PaddlePaddle版Flappy-Bird—使用DQN算法实现游戏智能

刚刚举行的 WAVE SUMMIT 2019 深度学习开发者峰会上,PaddlePaddle 发布了 PARL 1.1 版本,这一版新增了 IMPALA、A3C、A2C 等一系列并行算法。作者重新测试了一遍内置 example,发现卷积速度也明显加快,从 1.0 版本的训练一帧需大约 1 秒优化到了 0.15 秒(配置:win8,i5-6200U,GeForce-940M,batch-size=32)。
嘿嘿,超级本实现游戏智能的时代终于来临!废话不多说,我们赶紧试试 PARL 的官方 DQN 算法,玩一玩 Flappy-Bird。
关于作者:曹天明(kosora),2011 年毕业于天津科技大学,7 年的 PHP+Java 经验。个人研究方向——融合 CLRS 与 DRL 两大技术体系,并行刷题和模型训练。专注于游戏智能、少儿趣味编程两大领域。
模拟环境
相信大家对于这个游戏并不陌生,我们需要控制一只小鸟向前飞行,只有飞翔、下落两种操作,小鸟每穿过一根柱子,总分就会增加。由于柱子是高低不平的,所以需要想尽办法躲避它们。一旦碰到了柱子,或者碰到了上、下边缘,都会导致 game-over。下图展示了未经训练的小笨鸟,可以看到,他处于人工智障的状态,经常撞柱子或者撞草地:

▲ 未经训练的小笨鸟
先简要分析一下环境 Environment 的主要代码。
BirdEnv.py 继承自 gym.Env,实现了 init、reset、reward、render 等标准接口。init 函数,用于加载图片、声音等外部文件,并初始化得分、小鸟位置、上下边缘、水管位置等环境信息:
def __init__(self):
if not hasattr(self,'IMAGES'):
print('InitGame!')
self.beforeInit()
self.score = self.playerIndex = self.loopIter = 0
self.playerx = int(SCREENWIDTH * 0.3)
self.playery = int((SCREENHEIGHT - self.PLAYER_HEIGHT) / 2.25)
self.baseShift = self.IMAGES['base'].get_width() - self.BACKGROUND_WIDTH
newPipe1 = getRandomPipe(self.PIPE_HEIGHT)
newPipe2 = getRandomPipe(self.PIPE_HEIGHT)
#...other codestep 函数,执行两个动作,0 表示不采取行动(小鸟会自动下落),1 表示飞翔;step 函数有四个返回值,image_data 表示当前状态,也就是游戏画面,reward 表示本次 step 的即时奖励,terminal 表示是否是吸收状态,{} 表示其他信息:
def step(self, input_action=0):
pygame.event.pump()
reward = 0.1
terminal = False
if input_action == 1:
if self.playery > -2 * self.PLAYER_HEIGHT:
self.playerVelY = self.playerFlapAcc
self.playerFlapped = True
#...other code
image_data=self.render()
return image_data, reward, terminal,{}奖励 reward;初始奖励是 +0.1,表示小鸟向前飞行一小段距离;穿过柱子,奖励 +1;撞到柱子,奖励为 -1,并且到达 terminal 状态:
#飞行一段距离,奖励+0.1
reward = 0.1
#...other code
playerMidPos = self.playerx + self.PLAYER_WIDTH / 2
for pipe in self.upperPipes:
pipeMidPos = pipe['x'] + self.PIPE_WIDTH / 2
#穿过一个柱子奖励加1
if pipeMidPos <= playerMidPos < pipeMidPos + 4:
self.score += 1
reward = self.reward(1)
#...other code
if isCrash:
#撞到边缘或者撞到柱子,结束,并且奖励为-1
terminal = True
reward = self.reward(-1)reward 函数,返回即时奖励 r:
def reward(self,r):
return rreset 函数,调用 init,并执行一次飞翔操作,返回 observation,reward,isOver:
def reset(self,mode='train'):
self.__init__()
self.mode=mode
action0 = 1
observation, reward, isOver,_ = self.step(action0)
return observation,reward,isOver
render 函数,渲染游戏界面,并返回当前画面:
def render(self):
image_data = pygame.surfarray.array3d(pygame.display.get_surface())
pygame.display.update()
self.FPSCLOCK.tick(FPS)
return image_data至此,强化学习所需的状态、动作、奖励等功能均定义完毕。接下来简单推导一下 DQN (Deep-Q-Network) 算法的原理。
DQN的发展过程
DQN 的进化历史可谓源远流长,从最开始 Bellman 在 1956 年提出的动态规划,到后来 Watkins 在 1989 年提出的的 Q-learning,再到 DeepMind 的 Nature-2015 稳定版,最后到 Dueling DQN、Priority Replay Memory、Parameter Noise 等优化算法,横跨整整一个甲子,凝聚了无数专家、教授们的心血。如今的我们站在先贤们的肩膀上,从以下角度逐步分析:
贝尔曼(最优)方程与 VQ 树
Q-learning
参数化逼近
DQN 算法框架
贝尔曼 (最优) 方程与VQ树
我们从经典的表格型强化学习(Tabular Reinforcement Learning)开始,回忆一下马尔可夫决策(MDP)过程,MDP 可由五元组 (S,A,P,R,γ) 表示,其中:
S 状态集合,维度为 1×|S|
A 动作集合,维度为 1×|A|
P 状态转移概率矩阵,经常写成
,其维度为 |S|×|A|×|S|
R 回报函数,如果依赖于状态值函数 V,维度为 1×|S|,如果依赖于状态-动作值函数 Q,则维度为 |S|×|A|
γ 折扣因子,用来计算带折扣的累计回报 G(t),维度为 1
S、A、R、γ 均不难理解,可能部分同学对有疑问——既然 S 和 A 确定了,下一个状态 S' 不是也确定了吗?为什么会有概率转移矩阵呢?
