduling, log-structured merge trees, sorting, compression, sketches, among many other data management tasks. Arguably, the ideas behind these techniques are similar: machine learning is used to model the data and/or workload in order to derive a more efficient algorithm or data structure. Ultimately, what these techniques will allow us to build are “instance-optimized” systems; systems that self-adjust to a given workload and data distribution to provide unprecedented performance and avoid the need for tuning by an administrator. In this talk, I will first provide an overview of the opportunities and limitations of current ML-enhanced algorithms and data structures, present initial results of SageDB, a first instance-optimized system we are building as part of DSAIL@CSAIL at MIT, and finally outline remaining challenges and future directions.

伍赛
浙江大学
讲者简介:伍赛博士2002和2005年于北京大学分别获得学士和硕士学位,于2011年在新加坡国立大学获得博士学位,主要的研究方向包括:分布式数据、大数据处理、人工智能驱动的数据分析等。在数据库领域顶级/重要学术期刊ACM Computing Survey、The VLDB Journal (VLDBJ)、IEEE Transactions on Knowledge and Data Engineering (TKDE)等和国际会议SIGMOD、VLDB、ICDE、SIGIR等发表论文60多篇。大数据并行处理框架epiC的论文被评选为VLDB 2014最佳论文奖,分布式数据库BestPeer++论文获ICDE 2012最佳论文提名。论文《Distributed data management using MapReduce》作为滑铁卢大学、雅典大学等大数据课程教材。申请人是多个国际知名会议(VLDB2010, ICDE2011,CIKM2011, VLDB2014, ICDE2014, SIGMOD2014, SIGMOD2015, VLDB2015,VLDB2016, VLDB2017、VLDB2022、VLDB 2023、CIKM2017, ICDE 2018, VLDB2018, VLDB2019, VLDB 2022, KDD 2021, KDD 2022、KDD 2023、SIGMOD 2022、SIGMOD 2023)的程序委员会委员。申请人基于epiC开发的yzStack大数据平台已经在浙江省财政厅、南方电网超高压、杭州市海关等项目上得到应用。大数据相关研究成果获得了2016年教育部科技进步奖一等奖(4/10), 2019年电子学会科技进步特等奖(6/15), 2020年电子学会科技进步一等奖(3/15), 2020年教育部科技进步奖一等奖(9/10)。2020获得国家万人计划青年拔尖人才。
报告题目:ZenDB: A Declarative AI-enhanced Database System
报告摘要:在物联网、金融、工业制造等领域的应用中,数据通常存储和管理在关系数据库系统中,而为了支持如模式识别、自然语言分析等AI模型,需要将数据导出到类似于TensorFlow/PyTorch等系统中进行预测和推断。推断的结果往往又要导回到数据库中,以支持复杂的BI分析。维护两个系统进行数据共享和同步及其复杂,而且由于“系统墙”的存在,性能也无法满足实时大数据分析的需求。项目组提出了ZenStack框架,一个包含数据服务层、迭代式学习层和ZenDB层的AI服务框架。本讲座介绍其中的ZenDB层,一个支持声明式AI服务的数据库系统。ZenDB在数据库内实现了大部分神经网络算子,并支持应用多种数据库技术对模型进行优化,支持AI推断无缝嵌入到数据库BI查询中,并提供相对应的模型存储和管理的类SQL语言。

Arun Kumar
UCSD
讲者简介:Arun Kumar is an Associate Professor in the Department of Computer Science and Engineering and the Halicioglu Data Science Institute and an HDSI Faculty Fellow at the University of California, San Diego. His primary research interests are in data management and systems for machine learning/artificial intelligence-based data analytics. Systems and ideas from his work have been released as part of the Apache MADlib open-source library and shipped as part of products from or used internally by many database, Web, and cloud companies. He is a recipient of three SIGMOD research paper awards, four distinguished reviewer/metareviewer awards from SIGMOD/VLDB, the IEEE TCDE Rising Star Award, an NSF CAREER Award, and research award gifts from Amazon, Google, Oracle, and VMware.
报告题目:The New DBfication of ML/AI
报告摘要:The recent boom in ML/AI applications has brought into sharp focus the pressing need for tackling the concerns of scalability, usability, and manageability across the entire lifecycle of ML/AI applications. The ML/AI world has long studied the concerns of accuracy, automation, etc. from theoretical and algorithmic vantage points. But to truly democratize ML/AI, the vantage point of building and deploying practical systems is equally critical.In this talk, I will make the case that it is high time to bridge the gap between the ML/AI world and a world that exemplifies successful democratization of data technology: databases. I will show how new bridges rooted in the principles, techniques, and tools of the database world are helping tackle the above pressing concerns and in turn, posing new research questions to the world of ML/AI. As case studies of such bridges, I will describe two lines of work from my group: query optimization for scalable deep learning systems and benchmarking data preparation in AutoML platforms. I will conclude with my thoughts on community mechanisms to foster more such bridges between research worlds and between research and practice.

