CCIR 2018知识平台内容推荐评测优秀方案解析

更多优质内容请关注微信公众号“AI 前线”(ID:ai-front)
近年来,随着互联网产业的发展,时刻有海量的信息产生,也产生了信息过载等问题。如何在这些信息中帮助用户找到符合其需求的信息是个重要的课题,而个性化推荐系统被视为解决这个问题的一个重要途径。
为了更好地验证参赛团队的算法在真实环境下的表现,知乎还为此次评测提供了线上评测环境,优秀队伍生成的推荐结果会被投放到知乎信息流中观察用户交互表现。
给定一系列内容条目和用户,目标是将合适的内容推荐给相应的用户,希望被推荐用户对该内容感兴趣,反映在交互上表现为点击、收藏等行为。
竞赛共历时 3 个月,全程共计 324 支队伍参与竞赛,参赛团队在知乎数据基础上探索了众多的优秀个性化推荐算法方案,在 CCIR 2018 会议的评测环节中,共有 8 支团队因其在离线评测和在线评测中的优异表现,受邀对其方案进行了解读和呈现。
我们发现,基于深度学习的推荐算法在本次评测中大放异彩,其中,清华大学智能技术与系统国家重点实验室信息检索课题组 (THUIR) 提出的 ACCM(Attentional Content & Collaborate Model)网络和合肥工业大学多媒体与推荐系统实验室(HFUT-MARS)提出的 DeepFISM(Deep Factored Item Simularity Method)方法给人的印象尤为深刻。
在清华大学智能技术与系统国家重点实验室信息检索课题组提交的方案中使用的模型包括:
简单属性排序模型
Most Popular:根据 candidate 的历史正向交互次数做倒序排序
Most Diff:根据问题的历史正向交互次数与负向交互次数之差做倒序排序,再推荐每个问题下正向交互次数最多的 candidate
Most CTR:根据 candidate 的历史 CTR 值做倒序排序
搜索相关模型
User Topic Search:使用用户在训练集中交互的 topic,取最高频 10 个词,在回答标题中搜索,bm25 排序取前 1000,去除已经交互过的,然后使用 popular 排序取前 100User History Search:使用用户在训练集中的搜索历史,取最高频 10 个词,在回答标题中搜索,bm25 排序取前 100
Title Keywords Search:使用用户交互过的回答标题关键词搜索问题标题后按点赞排序
深度学习相关模型
LEM(latent embedding model):用 autoEncoder 对用户和回答的主题进行编码,拼接用户回答特征后,再连接 MLP 层生成最终结果
NCMF:参考 NUS 何向南老师之前的工作,用 NFM 做用户和回答的特征提取,再把提取后的特征应用到 NCF 模型的框架中。
其他 Baseline 模型
Topic Item Knn:取出现次数最多的用户和回答的 Top 200(400) topics 作为特征,计算 cosine sim 作为 item 的相似度。其他部分与普通 item knn 相同
Topic LightGBM:采用 user 和 item 的 topics 作为特征,按照交互历史,将 user 和 item 特征拼接作为特征,正交互为 1,负交互为 0,用 LightGBM 训练
鉴于 Deep Learning 的推荐模型目前已经在学术界和工业界得到了主流的应用,而清华大学智能技术与系统国家重点实验室信息检索课题组提出的 ACCM 网络,则在基于深度网络的推荐模型中引入了 Attention 机制,来决定 User 和 Item 的特征向量来源。由于用户的阅读行为序列往往非常多样化,利用 Attention 机制,ACCM 模型能够捕捉到与当前内容最相关的历史阅读行为,从而实现对推荐内容的精准评分。ACCM 模型的结构如下图所示:

