迁移学习领域自适应:具有类间差异的联合概率最大平均差异

©PaperWeekly 原创 · 作者|张玮玮
学校|东北大学硕士生
研究方向|情感识别


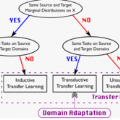
领域适应(DA),或迁移学习,通过将知识从标记的源域转移到新的未标记或部分标记的目标域,广泛应用于图像分类、情绪识别、脑机接口等。传统的 DA 方法遵循这个假设,即主要使用一些度量方法来分别度量边际概率或条件概率分布。然而,联合概率分布可以更好地测量两个域的分布差异。
为了方便利用 DA 方法,在特征转换时需要考虑两个方面:1)可迁移性,它最小化了同一类在不同域之间的差异;2)区分性,它最大限度地扩大了不同域的不同类之间的差异,从而使不同的类更容易区分。
传统的 DA 方法只考虑可迁移性,而忽略了类内可区分性。作者直接考虑了源域和目标域具有不同的联合概率分布的情况, 提出了具有类间差异的联合概率最大平均差异。
通过直接考虑联合概率分布的差异,作者提出了一种用于分布适应的具有类间差异的联合概率 MMD ( discriminative joint probability MMD, DJP-MMD)。

DJP-MMD知识基础
1.1 传统MMD方法
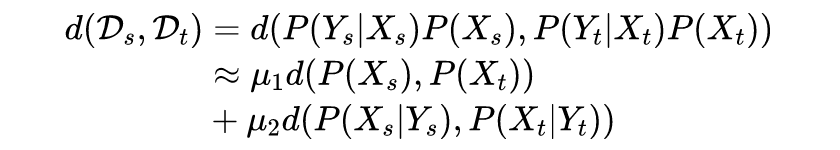
