五年后的计算机视觉会是什么样?和CV先驱们一同畅想(上) | CVPR2019


AI 科技评论按:对于计算机视觉研究者们来说,以当前的技术水平为基础,寻找突破点做提升改进是科研的主旋律。这几年来,计算机视觉领域的已有问题在研究者们的努力下普遍得到了越来越好的解决,映入大家视野的新问题也越来越多。不过到了 CVPR 这个供全球计算机视觉研究者齐聚讨论的盛会上,一个可能不那么直接指导短期研究、不那么容易形成共识问题也就自然地涌上了大家的心头:在五到十年后的未来,计算机视觉的研究会是什么样子,是深度学习几乎完全替代了目前还在使用的其他一些方法,还是我们应该期待新的革命?CVPR 2019 上的首届「Computer Vision After 5 Years - CVPR Workshop」就正式地带大家一起讨论这个问题,不仅让已经有经验的研究者们交流观点,也为这个领域的年轻学者们拓展思路和视野。
Computer Vision After 5 Years Workshop 的三位组织者来自 UC 伯克利、FAIR 以及 UIUC,邀请到的演讲者包括 Ross Girshick、Jitendra Malik、Alexei Efros 等计算机视觉领域响当当的人物。研讨会在中午休息后开始;开始前五分钟,会议厅内就座无虚席。到了计划开始时间时,容量约 400 人的演讲厅的两侧走道、门内走廊就像 Facebook 何恺明、Ross 组组织的 Visual Recognition and Beyond 教学讲座一样挤满了人,这也说明了研究者们对整个领域大方向的关心。(虽然相比于本届 CVPR 超过 9000 的参会人员来说也算不上是多大的数字)
AI 科技评论把各位学者演讲的主要内容摘录如下。
演讲一
首位演讲者是 INRIA 法国国家信息于自动化所的研究主任 Cordelia Schmid。

Cordelia Schmid 是 IEEE Fellow,研究领域为图像和视频描述、对象和类别识别、机器学习,长期任 IEEE PAMI、IJCV 编辑,如今是 IJCV 主编,也是 CVPR2015 的大会主席。

Cordelia Schmid 的演讲题目是《5 年后对视觉世界的自动化理解》。

得益于机器学习研究的新进展和各种大规模数据集,今天的机器感知已经有了很多喜人的成果,对如何设计模型也有了新的思路。但当前的数据集其实存在一些问题,这会限制新任务中的表现。

数据方面,目前的人工标注数据存在许多问题,比如能覆盖的类别和实例数量都很有限,需要增加新的类别或者概念时难以重新标注或者升级标注,类别存在长尾现象,有一些信息是难以标注进去的(比如流、三维形体)。

针对人体动作识别任务,Cordelia Schmid 介绍了她对数据问题的解决方案 SURREAL Dataset,这是一个合成的三维人体动作数据集,有良好的可迁移性,也有许多不同级别的标注。

总体上来说,她认为未来的计算机视觉有这三个发展方向:数据集会同时有手工标注的、生成的和弱监督数据三类;更好的视频理解;以及多模态表征,与世界有更多互动。

对于视频学习话题,目前一大问题是视频数据集规模不理想,比如 UCF-101 和 J-HMDB 数据集的多样性、时长、分辨率都很有限。新型的数据集需要主角之外的更多动作,也更丰富多变。视频学习的目标包括判断时序依赖(时序关系)、动作预测。为此也需要新型的模型设计,她小组的一篇视频动作检测的论文就被 CVPR 2019 接收了。

在感知画面之外,计算机视觉研究还可以有更多补充,比如视觉系统可以与世界互动,和机器人、强化学习结合;音频和文字数据的加入也可以带来更好的视觉理解。

具体做法是多模态监督,最新的 Video-Bert 能学习视频和对话之间的对应关系;模仿学习结合强化学习、虚拟环境训练到真实环境训练迁移也是值得引入到计算机视觉领域的做法。