同时,为了应对冷启动用户的推荐问题,参赛团队还在模型训练过程中引入了 Cold-Sampling 机制,通过随机隐藏一定比例的 user/item id 特征向量,让对冷启动用户的推荐得到充分的学习。据了解,THUIR 在在线实验阶段,尝试了多种模型,包括基于 RNN 的推荐方案等,其中 ACCM 方法在评测中得到了最好的推荐效果。ACCM 模型在不同冷启动场景下面的实验结果如下图所示:
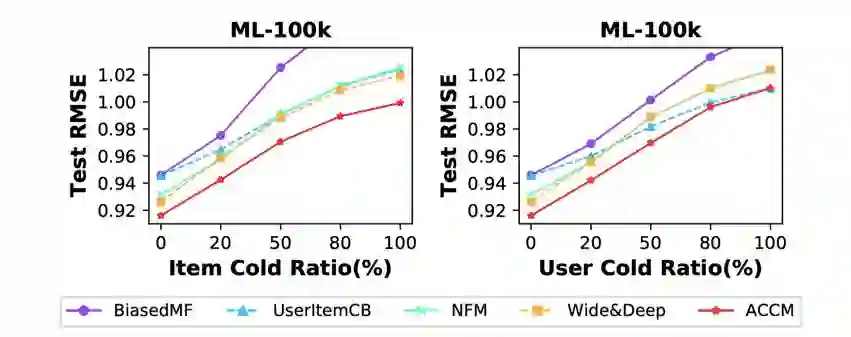
据 THUIR 的张敏教授介绍,基于该方法的论文已经通过 CIKM 2018 会议评审,届时也会在 CIKM 2018 会议上公布出来。
合肥工业大学多媒体与推荐系统实验室提出的 DeepFISM 方法将协同过滤与 Deep Learning 进行了有效的结合。FISM 方法是 2013 年由 Santosh Kabbur 等人提出的 Item Based 的协同过滤方法,用于从用户的浏览和评分历史中捕捉用户偏好,生成对用户的 top-N 推荐结果。
但鉴于这种方法简单地使用线性内积建模物品之间的低阶交互关系,限制了模型表达复杂交互的能力,而深度神经网络却可以挖掘这种高阶交互关系,因此参赛团队将深度神经网络与与 FISM 算法结合起来,提出了 DeepFISM 模型。
源于 DNNs 具有拟合任意连续函数的强大能力,合肥工业大学多媒体与推荐系统实验室使用标准的 MLP 结构来建模物品交互函数。具体而言,即在对 pi 和 q j 进行 concatenation 或者 element-wise product 之后堆叠若干层隐藏层,最终输出层的输出即为用户对物品的评分预测值。对于隐藏层神经元结点的激活函数,由于 ReLU 函数的非饱和特性并且能够有效地保证模型免于过拟合, 合肥工业大学多媒体与推荐系统实验室选择 ReLU 函数作为隐藏层中神经元结点的激活函数,最终保证我们的网络模型能够有效地学习出物品之间的非线性交互关系。
而对于 MLP 的结构,合肥工业大学多媒体与推荐系统实验室将其设计成标准的塔型结构,即后一层网络层的神经元结点个数是前一层神经元结点个数的一半。模型结构如下图所示:
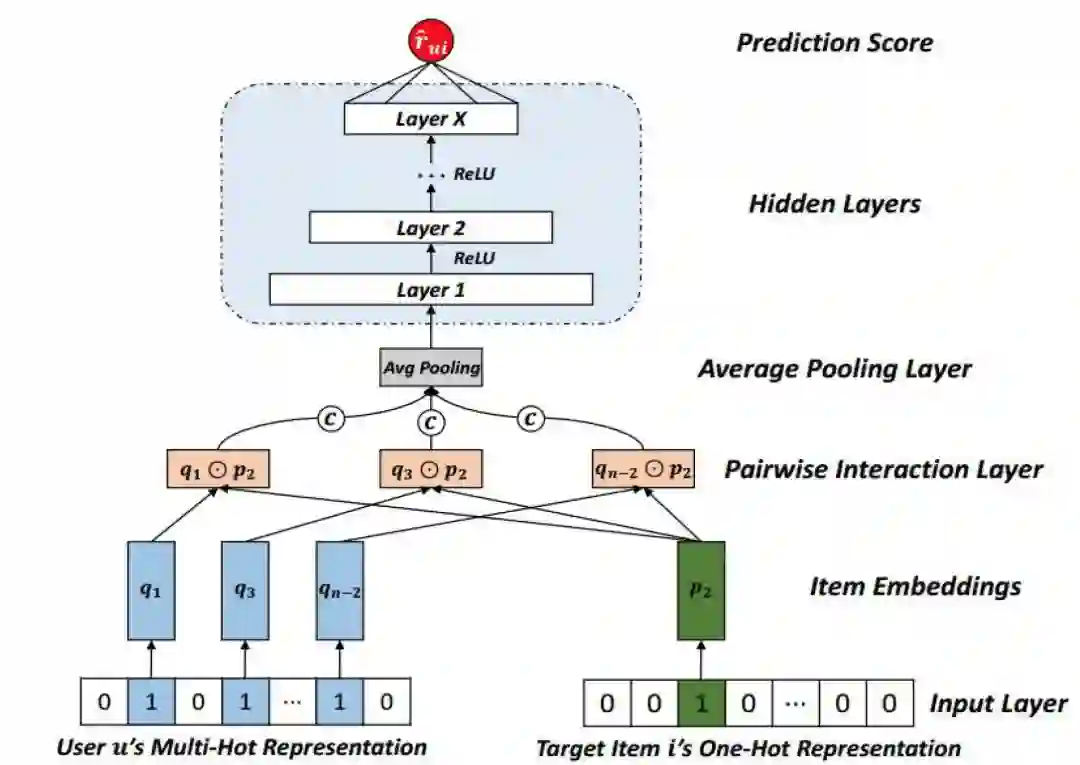
这一模型仅仅使用了物品之间的交互信息,并没有使用到竞赛数据中的文本信息,但在评测中还是取得了非常不错的成绩。此外,由于去除了文本信息,也使得模型训练和迭代的速度大大提升,据参赛团队介绍,在决赛阶段,他们会在每天的测试数据给出后,即时重新训练该模型,重新训练后的模型对比初始模型在比赛成绩上也会有正向的变化。
除了这两种模型外,其他参赛团队也都实验了种种不同的方法,例如基于嵌入式表达(Embedding Representation)的方法和基于梯度提升(LightGBM/Xgboost)的方法等。作为当前工业界主流的推荐算法,参赛团队还在这些算法基础上,根据评测任务场景做了不同程度的创新,充分体现了自己的技术创造力。这些评测报告也获得了 CCIR 2018 与会者的好评。
我们都知道,算法技术突破与演进离不开数据和场景的支持,最近几年,知乎在知识平台的算法应用上实现了不少突破,在推荐算法领域,知乎已经探索出一条独特的机制,其中首页算法推荐系统「水晶球」上线之后,在线时长及 CTR 均提升 50% 以上。
作为主办方和数据、评测提供方,也给互联网企业对在算法学术界与业界的交流做了一次很好的示范,希望这类数据开放与技术提升的平台和机会更多一些,能够真实反应和攻克算法领域内的现实问题。

如果你喜欢这篇文章,或希望看到更多类似优质报道,记得给我留言和点赞哦!