其实我初学的时候也曾经被这个问题困扰过,不妨通过如下两个例子以示区别:
1. 恒等于 1.0 的情况。如图 1 所示,也就是上一次我们在策略梯度算法中所使用的迷宫,假设机器人处于左上角,这时候你命令机器人向右走,那么他转移到红框所示位置的概率就是 1.0,不会有任何异议:
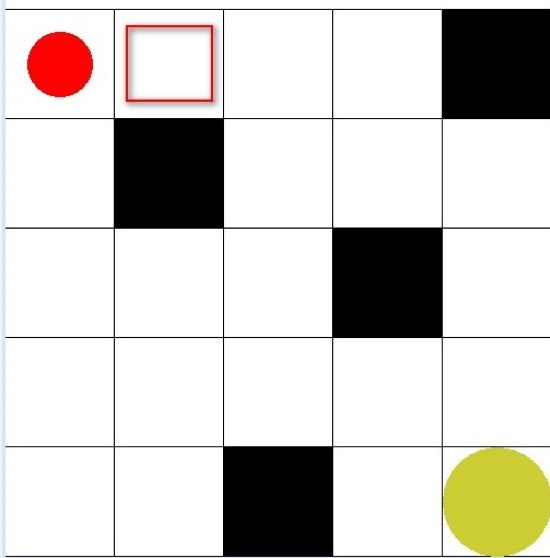
▲ 图1. 迷宫寻宝
2. 不等于 1.0 的情况。假设现在我们下一个飞行棋,如图 2 所示。有两种骰子,第一种是普通的正方体骰子,可以投出 1~6,第二种是正四面体的骰子,可以投出 1~4。现在飞机处于红框所示的位置,现在我们选择投掷第二种骰子这个动作,由于骰子本身具有均匀随机性,所以飞机转移到终点的概率仅仅是 0.25。这就说明,在某些环境中,给定 S、A 的情况下,转移到具体哪一个 S' 其实是不确定的:

▲ 图2. 飞行棋
除了经典的五元组外,为了研究长期回报,还经常加入三个重要的元素,分别是:
策略 π(a∣s),维度为 |S|×|A|
状态值函数
,维度为 1×|S|,表示当智能体采用策略 π 时,累积回报在状态 s 处的期望值:
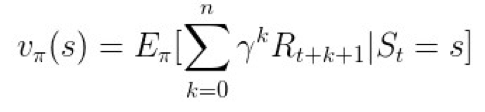
▲ 图3. 状态值函数
状态-行为值函数
,也叫状态-动作值函数,维度为 |S|×|A|,表示当智能体采取策略 π 时,累计回报在状态 s 处并执行动作 a 时的期望值:
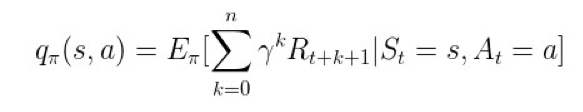
▲ 图4. 状态-行为值函数
知道了 π、v、q 的具体含义后,我们来看一个重要的概念,也就是 V、Q 的递归展开式。
学过动态规划的同学都知道,动态规划本质上是一个 bootstrap(自举)问题,它包含最优子结构与重叠子问题两个性质,也就是说,通常有两种方法解决动态规划:
将总问题划分为 k 个子问题,递归求解这些子问题,然后将子问题进行合并,得到总问题的最优解;对于重复的子问题,我们可以将他们进行缓存(记忆搜索 MemorySearch,请回忆 f(n)=f(n-1)+f(n-2) 这个递归程序);
计算最小的子问题,合并这些子问题产生一个更大的子问题,不断的自底向上计算,随着子问题的规模越来越大,我们会得到最终的总问题的最优解(打表 DP,请回忆杨辉三角中的 dp[i-1,j-1]+dp[i-1,j]=dp[i,j])。
这两种切题技巧,对于有过 ACM 或者 LeetCode 刷题经验的同学,可以说是老朋友了,那么能否把以上思想迁移到强化学习呢?答案是肯定的!
分别考虑 v、q 的展开式:
处在状态 s 时,由于有策略 π 的存在,故可以把状态值函数 v 展开成以下形式:
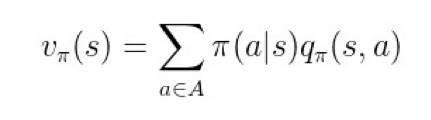
▲ 图5. v展开成q
这个公式表示:在状态 s 处的值函数,等于采取策略 π 时,所有状态-行为值函数的总和。
处在状态 s、并执行动作 a,可以把状态-行为值函数 q 展开成以下形式:
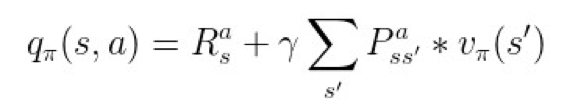
▲ 图6. q展开成v
这个公式表示:在状态 s 采用动作 a 的状态行为值函数,等于回报加上后序可能产生的的状态值函数的总和。
我们可以看到:v 可以展开成 q,同时 q 也可以展开成 v。
所以可以用以下 v、q 节点相隔的树来表示以上两个公式,这颗树比纯粹的公式更容易理解,我习惯上把它叫做 V-Q 树,它显然是一个递归的结构:
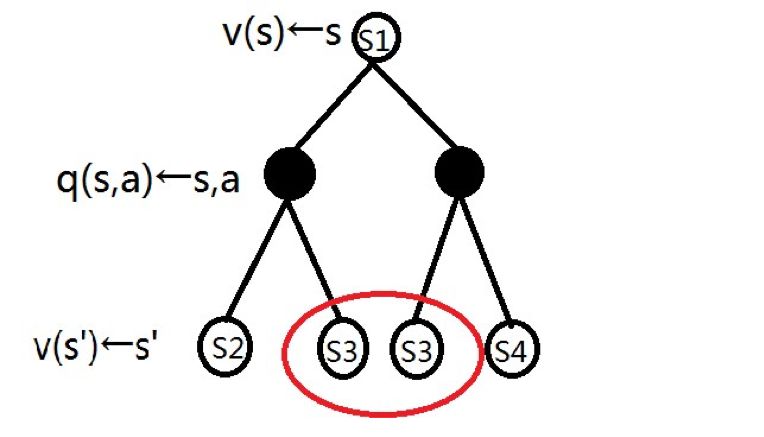
▲ 图7. V-Q树
注意画红圈中的两个节点,体现了重叠子问题特性。如何理解这个性质呢?不妨回忆一下上文提到的飞行棋,假设飞机处在起点位置 1,那么无论投掷 1 号骰子还是 2 号骰子,都是有机会可以到达位置 3 的,这就是重叠子问题的一个例子。
有了这棵递归树之后,就不难推导出 v 和 v',以及 q 和 q' 自身的递归展开式:
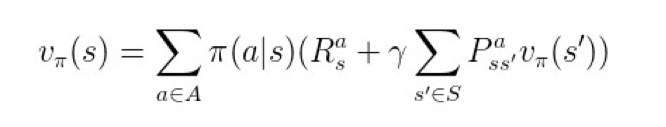
▲ 图8. 状态值函数v自身的递归展开式
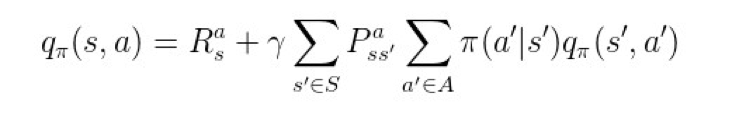
▲ 图9. 状态-行为值函数q自身的递归展开式
其实无论是 v 还是 q,都拥有最优子结构特性。不妨利用反证法加以证明:
假设要求总问题 V(s) 的最优解,那么它包含的每个子问题 V(s') 也必须是最优解;否则,如果某个子问题 V(s') 不是最优,那么必然有一个更优的子问题 V'(s') 存在,使得总问题 V'(s) 比原来的总问题 V(s) 更优,与我们的假设相矛盾,故最优子结构性质得证,q(s) 的最优子结构性质同理。
计算值函数的目的是为了构建学习算法得到最优策略,每个策略对应着一个状态值函数,最优策略自然也对应着最优状态值函数,故而定义如下两个函数:
最优状态值函数
,表示在所有策略中最大的值函数,即:
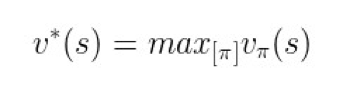
▲ 图10. 最优状态值函数
最优状态-行为值函数
,表示在所有策略中最大的状态-行为值函数:
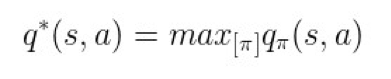
▲ 图11. 最优状态-行为值函数
结合上文的递归展开式和最优子结构性质,可以得到 v 与 q 的贝尔曼最优方程:
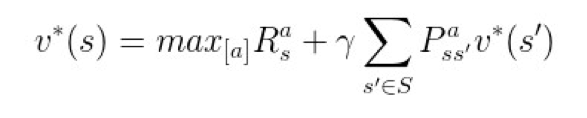
▲ 图12. v的贝尔曼最优方程
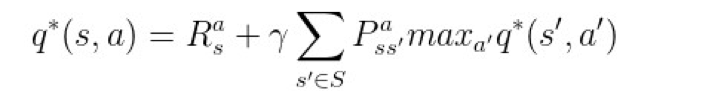
▲ 图13. q的贝尔曼最优方程
重点理解第二个公式,也就是关于 q 的贝尔曼最优方程,它是今天的主角 Q-learning 以及 DQN 的理论基础。
有了贝尔曼最优方程,我们就可以通过纯粹贪心的策略来确定 π,即:仅仅把最优动作的概率设置为 1,其他所有非最优动作的概率都设置为 0。这样做的好处是:当算法收敛的时候,策略 π(a|s) 必然是一个 one-hot 型的矩阵。用数学公式表达如下:
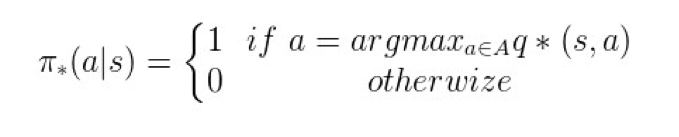
▲ 图14. 算法收敛时候的策略π
强化学习中的动态规划方法实质上是一种 model-based(模型已知)方法,因为 MDP 五元组是已知的,特别是状态转移概率矩阵是已知的。
也就是说,所有的环境信息对于我们来说是 100% 完备的,故而可以对整个解空间树进行全局搜索,下图展示了动态规划方法的示意图,在确定根节点状态 S(t) 的最优值的时候,必须遍历他所有的 S(t+1) 子节点并选出最优解:
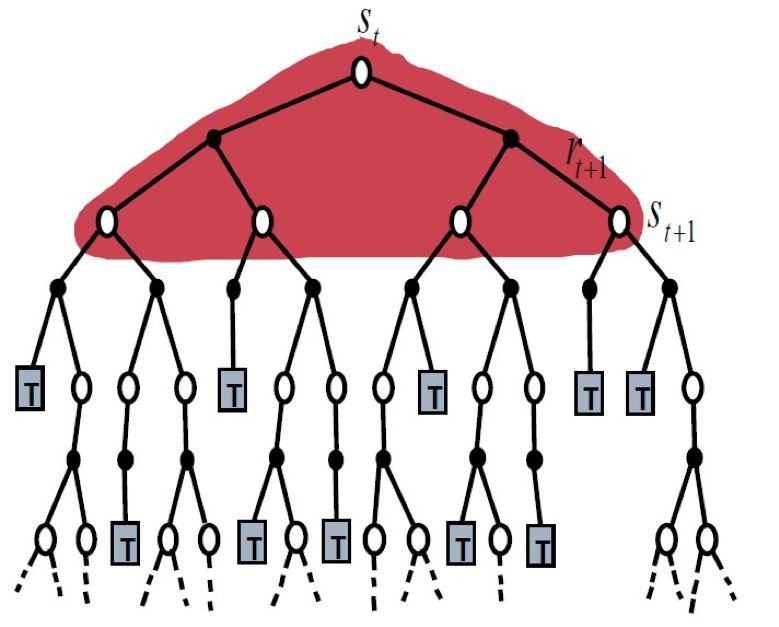
▲ 图15. 动态规划方法的解空间搜索过程
不过,和传统的刷题动态规划略有不同,强化学习往往是利用值迭代(Value Iteration)、策略迭代(Policy Iteration)、策略改善(Policy Improve)等方式使 v、q、π 等元素达到收敛状态,当然也有直接利用矩阵求逆计算解析解的方法,有兴趣的同学可以参考相关文献,这里不再赘述。
Q-learning
上文提到的动态规划方法是一种 model-based 方法,仅仅适用于已知的情况。若状态转移概率矩阵未知,model-free(无模型)方法就派上用场了,上一期的 MCPG 算法就是一种典型的 model-free 方法。它搜索解空间的方式更像是 DFS(深度优先搜索),而且一条道走到黑,没有指针回溯的操作,下图展示了蒙特卡洛算法的求解示意图:
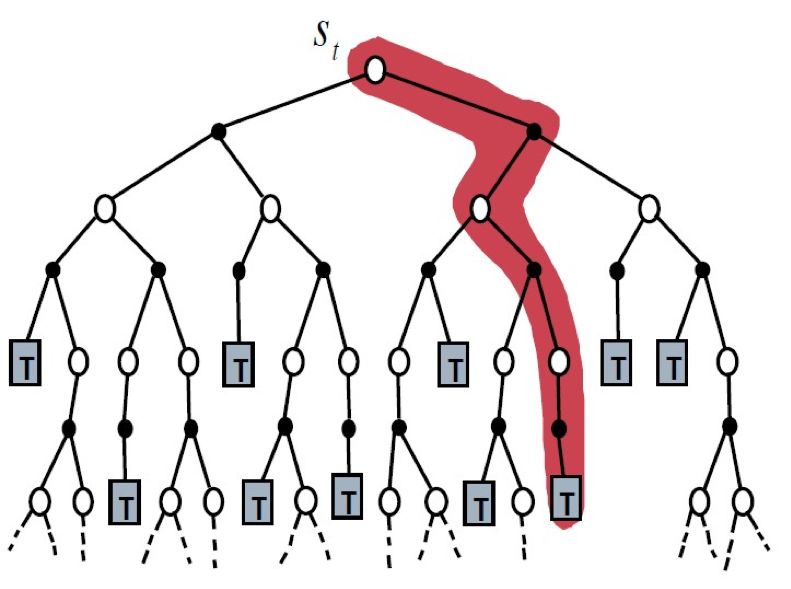
▲ 图16. MC系列方法的解空间搜索过程
虽然每次只能走一条分支,但随机数发生器会帮助算法遍历整个解空间,再通过大量的迭代,所有节点也会收敛到最优解。
不过,MC 类方法有两个小缺点:
1. 使用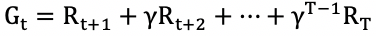
2. 由于采用的是一条道走到黑的方式从根节点遍历到叶子节点,所以必须要等到 episode 结束才能进行训练,而且每轮 episode 产生的数据只训练一次,每轮 episode 产生数据的 batch-size 还不一定相同,所以在训练过程中,MC 方法的 loss 函数(或者 TD-Error)的波动幅度较大,而数据利用效率不高。
那么,能否边产生数据边训练呢?可以!时序差分(Temporal-Difference-Learning,简称 TD)算法应运而生了。
时序差分学习是模拟(或者经历)一段序列,每行动一步(或者几步)就根据新状态的价值估计当前执行的状态价值。大致可以分为两个小类:
1. TD(0) 算法,只向后估计一个 step。其值函数更新公式为:
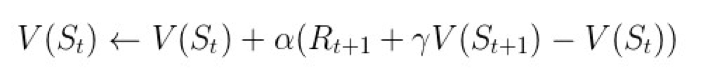
▲ 图17. TD(0)算法的更新公式
其中,α 为学习率,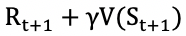