总结:Cordelia Schmid 对未来计算机视觉发展趋势的预测是,需要设计新的模型,它们需要能考虑到空间和时间信息;弱监督训练如果能做出好的结果,那么下一步就是自监督学习;需要高质量的人类检测和视频对象检测数据集,这非常重要;结合文本和声音的跨模态集成;在与世界的交互中学习。
演讲二

下一位讲者是 UC 伯克利电子工程与计算机系教授 Alexei Efros,他也是计算机视觉领域的先驱,尤其以最近邻方法而闻名。他的演讲风趣幽默,令人愉悦,也引发了现场许多听众的共鸣。

他首先展示了这样一张 PPT——计算机视觉的下一个五年计划。然后他很快解释这是开玩笑的,学术研究的事情怎么可能做得像苏联的五年计划一样呢。他紧接着讲了个关于学术课题的笑话,一个学生问他的导师「什么课题才是真正重要的」,导师回答他「当然是现在正在做的!」(也许是暗示没有一心投入哪个课题的人才能真正看得远)

所以他真正的演讲题目是:「没有遗憾的未来五年」。预测五年很难,但是可以做尽量不让自己后悔的事情。也是借机谈一谈自己学术经历中的一些感想。

遗憾是从哪里来的?Vladlen Koltun 有句话说「每篇论文都是障碍」,因为糟糕的论文可能会影响自己一生的学术名誉,可能会浪费了时间以至于做不了更有影响力的事情,甚至更糟糕地,可能会把整个领域引向错误的方向。而且也会长期带有这种负罪感。但是也不能只顾着安全,做学术研究就是需要冒一些险的。

Alexei Efros 说自己的学术生涯里有两大遗憾:图模型,就不应该尝试这个方向的,而且把很多别的研究人员也带到沟里了;而卷积网络,应该更早地研究、更早地使用。他讲了一则趣事,Yann LeCun 以前到伯克利做过演讲,介绍 CNN,LeCun 讲的时候仿佛完全没觉得有必要解释是怎么来的,就只是说了你需要这个、那个,把它们连起来,然后就好了。他还带了电脑,现场演示训练和预测(当时别的方法都没法这么快地完成)。这和当时做图模型的人的做法完全不一样,但也直到后来大家才接受了 CNN。

而所有遗憾的「元遗憾」,就是领域内的研究人员们花了太多时间精力研究算法。对特征的研究要少一些,对数据的研究更少,但实际上它们的效果是反过来的——数据带来的提升是最显著的。

他举了例子说明,如今面部识别早已不是问题,但当时,1998 年、1999 年都有人已经用简单的方法做出了优秀的结果,但让领域内公认「解决」了面部识别问题的算法,是看起来足够难的那个算法—— 2011 年的 Haar 特征加级联提升多厉害,更早的用像素特征、用朴素贝叶斯听起来就没难度,朴素贝叶斯(Naive Bayesian)这么天真、简单,怎么能说是突破性结果的代表呢。

另一个例子是他自己在 2008 年用最近邻算法做了图像的地理位置识别,巧的是谷歌也在 2016 年用深度学习研究了同一个问题。作为后来者的谷歌拿出了更多的数据,所以结果更好。
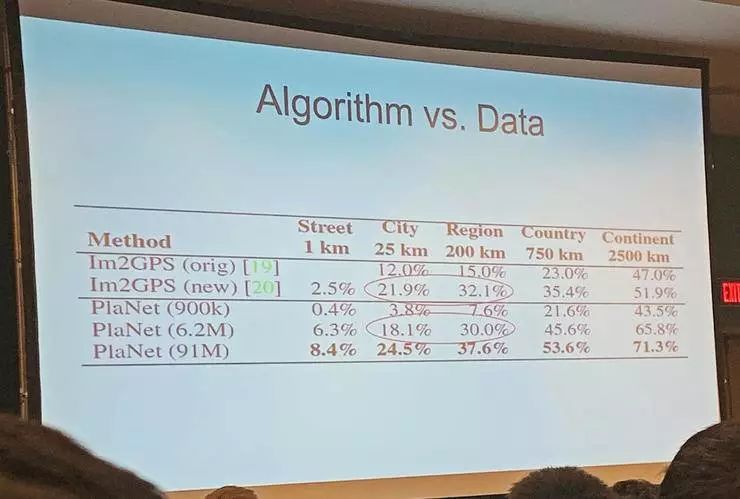
但有趣的是,在实验数据里,一样的数据量下,他们的老方法比谷歌的新方法效果还好。所以关键点还是在于数据,但大家都在急着提出并且标榜自己的算法。