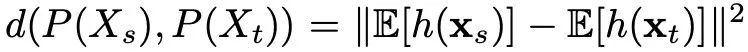
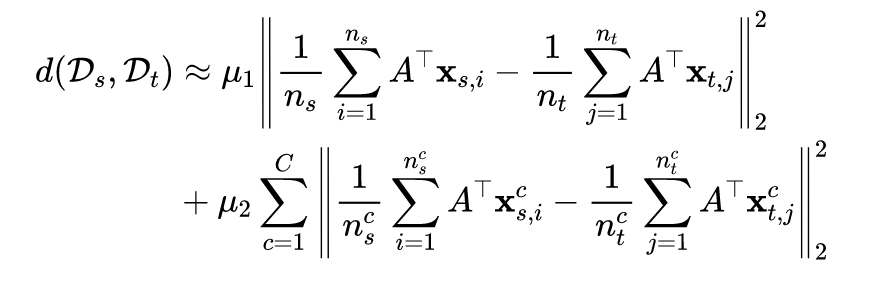

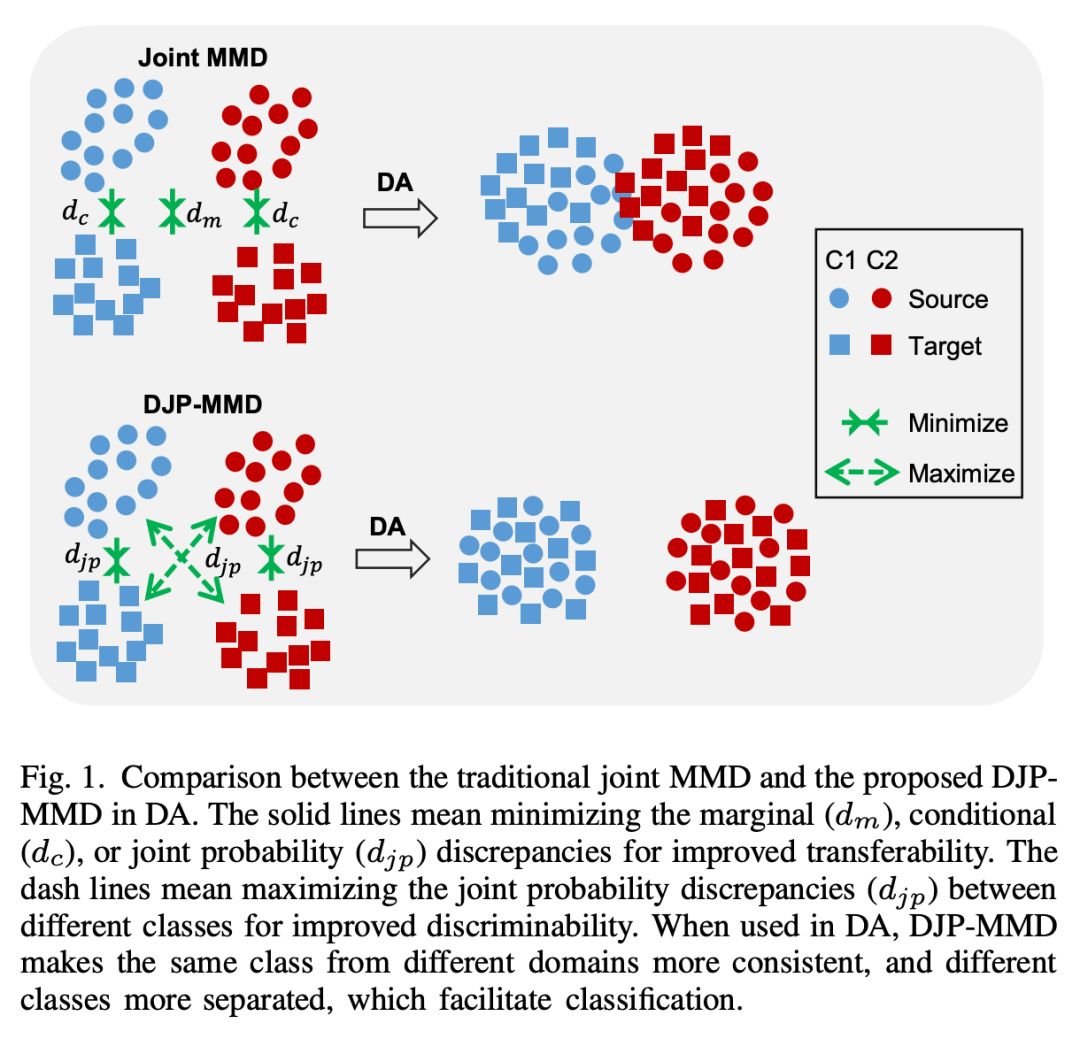
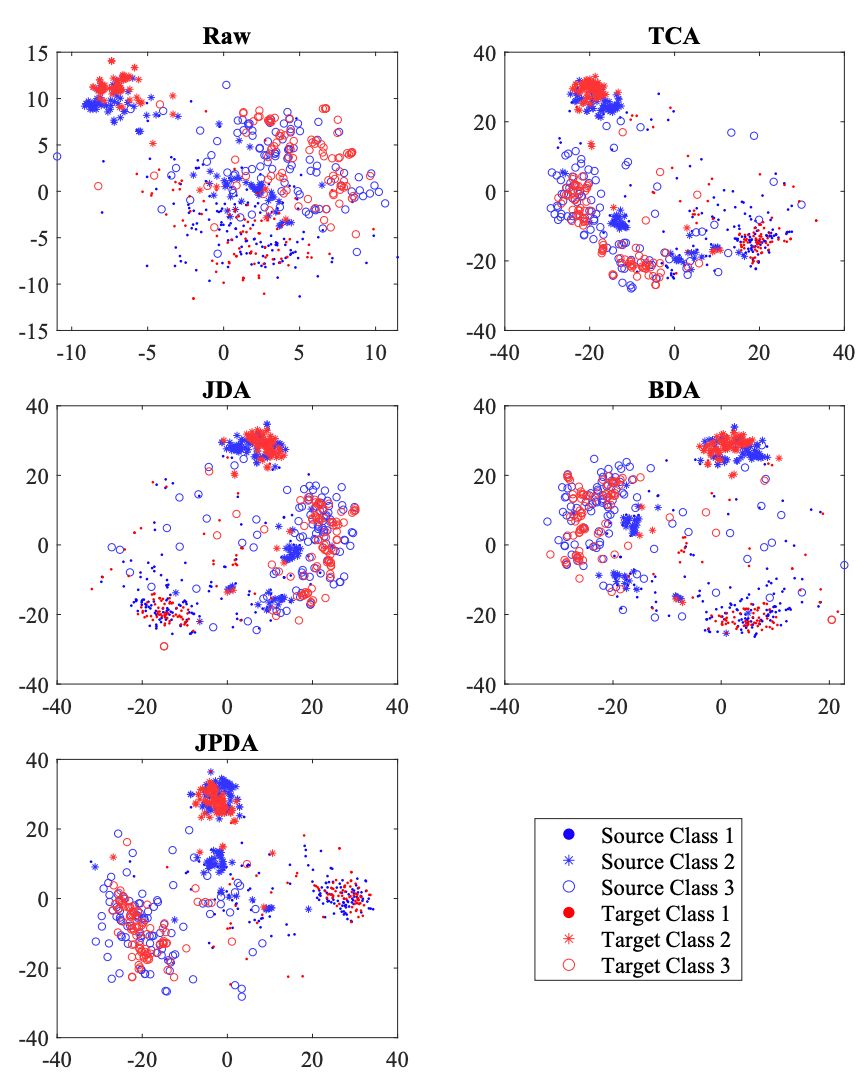
上图将传统的联合 MMD 提出的 DJP-MMD 进行了比较,从图中可以看出,DJP-MMD 使来自不同域的同一个类更加一致,使不同的类更加分离,便于分类。
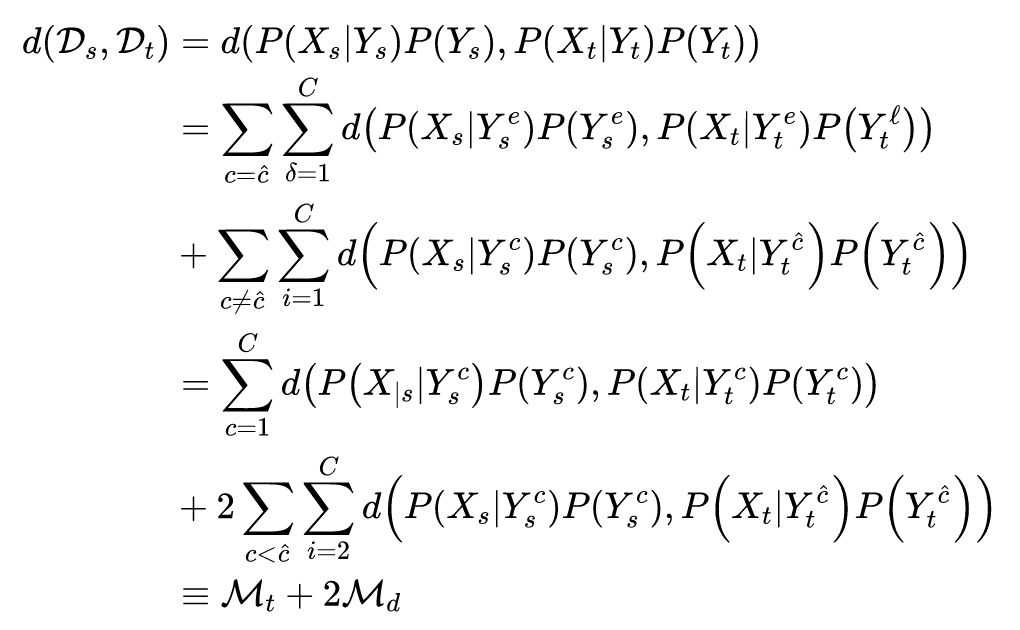
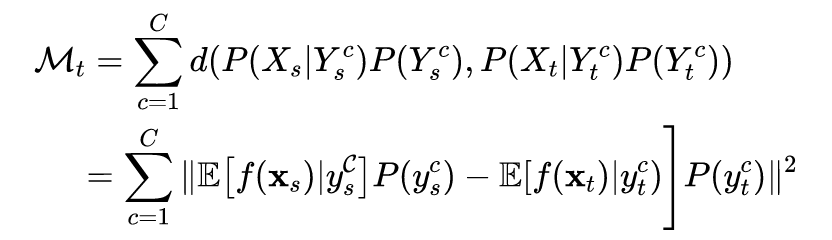