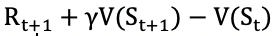
2. Sarsa(λ) 算法,向后估计 n 步,n 为有限值,还有一个衰减因子 λ。其值函数的更新公式为:
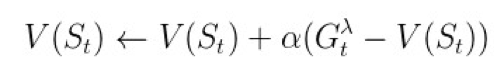
▲ 图18. Sarsa(λ)算法的更新公式
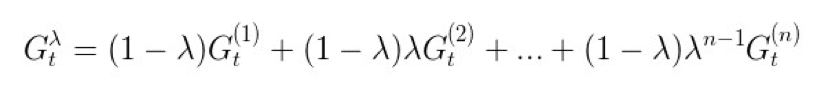
▲ 图19. 的计算方法
与 MC 方法相比,TD 方法只用到了一步或者有限步随机状态和动作,因此它是一个有偏估计。不过,由于 TD 目标的随机性比 MC 方法的 G(t) 要小,所以方差也比 MC 方法小的多,值函数的波动幅度较小,训练比较稳定。
看一下 TD 方法的解空间搜索示意图,红框表示 TD(0),蓝框表示 Sarsa(λ)。虽然每次估计都有一定的偏差,但随着算法的不断迭代,所有的节点也会收敛到最优解:
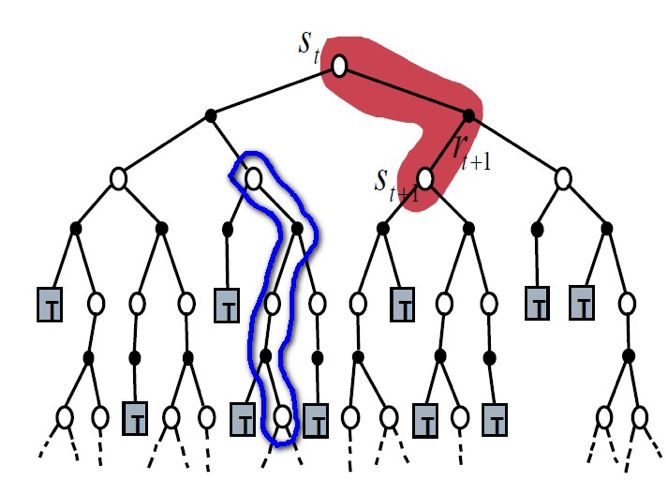
▲ 图20. TD方法的解空间搜索过程
有了 TD 的框架,既然我们要求状态值函数 v、状态-行为值函数 q 的最优解,那么是否能直接选择最优的 TD 目标作为 Target 呢?答案是肯定的,这也是 Q-Learning 算法的基本思想,其公式如下所示:
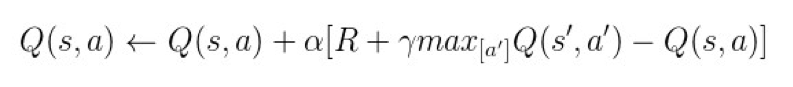
▲ 图21. Q-learning算法的学习公式
其中,动作 a 由 ε-greedy 策略选出,从而在状态 s 处执行 a 之后产生了另一个状态 s',接下来选出状态 s' 处最大的状态-行为值函数 q(s',a'),这样,TD 目标就可以确定为 R+γmax[a′]Q(s′,a′)。这种思想很像贪心算法中的总是选择在当前看来最优的决策,它一开始可能会得到一个局部最优解,不过没关系,随着算法的不断迭代,整个解空间树也会收敛到全局最优解。
以下是 Q-learning 算法的伪代码,和 on-policy 的 MC 方法对应,它是一种 off-policy(异策略)方法:
#define maxEpisode=65535 //定义最大迭代轮数
#define maxStep=1024 //定义每一轮最多走多少步
initialize Q_table[|S|,|A|] //初始化Q矩阵
for i in range(0,maxEpisode):
s=env.reset() //初始化状态s
for j in range(0,maxStep):
//用ε-greedy策略在s行选一个动作a
choose action a using ε-greedy from Q_table[s]
s',R,terminal,_=env.step(a) //执行动作a,得到下一个状态s',奖励R,是否结束terminal
max_s_prime_action=np.max(Q_table[s',:]) //选s'对应的最大行为值函数
td=R+γ*max_s_prime_action //计算TD目标
Q_table[s,a]= Q_table[s,a]+α*(td-Q_table[s,a]) //学习Q(s,a)的值
s=s' //更新s,注意,和sarsa算法不同,这里的a不用更新
if terminal:
break
Q-learning 是一种优秀的算法,不仅简单直观,而且平均速度比 MC 快。在 DRL 未出现之前,它在强化学习中的地位,差不多可以媲美 SVM 在机器学习中的地位。
参数化逼近
有了 Q-learning 算法,是否就能一招吃遍天下鲜了呢?答案是否定的,我们看一下它存在的问题。
上文所提到的,无论是 DP、MC 还是 TD,都是基于表格(tabular)的方法,当状态空间比较小的时候,计算机内存完全可以装下,表格式型强化学习是完全适用的。但遇到高阶魔方(三阶魔方的总变化数是)、围棋(
)这类问题时,S、V、Q、P 等表格均会出现维度灾难,早就超出了计算机内存甚至硬盘容量。这时候,参数化逼近方法就派上用场了。
所谓参数化逼近,是指值函数可以由一组参数 θ 来近似,如 Q-learning 中的 Q(s,a) 可以写成 Q(s,a|θ) 的形式。这样,不但降低了存储维度,还便于做一些额外的特征工程,而且 θ 更新的同时,Q(s,a|θ) 会进行整体更新,不仅避免了过拟合情况,还使得模型的泛化能力更强。
既然有了可训练参数,我们就要研究损失函数了,Q-Learning 的损失函数是什么呢?