所以说,做科研的人都有这么种自恋:相比之下,我们更愿意把成果归功于自己的聪明才智。

对于未来 5 年计算机视觉领域的发展趋势,Alexei Efros 接下来给出了自己的看法,更具体地说是对未来研究可能证明是障碍、可能会成为遗憾的东西的看法。不过他也说自己的观点是有争议性的,如果有人能证明他是错的也挺好的:

1,对抗性攻击和鲁棒性问题,他认为这不应该是个问题,没必要花那么多精力去想办法避免,实际上可能也永远都避免不了。因为对抗性样本本来就不是来自自然数据流形的数据,落在由自然数据流形所划分的决策边界上就是有可能的,所以这并不是一个数学问题,而是一个人类的感知问题。他的建议是只要我们让人类的视觉行为和计算机的类似就行了。换句话说,对抗性样本只是人类与计算机的感知特点不同的表现,而不是问题本身;如果想要治病,不要只吃止痛药(要研究感知特点,就不要紧盯着想要消灭对抗性样本);

2,他认为短期内视觉无法和语言结合,抽象程度相差太多。Alexei Efros 挖苦说,最近几十年的 CVPR 论文可能都会反复上演这样的戏码:每一年都会有论文带来新的视觉+语言数据集,然后第二年发现在这个数据集上只需要用最近邻算法或者随便一个什么基准线方法就能打败所有别的方法。他说这是因为我们现在有的方法真的太弱了,还不足以把这两种模态的信息有效地提取、融合起来。「我们还没达到一只老鼠的视觉能力,怎么就开始想着做直立人做的事情了」

3,我们对可解释性的要求太严苛,有些问题没有简单的低维描述,就是复杂的,就是需要足够多的数据才能解决。相比于理工科往往用简单明了的公式描述现象,心理学、基因、经济学等学科已经没办法简单地用公式表示了。所以在这种时候我们就是应当依靠大量数据,没必要一定要追求一个简单的解。

他还举了个例子,一团烟雾的行为可以用公式描述,但是一颗树的生长行为是由温度、光照、水、气候等等许多复杂的因素在很长时间内连续变化所影响的,那么它就是没办法简单地解释的。

4,重新思考数据集。虽然做实验、发论文的时候一定需要用数据集,但是我们心里要记得,数据集并不等于整个世界,它只是一个相当固定的、二维的侧写。所以模型出现的过拟合/作弊行为也就不应该被看作是问题,同样的样本甚至同样的数据集(多轮训练)反复看了很多次,当然会出现这样的结果。说到底,就不应该使用有限的标注和数据集。


结束语:如果说人生目标可以是增加未来可以怀念的东西的话,他自己的五年计划就是减少遗憾、增加可以未来怀念的东西,比如可以从别发表自己不满意的论文开始。
(限于文章篇幅,后续 Ross Girshick、Jitendra Malik 等几位讲者的演讲内容将在下篇中呈现,敬请期待)
AI 科技评论现场报道
2019 年 7 月 12 日至 14 日,由中国计算机学会(CCF)主办、雷锋网和香港中文大学(深圳)联合承办,深圳市人工智能与机器人研究院协办的 2019 全球人工智能与机器人峰会(简称 CCF-GAIR 2019)将于深圳正式启幕。
届时,诺贝尔奖得主JamesJ. Heckman、中外院士、世界顶会主席、知名Fellow,多位重磅嘉宾将亲自坐阵,一起探讨人工智能和机器人领域学、产、投等复杂的生存态势。