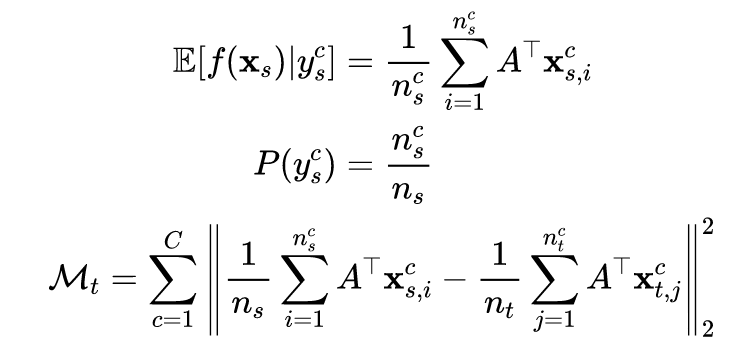
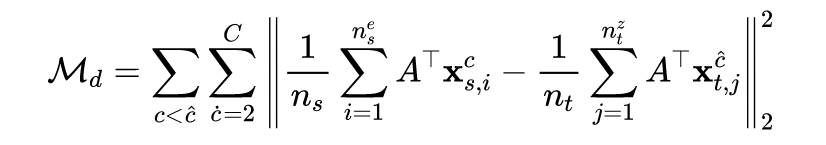
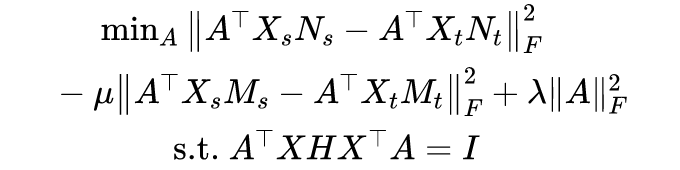
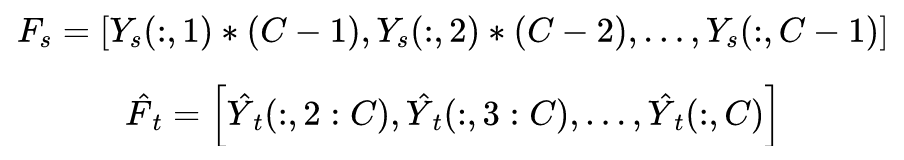
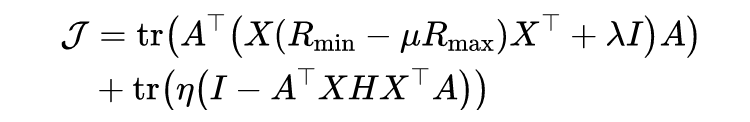
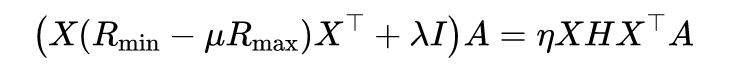
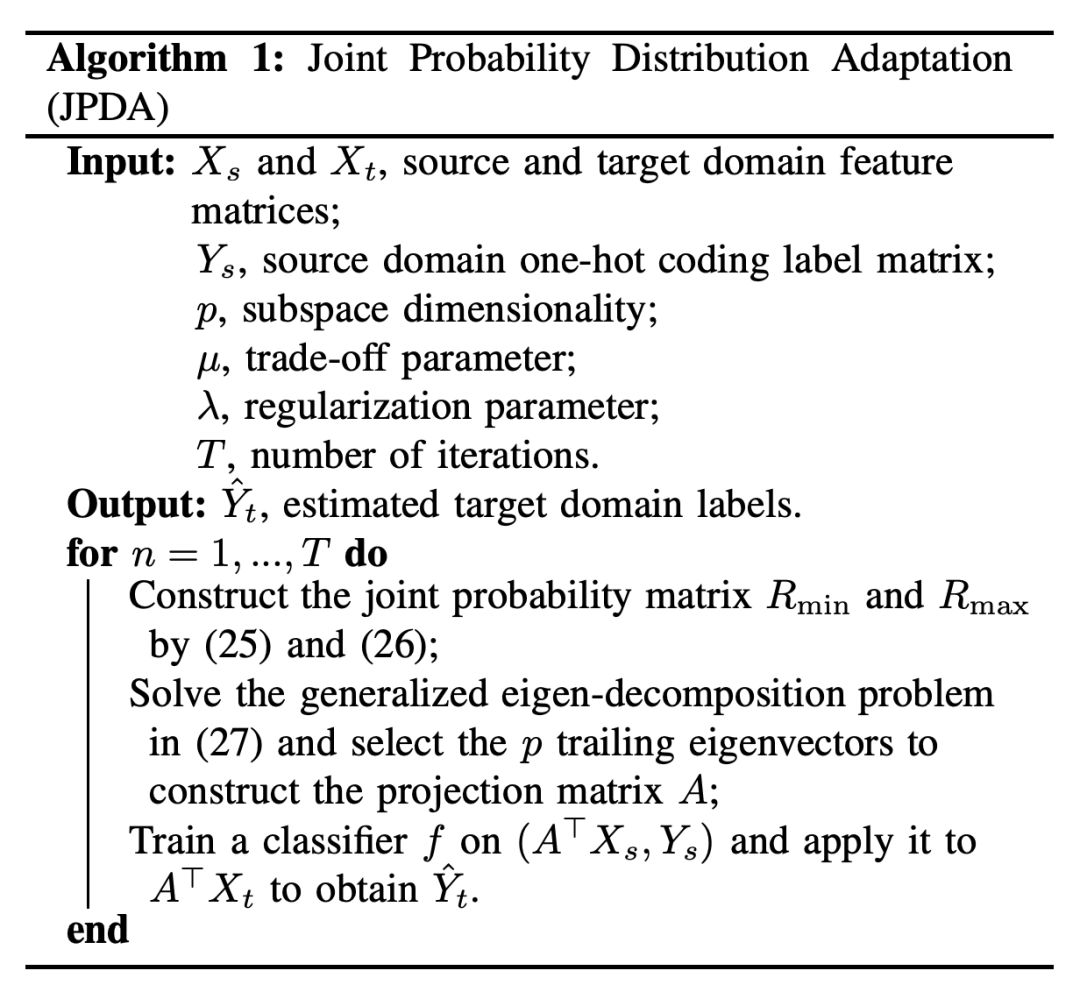