先看一下 Q-Learning 的优化目标——使得 TD-Error 最小:
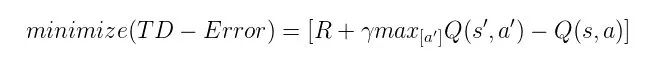
▲ 图22. Q-Learning的优化目标
加入参数 θ 之后,若将 TD 目标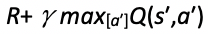
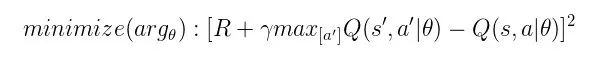
▲ 图23. 带参数的优化目标
这是我们所熟悉的监督学习中的回归问题,显然 loss 函数就是 mse,故而可以用梯度下降算法最小化 loss,从而更新参数 θ:
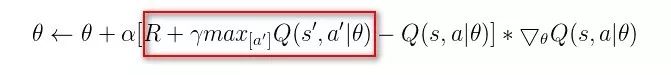
▲ 图24. loss函数的梯度下降公式
注意到,TD 目标是标签,所以 Q(s',a'|θ) 中的 θ 是不能更新的,这种方法并非完全的梯度法,只有部分梯度,称为半梯度法,这是 NIPS-2013 的雏形。
后来,DeepMind 在 Nature-2015 版本中将 TD 网络单独分开,其参数为 θ',它本身并不参与训练,而是每隔固定步数将值函数逼近的网络参数 θ 拷贝给 θ',这样保证了 DQN 的训练更加稳定:
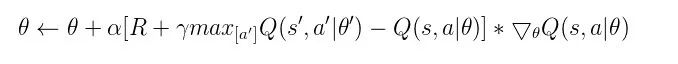
▲ 图25. 含有目标网络参数θ'的梯度下降公式
至此,DQN 的 Loss 函数、梯度下降公式推导完毕。
DQN算法框架
接下来,还要解决两个问题——数据从哪里来?如何采集?
针对以上两个问题,DeepMind 团队提出了深度强化学习的全新训练方法:经验回放(experience replay)。
在强化学习过程中,智能体将数据存储到一个 ReplayBuffer 中(任何一种集合,可以是哈希表、数组、队列,也可以是数据库),然后利用均匀随机采样的方法从 ReplayBuffer 中抽取数据,这些数据就可以进行 Mini-Batch-SGD,这样就打破了数据之间的相关性,使得数据之间尽量符合独立同分布原则。
DQN 的基本网络结构如下:
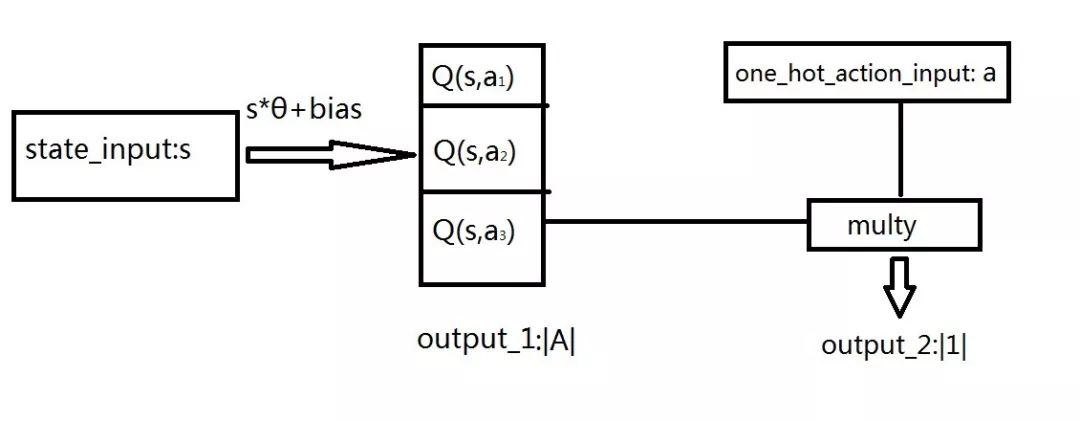
▲ 图26. DQN的基本网络结构
要特别注意:
1. 与参数 θ 做线性运算 (wx+b) 的仅仅是输入状态 s,这一步没有动作 a 的参与;
2. output_1 的维度为 |A|,表示神经网络 Q(s,θ) 的输出;
3. 输入动作 a 是 one-hot,与 output_1 作哈达马积后产生的 output_2 是一个数字,作为损失函数中的 Q(s,a|θ),也就是 y。
以下是 DQN 算法的伪代码:
#Deep-Q-Network,Nature 2015 version
#定义为一个双端队列D,作为经验回放区域,最大长度为max_size
Initialize replay_memory D as a deque,mas_size=50000
#初始化状态-行为值函数Q的神经网络,权值随机
Initialize action-value function Q(s,a|θ) as Neural Network with random-weights-initializer
#初始化TD目标网络,初始权值和θ相等
Initialize target action-value function Q(s,a|θ) with weights θ'=θ
#迭代max_episode个轮次
for episode in range(0,max_episode=65535):
#重置环境env,得到初始状态s
s=env.reset()
#循环事件的每一步,最多迭代max_step_limit个step
for step in range(0,max_step_limit=1024):
#通过ε-greedy的方式选出一个动作action
With probability ε select a random action a or select a=argmax(Q(s,θ))
#在env中执行动作a,得到下一个状态s',奖励R,是否终止terminal
s',R,terminal,_=env.step(a)
#将五元组(s,a,s',R,terminal)压进队尾
D.addLast(s,a,s',R,terminal)
#如果队列满,弹出队头元素
if D.isFull():
D.removeFirst()
#更新状态s
s=s'
#从队列中进行随机采样
batch_experience[s,a,s',R,terminal]=random_select(D,batch_size=32)
#计算TD目标
target = R + γ*(1- terminal) * np.max(Q(s',θ'))
#对loss函数执行Gradient-decent,训练参数θ
θ=θ+α*(target-Q(s,a|θ))▽Q(s,a|θ)
#每隔C步,同步θ与θ'的权值
Every C steps set θ'=θ
#是否结束
if terminal:
break 我们玩的游戏 Flappy-Bird,它的输入是一帧一帧的图片,所以,经典的 Atari-CNN 模型就可以派上用场了:
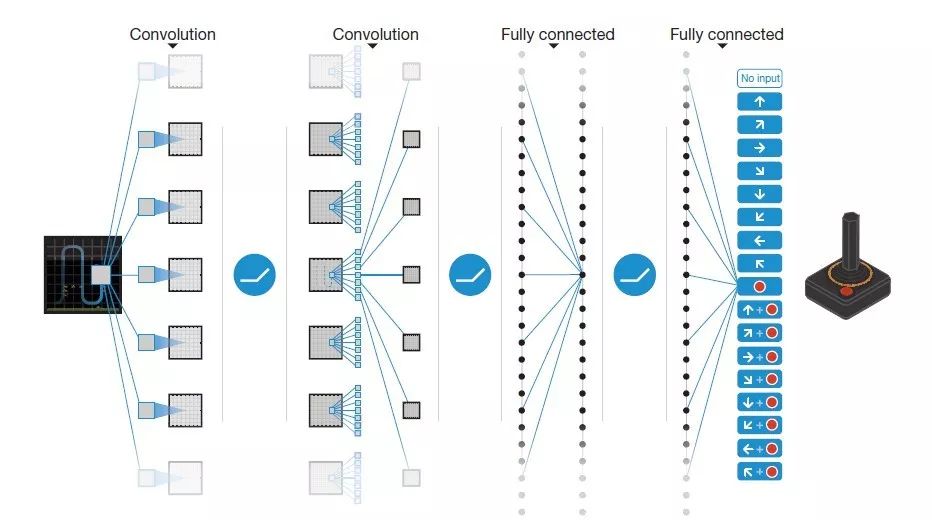
▲ 图27. Atari游戏的CNN网络结构
网络的输入是被处理成灰度图的最近 4 帧 84*84 图像(4 是经验值),经过若干 CNN 和 FullyConnect 后,输出各个动作所对应的状态-行为值函数 Q。以下是每一层的具体参数,由于 atari 游戏最多有 18 个动作,所以最后一层的维度是 18:
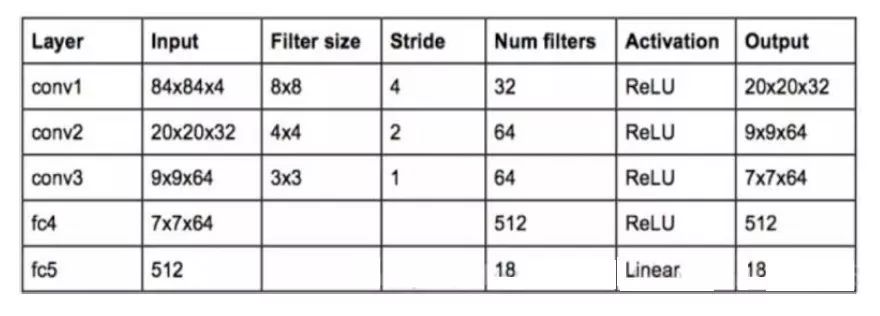
▲ 图28. 神经网络的具体参数
至此,理论部分推导完毕。下面,我们分析一下 PARL 中的 DQN 部分的源码,并实现 Flappy-Bird 的游戏智能。
代码实现
依次分析 env、model、algorithm、agent、replay_memory、train 等模块。
1. BirdEnv.py,环境;上文已经分析过了。
2. BirdModel.py,神经网络模型;使用三层 CNN+两层 FC,CNN 的 padding 方式都是 valid,最后输出状态-行为值函数 Q,维度为 |A|。注意输入图片归一化,并按照官方模板填入代码:
class BirdModel(Model):
def __init__(self, act_dim):
self.act_dim = act_dim
#padding方式为valid