范举
中国人民大学
讲者简介:范举现任中国人民大学数据工程与知识工程教育部重点实验室副教授、博士生导师,中国计算机学会数据库专家委员会委员、大数据专家委员会委员。近年来聚焦面向人工智能的数据准备、众包数据管理、大数据分析等研究方向,相关成果在计算机领域A类期刊和会议上发表论文40余篇。作为负责人先后获得国家自然科学基金优秀青年基金项目、重点项目课题、面上项目、青年项目,以及多项腾讯犀牛鸟基金项目。获得了2017年度ACM中国新星奖、2020年度中国人民大学教学标兵等奖励。
报告题目:面向人工智能的数据准备技术:机遇与挑战
报告摘要:数据是构建人工智能系统的核心要素——如果没有正确的数据,人工智能系统不仅会面临错误风险,而且会因偏置等问题给社会带来危险。因此,数据准备技术,即如何系统地解决数据质量、数据偏差、数据标注等难题,正在成为人工智能的关键基础能力之一。尽管其中的一些问题(如数据集成、数据清洗等)是数据管理领域长期以来的研究热点,人工智能的独特场景带来了一系列全新的挑战。围绕这些挑战,近年来数据管理与机器学习领域进行了深入的研究。本报告聚焦面向人工智能的数据准备技术进行分享。首先是介绍面向人工智能的数据准备基本问题与关键挑战;其次是梳理现有的研究工作,并介绍一些关键性的进展,包括面向机器学习的数据发现/合成、成本高效的数据集成/清洗、人机混合的数据标注等;最后是对一些尚待解决的问题与研究挑战进行探讨。

姚权铭
清华大学
讲者简介:姚权铭是清华大学电子工程系助理教授。他于香港科技大学计算机系取得博士学位,之后加入第四范式担任高级科学家,创建和领导公司的机器学习研究组。该团队为国内最早一批从事自动化机器学习的研究团队。他已发表CCF-A类论文50余篇,谷歌学术引用3800余次。其中,抗噪标签算法Co-teaching(NeurIPS 2018)为当年10大高引论文之一,小样本领域概述论文(CSUR 2020)为ESI热点论文(前0.1%被引),图数据自动化学习方法PAS(CIKM 2021)和AutoSF(TPAMI 2022)为OGB榜单问鼎算法。最后,他也是机器学习主要会议ICML/NeurIPS/ICLR的领域主席、Neural Network期刊的编委、NeurIPS首届AutoML比赛的举办者之一。
报告题目:自动化机器学习原理方法与应用
报告摘要:随着机器学习技术的普及,相关技术在解决实际应用和科学难题上的能力都得到了显著体现。但为了取得较好学习效果,基于领域先验知识去定制和调优学习方法必不可少,这激化了机器学习在实际应用中“通用”v.s.“专用”的核心矛盾。为取得两全其美的效果,自动化机器学习(AutoML)技术应运而生。本次报告将首先介绍AutoML核心原理和重点方法;接着将结合以上背景,以自动化知识图谱的学习为范例,详细阐述AutoML在模型搜索和超参数调优方面的应用;最后,将讨论和展望AutoML和数据科学结合的未来工作。相关工作近期已刊载于TPAMI、KDD、ACL等会议和期刊上,同时在图数据重要榜单Open Graph Benchmark(OGB)相关任务上取得榜首效果。
学术主任
李国良
李国良,清华大学计算机系教授,系副主任。主要研究数据库、大数据挖掘与分析。在数据库顶级会议和期刊上发表论文150余篇,他引12000余次。主持国家杰青、优青、青年973、重点等项目。获得了VLDB杰出青年贡献奖、IEEE 数据工程领域杰出新人奖、计算机学会青年科学家奖等奖项。SIGMOD 2021大会主席、VLDB 2021 Demo主席、ICDE 2022 Industry主席。获得过Best of VLDB 2020/ICDE 2018/KDD 2018, CIKM 2017 Best Paper。获得过国家科技进步二等奖、江苏省科技进步一等奖、国家电网科技进步一等奖等奖项。

柴成亮
柴成亮,清华大学博士后。研究领域:数据库、数据挖掘、数据准备等。在CCF A类会议和期刊发表论文30余篇,包括SIGMOD、VLDB、ICDE等。担任多个国际会议与期刊如VLDB、ICDE、KDD、AAAI的审稿人。获得过CCF优博、ACM中国优博等奖项。主持博新计划、国自然青年基金和博士后面上基金等。
时间:2022年6月25-27日
线下地址(疫情允许的情况下):北京•中国科学院计算技术研究所一层报告厅(北京市海淀区中关村科学院南路6号)
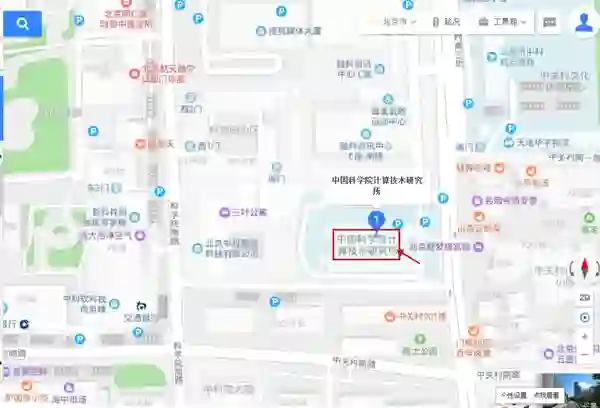
线上地址:报名交费成功后通过邮件发送。
报名须知:
1、报名费:CCF会员2800元,非会员3600元。食宿交通费用自理。根据交费先后顺序,会员优先的原则录取,额满为止。疫情期间,根据政府疫情防控政策随时调整举办形式(线上、线下)。
2、报名截止日期:6月23日。报名请预留不会拦截外部邮件的邮箱,如qq邮箱。
3、咨询邮箱 : adl@ccf.org.cn
缴费方式:
在报名系统中在线缴费或者通过银行转账:
银行转账(支持网银、支付宝):
开户行:招商银行北京海淀支行
户名:中国计算机学会
账号:110943026510701
请务必注明:ADL125+姓名
报名缴费后,报名系统中显示缴费完成,即为报名成功。
报名方式:
请选择以下两种方式之一报名:
1、扫描(识别)以下二维码报名:

2、点击报名链接报名:
https://conf.ccf.org.cn/ADL125
CCF推荐
【精品文章】



点击“阅读原文”,立即报名。