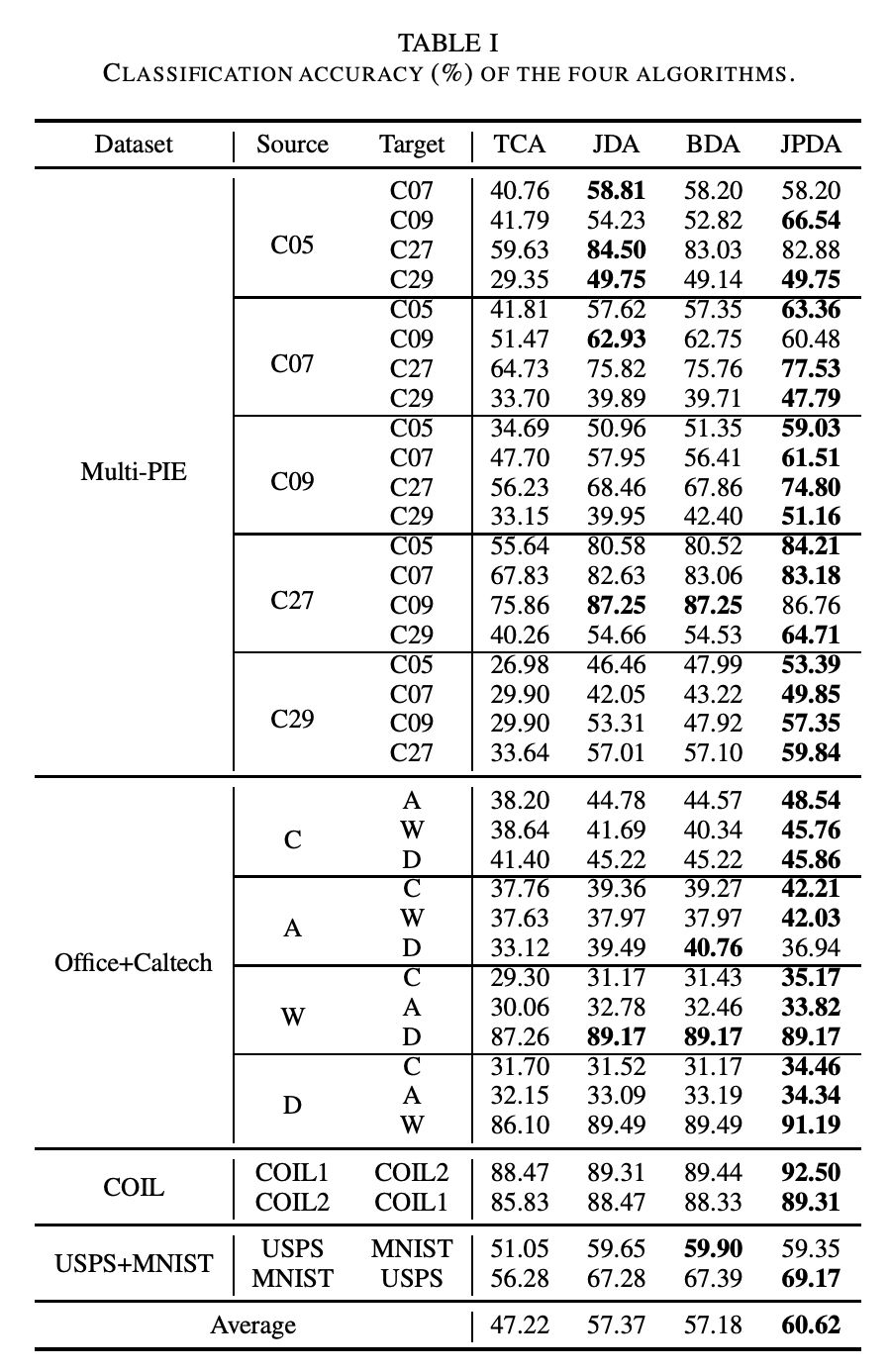
为了评估本文方法的性能,作者在 Offifice+Caltech 、COIL 、Multi-PIE 、USPS 、MNIST 数据集进行了实验,将所提出的 JPDA 与三种无监督 DA 方法(TCA、JDA和BDA)进行比较 。实验结果与 t-SNE 数据分布结果如下图。
JPDA 在大部分任务中都优于 3 个基线实验,平均性能也最好,这说明 JPDA 在跨域视觉适应中可以获得更强的可迁移性和更强的鉴别特征映射。
t-SNE 数据分布图中,Raw 表示原始数据分布。对于原始分布,来自源域和目标域的类 1 和类 3(也有一些来自类 2)的样本混合在一起。