p_valid=0
self.conv1 = layers.conv2d(
num_filters=32, filter_size=8, stride=4, padding=p_valid, act='relu')
self.conv2 = layers.conv2d(
num_filters=64, filter_size=4, stride=2, padding=p_valid, act='relu')
self.conv3 = layers.conv2d(
num_filters=64, filter_size=3, stride=1, padding=p_valid, act='relu')
self.fc0=layers.fc(size=512)
self.fc1 = layers.fc(size=act_dim)
def value(self, obs):
#输入归一化
obs = obs / 255.0
out = self.conv1(obs)
out = self.conv2(out)
out = self.conv3(out)
out = layers.flatten(out, axis=1)
out = self.fc0(out)
out = self.fc1(out)
return out3. dqn.py,算法层;官方仓库已经提供好了,我们无需自己再写,直接复用算法库(parl.algorithms)里边的 DQN 算法即可。
简单分析一下 DQN 的源码实现。
define_learn 函数,用于神经网络的学习。接收 [状态 obs, 动作 action, 即时奖励 reward, 下一个状态 next_obs, 是否终止 terminal] 这样一个五元组,代码实现如下:
#根据obs以及参数θ计算状态-行为值函数pred_value,对应伪代码中的Q(s,θ)
pred_value = self.model.value(obs)
#根据next_obs以及参数θ'计算目标网络的状态-行为值函数next_pred_value,对应伪代码中的Q(s',θ')
next_pred_value = self.target_model.value(next_obs)
#选出next_pred_value的最大值best_v,对应伪代码中的np.max(Q(s',θ'));注意θ'不参与训练,所以要stop_gradient
best_v = layers.reduce_max(next_pred_value, dim=1)
best_v.stop_gradient = True
#计算TD目标
target = reward + (1.0 - layers.cast(terminal, dtype='float32')) * self.gamma * best_v
#输入的动作action与pred_value作哈达玛积,选出要评估的状态-行为值函数pred_action_value,对应伪代码中的 Q(s,a|θ)
action_onehot = layers.one_hot(action, self.action_dim)
action_onehot = layers.cast(action_onehot, dtype='float32')
pred_action_value = layers.reduce_sum(layers.elementwise_mul(action_onehot, pred_value), dim=1)
#mse以及梯度下降,对应伪代码中的θ=θ+α*(target-Q(s,a|θ))▽Q(s,a|θ)
cost = layers.square_error_cost(pred_action_value, target)
cost = layers.reduce_mean(cost)
optimizer = fluid.optimizer.Adam(self.lr, epsilon=1e-3)
optimizer.minimize(cost)sync_target 函数用于同步网络参数:
def sync_target(self, gpu_id):
""" sync parameters of self.target_model with self.model
"""
self.model.sync_params_to(self.target_model, gpu_id=gpu_id)4. BirdAgent.py,智能体。其中,build_program 函数封装了 algorithm 中的 define_predict 和 define_learn,sample 函数以 ε-greedy 策略选择动作,predict 函数以 100% 贪心的策略选择 argmax 动作,learn 函数接收五元组 (obs, act, reward, next_obs, terminal) 完成学习功能,这些函数和 Policy-Gradient 的写法类似。
除了这些常用功能之外,由于游戏的训练时间比较长,所以附加了两个函数,save_params 用于保存模型,load_params 用于加载模型:
#保存模型
def save_params(self, learnDir,predictDir):
fluid.io.save_params(
executor=self.fluid_executor,
dirname=learnDir,
main_program=self.learn_programs[0])
fluid.io.save_params(
executor=self.fluid_executor,
dirname=predictDir,
main_program=self.predict_programs[0])
#加载模型
def load_params(self, learnDir,predictDir):
fluid.io.load_params(
executor=self.fluid_executor,
dirname=learnDir,
main_program=self.learn_programs[0])
fluid.io.load_params(
executor=self.fluid_executor,
dirname=predictDir,
main_program=self.predict_programs[0]) 另外,还有四个超参数,可以进行微调:
#每训练多少步更新target网络,超参数可调
self.update_target_steps = 5000
#初始探索概率ε,超参数可微调
self.exploration = 0.8
#每步探索的衰减程度,超参数可微调
