GitHub 热门:各大网站的 Python 爬虫登录汇总
(给Python开发者加星标,提升Python技能)
编译:机器之心,作者:CriseLYJ
不论是自然语言处理还是计算机视觉,做机器学习算法总会存在数据不足的情况,而这个时候就需要我们用爬虫获取一些额外数据。这个项目介绍了如何用 Python 登录各大网站,并用简单的爬虫获取一些有用数据,目前该项目已经提供了知乎、B 站、和豆瓣等 18 个网站的登录方法。
项目地址:https://github.com/CriseLYJ/awesome-python-login-model
作者收集了一些网站的登陆方式和爬虫程序,有的通过 selenium 登录,有的则通过抓包直接模拟登录。作者希望该项目能帮助初学者学习各大网站的模拟登陆方式,并爬取一些需要的数据。
作者表示模拟登陆基本采用直接登录或者使用 selenium+webdriver 的方式,有的网站直接登录难度很大,比如 qq 空间和 bilibili 等,采用 selenium 登录相对轻松一些。虽然在登录的时候采用的是 selenium,但为了效率,我们也可以在登录后维护得到的 cookie。登录后,我们就能调用 requests 或者 scrapy 等工具进行数据采集,这样数据采集的速度可以得到保证。
目前已经完成的网站有:
Facebook
无需身份验证即可抓取 Twitter 前端 API
微博网页版
知乎
QQZone
CSDN
淘宝
Baidu
果壳
JingDong 模拟登录和自动申请京东试用
163mail
拉钩
Bilibili
豆瓣
Baidu2
猎聘网
微信网页版登录并获取好友列表
Github
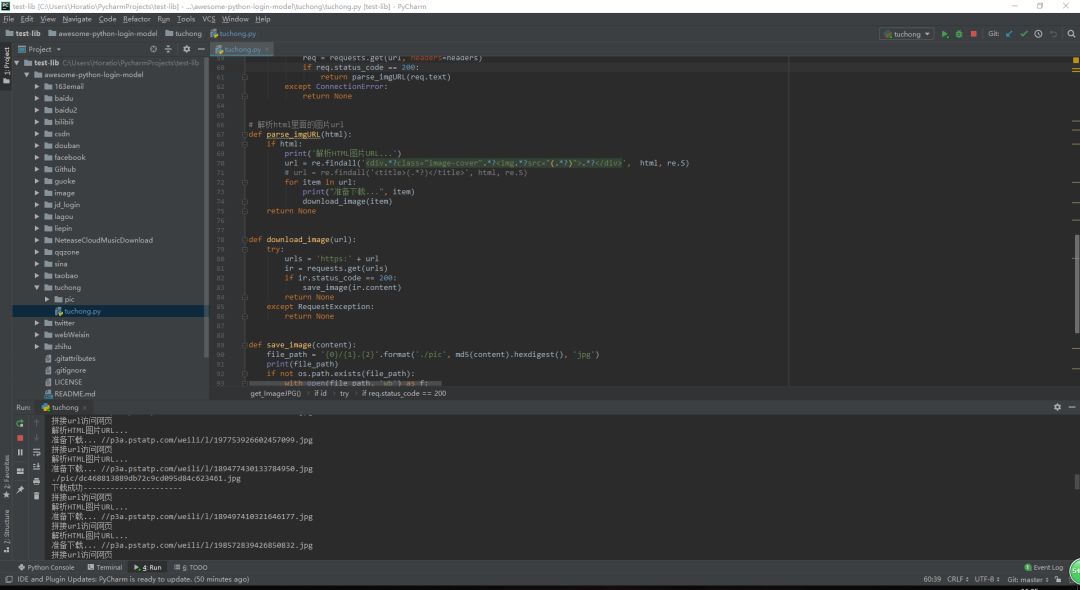
爬取图虫相应的图片
如下所示,如果我们满足依赖项,那么就可以直接运行代码,它会在图虫网站中下载搜索到的图像。
如下所示为搜索「秋天」,并完成下载的图像:

每一个网站都会有对应的登录代码,有的还有数据的爬取代码。以豆瓣为例,主要的登录函数如下所示,它会获取验证码、处理验证码、返回登录数据完成登录,并最后保留 cookies。
def login():
captcha, captcha_id = get_captcha()
# 增加表数据
datas['captcha-solution'] = captcha
datas['captcha-id'] = captcha_id
login_page = session.post(url, data=datas, headers=headers)
page = login_page.text
soup = BeautifulSoup(page, "html.parser")
result = soup.findAll('div', attrs={'class': 'title'})
#进入豆瓣登陆后页面,打印热门内容
for item in result:
print(item.find('a').get_text())
# 保存 cookies 到文件,
# 下次可以使用 cookie 直接登录,不需要输入账号和密码
session.cookies.save()
其中获取并解决验证码的函数如下:
def get_captcha():
'''
获取验证码及其ID
'''
r = requests.post(url, data=datas, headers=headers)
page = r.text
soup = BeautifulSoup(page, "html.parser")
# 利用bs4获得验证码图片地址
img_src = soup.find('img', {'id': 'captcha_image'}).get('src')
urlretrieve(img_src, 'captcha.jpg')
try:
im = Image.open('captcha.jpg')
im.show()
im.close()
except:
print('到本地目录打开captcha.jpg获取验证码')
finally:
captcha = input('please input the captcha:')
remove('captcha.jpg')
captcha_id = soup.find(
'input', {'type': 'hidden', 'name': 'captcha-id'}).get('value')
return captcha, captcha_id
当然这些都是简单的演示,在 GitHub 项目中可以找到更多的示例。此外,作者表明由于网站策略或者样式改变而导致代码失效,我们也可以提 Issue 或 Pull Requests。最后,该项目未来还会一直维护,很多东西哦也会慢慢改进,项目作者表明:
项目写了一段时间后,发现代码风格、程序易用性、可扩展性、代码的可读性,都存在一定的问题,所以接下来最重要的是重构代码,让大家可以更容易的做出一些自己的小功能;
如果读者觉得某个网站的登录很有代表性,可以在项目 issue 中提出;
网站的登录机制有可能经常的变动,所以当现在的模拟的登录的规则不能使用的时候,请项目在 issue 中提出。
推荐阅读
(点击标题可跳转阅读)
觉得本文对你有帮助?请分享给更多人
关注「Python开发者」加星标,提升Python技能

喜欢就点一下「好看」呗~