在 DA 之后,JPDA 将源域和目标域的数据分布放在一起,并将来自不同类的样本很好地分隔开。
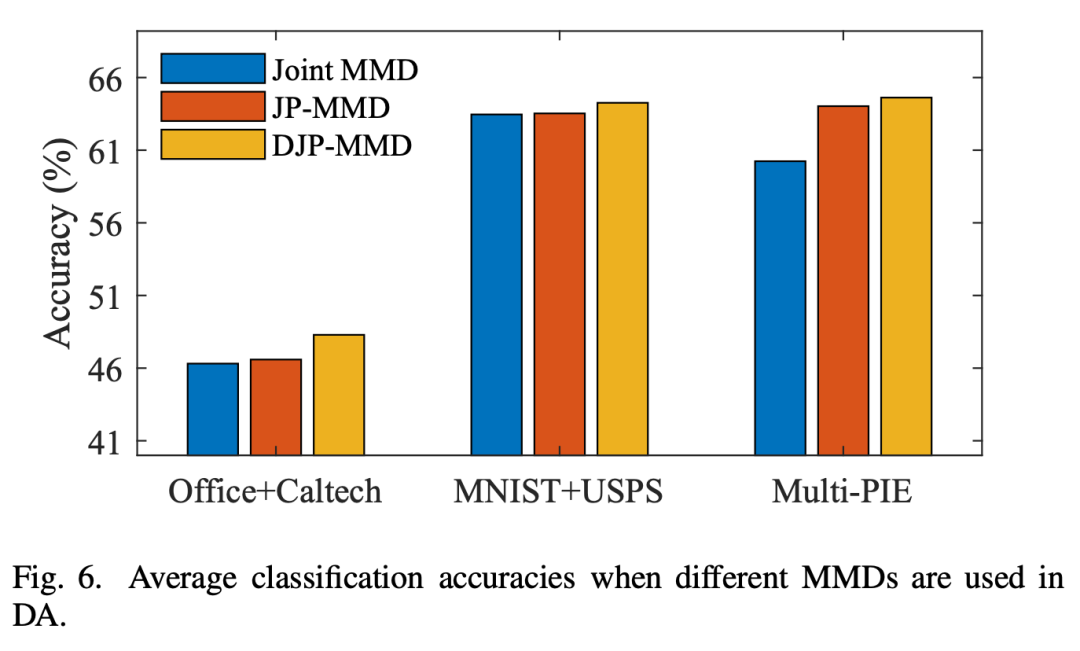
从柱形图上看,JP-MMD 优于联合 MMD,而 DJP-MMD 进一步考虑了可分辨性,获得了最好的分类性能。

本文提出了一种简单而有效的 DJP-MMD 方法。通过最小化源域和目标域(即,提高域可转移性),最大限度地提高不同类的联合概率 MMD(即,增加类的辨别力)。
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。