self.exploration_dacay=1e-6
#最小探索概率,超参数可微调
self.min_exploration=0.05
5. replay_memory.py,经验回放单元。双端队列 _context 是一个滑动窗口,用来记录最近 3 帧(再加上新产生的 1 帧就是 4 帧);state、action、reward 等用 numpy 数组存储,因为 numpy 的功能比双端队列更丰富,max_size 表示 replay_memory 的最大容量:
self.state = np.zeros((self.max_size, ) + state_shape, dtype='int32')
self.action = np.zeros((self.max_size, ), dtype='int32')
self.reward = np.zeros((self.max_size, ), dtype='float32')
self.isOver = np.zeros((self.max_size, ), dtype='bool')
#_context是一个滑动窗口,长度永远保持3
self._context = deque(maxlen=context_len - 1)
其他的 append、recent_state、sample_batch 等函数并不难理解,都是基于 numpy 数组的进一步封装,略过一遍即可看懂。
6. Train_Test_Working_Flow.py,训练与测试,让环境 evn 和智能体 agent 进行交互。最重要的就是 run_train_episode 函数,体现了 DQN 的主要逻辑,重点分析注释部分与 DQN 伪代码的对应关系,其他都是编程细节:
#训练一个episode
def run_train_episode(env, agent, rpm):
global trainEpisode
global meanReward
total_reward = 0
all_cost = []
#重置环境
state,_, __ = env.reset()
step = 0
#循环每一步
while True:
context = rpm.recent_state()
context.append(resizeBirdrToAtari(state))
context = np.stack(context, axis=0)
#用ε-greedy的方式选一个动作
action = agent.sample(context)
#执行动作
next_state, reward, isOver,_ = env.step(action)
step += 1
#存入replay_buffer
rpm.append(Experience(resizeBirdrToAtari(state), action, reward, isOver))
if rpm.size() > MEMORY_WARMUP_SIZE:
if step % UPDATE_FREQ == 0:
#从replay_buffer中随机采样
batch_all_state, batch_action, batch_reward, batch_isOver = rpm.sample_batch(batchSize)
batch_state = batch_all_state[:, :CONTEXT_LEN, :, :]
batch_next_state = batch_all_state[:, 1:, :, :]
#执行SGD,训练参数θ
cost=agent.learn(batch_state,batch_action, batch_reward,batch_next_state, batch_isOver)
all_cost.append(float(cost))
total_reward += reward
state = next_state
if isOver or step>=MAX_Step_Limit:
break
if all_cost:
trainEpisode+=1
#以滑动平均的方式打印平均奖励
meanReward=meanReward+(total_reward-meanReward)/trainEpisode
print('\n trainEpisode:{},total_reward:{:.2f}, meanReward:{:.2f} mean_cost:{:.3f}'\
.format(trainEpisode,total_reward, meanReward,np.mean(all_cost)))
return total_reward, step
除了主要逻辑外,还有一些常见的优化手段,防止训练过程中出现 trick:
#充满replay-memory,使其达到warm-up-size才开始训练
MEMORY_WARMUP_SIZE = MEMORY_SIZE//20
##一轮episode最多执行多少次step,不然小鸟会无限制的飞下去,相当于gym.env中的_max_episode_steps属性
MAX_Step_Limit=int(1<<12)
#用一个双端队列记录最近16次episode的平均奖励
avgQueue=deque(maxlen=16)
另外,还有其他一些超参数,比如学习率 LEARNING_RATE、衰减因子 GAMMA、记录日志的频率 log_freq 等等,都可以进行微调:
#衰减因子
GAMMA = 0.99
#学习率
LEARNING_RATE = 1e-3 * 0.5
#记录日志的频率
log_freq=10main 函数在这里,输入 train 训练网络,输入 test 进行测试:
if __name__ == '__main__':
print("train or test ?")
mode=input()
print(mode)
if mode=='train':
train()
elif mode=='test':
test()
else:
print('Invalid input!')
这是模型在我本机训练的输出日志,大概 3300 个 episode、50 万步之后,模型就收敛了:
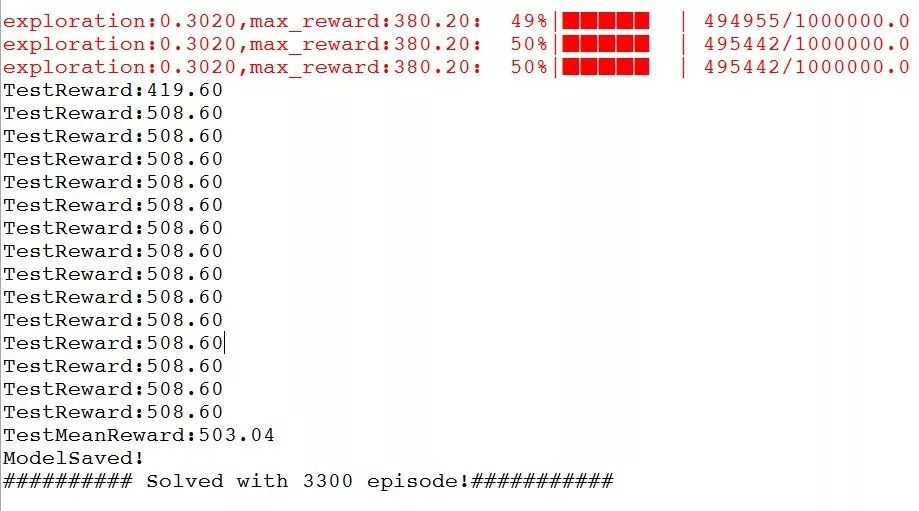
▲ 图29. 模型训练的输出日志
平均奖励:
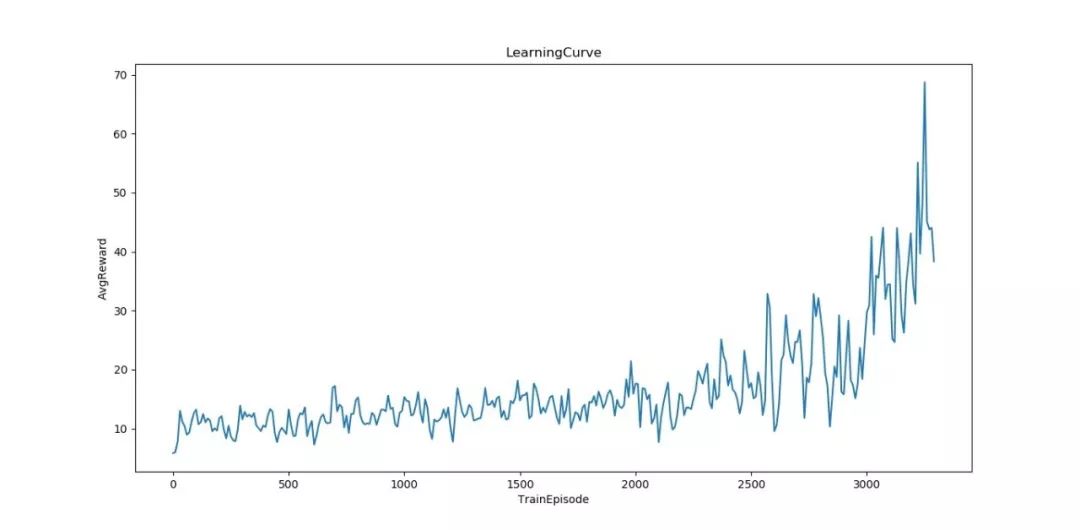
▲ 图30. 最近16次平均奖励变化曲线
各位同学可以试着调节超参数,或者修改网络模型,看看能不能遇到一些坑?哪些因素会影响训练效率?如何提升收敛速度?
接下来就是见证奇迹的时刻,当初懵懂的小笨鸟,如今已修炼成精了!
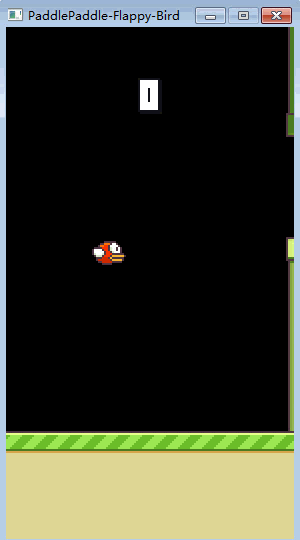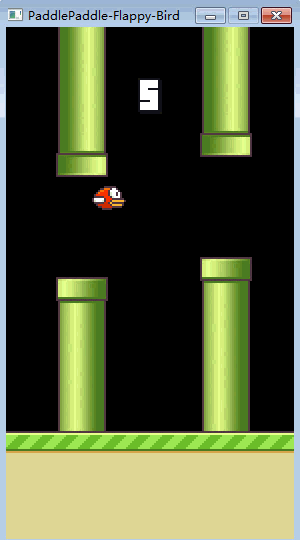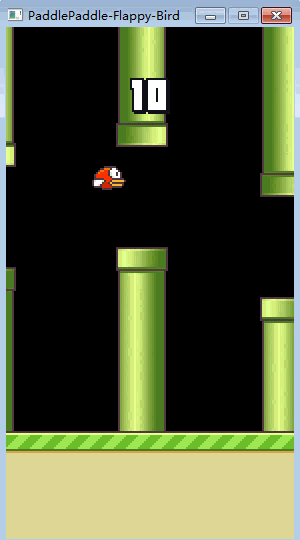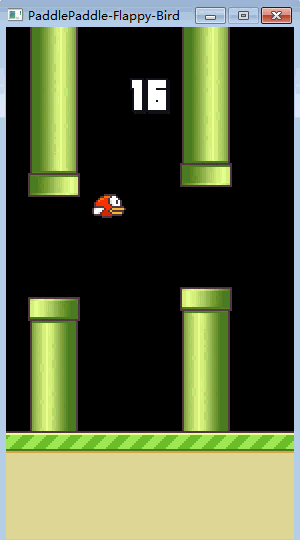
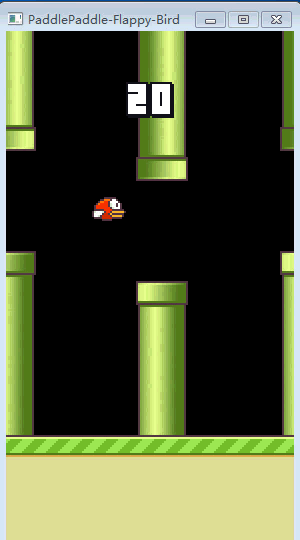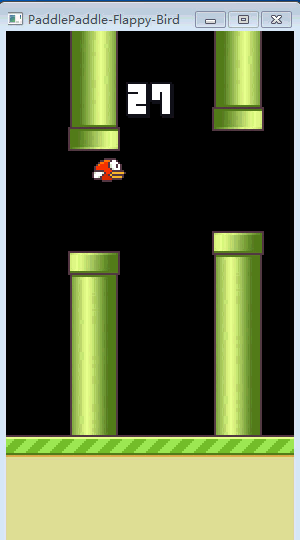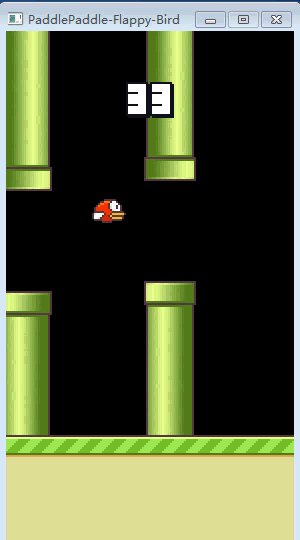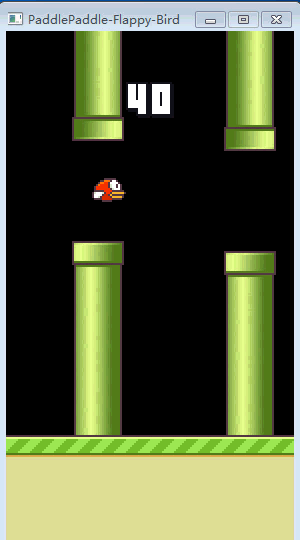
▲ 训练完的FlappyBird
观看 4 分钟完整版:
https://www.bilibili.com/video/av49282860/
Github源码:
https://github.com/kosoraYintai/PARL-Sample/tree/master/flappy_bird
参考文献
[1] Bellman, R.E. & Dreyfus, S.E. (1962). Applied dynamic programming. RAND Corporation.
[2] Sutton, R.S. (1988). Learning to predict by the methods of temporal difference.Machine Learning, 3, pp. 9–44.
[3] V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, et al., "Human-level control through deep reinforcement learning," Nature, vol. 518(7540), pp. 529-533, 2015.
[4] https://leetcode.com/problems/climbing-stairs/
[5] https://leetcode.com/problems/pascals-triangle-ii/
[6] https://github.com/yenchenlin/DeepLearningFlappyBird
[7] https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow

点击以下标题查看更多往期内容:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 访问PARL官网

