【学界】ICLR 2018 | 斯坦福大学论文通过对抗训练实现可保证的分布式鲁棒性
选自ICLR
作者:Aman Sinha, Hongseok Namkoong, John Duchi
来源:机器之心
参与:Jane W、黄小天、许迪
神经网络容易受到对抗样本的影响,研究者们提出了许多启发式的攻击和防御机制。本文主要从分布式鲁棒优化的角度出发,从而保证了对抗输入扰动下神经网络的性能。
试想经典的监督学习问题,我们最小化期望损失函数 EP0 [ℓ(θ;Z)](θ∈Θ),其中 Z〜P0 是空间 Z 上的分布,ℓ 是损失函数。在许多系统中,鲁棒性对于变化的数据生成分布 P0 是可取的,不管它们来自协变量变化、潜在定义域变化 [2],还是对抗攻击(adversarial attack)[22,28]。随着深度网络在现代以性能至上的系统中变得普遍(例如自动驾驶车的感知、肿瘤的自动检测),模型失败会日益导致危及生命的情况发生;在这些系统中,部署那些我们无法证实鲁棒性的模型是不负责任的。
然而,最近的研究表明,神经网络容易受到对抗样本的影响;看似不可察觉的数据扰动可能导致模型的错误,例如输出错误分类 [22,28,34,37]。随后,许多研究者提出了对抗攻击和防御机制 [44,38,39,40,48,13,31,23]。虽然这些工作为对抗训练提供了初步基础,但是不能保证所提出的白箱(white-box)攻击是否能找到最有对抗性的扰动,以及是否存在这些防御一定能够成功阻止的一类攻击。另一方面,使用 SMT 求解器对深度网络的验证提供了鲁棒性的正式保证 [26,27,24],但通常是 NP-hard;即使在小型网络上,这种方法也需要高昂的计算费用。
我们从分布式鲁棒优化的角度出发,提供一种对抗性训练过程,并在计算和统计性能上提供可证明的保证。我们假设数据生成分布 P0 附近的分布类别为 P,并考虑问题最小化 sup P∈P EP [ℓ(θ;Z)](θ∈Θ)。
P 的选择影响鲁棒性保证和可计算性;我们发现具有高效计算性松弛(relaxation)的鲁棒性集合 P,即使在损失 ℓ 是非凸的情况下也适用。我们提供了一个对抗训练过程,对于平滑的 ℓ,享有类似于非鲁棒方法的收敛性保证,即使对于最坏情况下的整体损失函数 supP∈P EP [ℓ(θ;Z)],也可以证明性能。在 Tensorflow 的一个简单实现中,我们的方法实现经验风险最小化(ERM, empirical risk minimization)所需时间是随机梯度方法的 5-10 倍,与其它对抗训练过程的运行时间相匹敌 [22,28,31]。我们表明,我们的方法通过学习防御训练集中的对抗性干扰来获得泛化能力,使我们训练出的模型能够防止对测试集的攻击。
我们简要概述我们的方法。令 c:Z×Z→R +∪{∞},其中 c(z,z0) 是攻击扰乱 z0 到 z 的成本函数(我们通常使用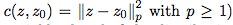
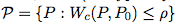
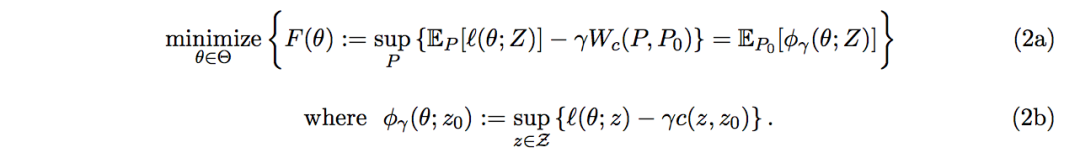
(关于这些等式的严格陈述,请参阅命题 1)。在这里,我们已经用鲁棒性的替代函数 φγ(θ;Z) 代替了通常的损失函数 ℓ(θ;Z)。这个替代函数(2b)允许数据 z 的对抗扰动,由惩罚 γ 调整。我们通常用经验分布 Pbn 代替惩罚问题(2)中的分布 P0 来解决问题,因为 P0 是未知的(我们在下面把这称为惩罚问题)。
惩罚问题(2)的关键特征是稳健水平的鲁棒性——特别是针对不可察觉的对抗扰动的防御——可以在基本上平滑损失函数 ℓ 没有计算/统计成本下实现。特别的是,对于足够大的惩罚 γ(在对偶、足够小的鲁棒 ρ 下),鲁棒替代函数(2b)z 7→ℓ(θ; z)−γc(z, z0) 是严格下凸(凹函数)的,因此优化更加容易(如果 ℓ(θ, z) 在 z 中是平滑)。因此,应用于问题(2)的随机梯度方法与非鲁棒方法(ERM)具有相似的收敛保证。在第 3 部分中,我们为任意 ρ 提供了鲁棒性保证;我们给出了在最坏情况下可以高效计算的基于数据的损失函数上限 supP:Wc(P,P0)≤ρ EP [ℓ(θ;Z)]。即,我们主要的对抗训练过程输出的最坏情况下的性能保证不比它差。当 ρ=ρbn 时,我们的约束是紧的,这对于经验目标而言是鲁棒的。这些结果表明,使用平滑激活函数的网络比使用 ReLU 的网络更具有优势。我们在第 4 部分通过实验验证了我们的结果,并且表明,即使对于非平滑的损失函数,我们也可以在各种对抗攻击情况下达到最先进网络的性能。
鲁棒优化和对抗训练对于某些不确定集合 U,标准的鲁棒优化方法可以将以形式为 supu∈U ℓ(θ; z+u) 的损失函数最小化 [3,42,51]。不幸的是,这种方法是棘手的,除了特殊结构的损失函数,如线性和简单的凸函数的组成 [3,51,52]。尽管如此,这种鲁棒方法构成了对抗训练近期取得进展的基础 [46,22,39,13,31],它启发式地提供了在随机优化过程中扰动数据的方法。
其中一种启发式算法使用局部线性化损失函数(以「快速梯度符号法」[22] 提出,p=∞):
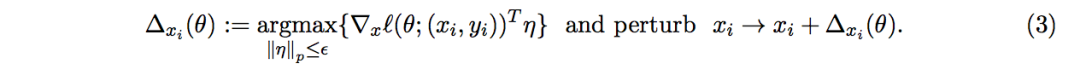
一种对抗训练方式基于这些扰动损失函数进行训练 [22,28],同时其它许多函数基于迭代的变量 [39,48,13,31]。Madry 等人 [31] 观察到这些过程试图优化目标 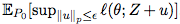
分布鲁棒优化为了说明当前的工作,我们回顾了一些关于鲁棒性和学习的重要工作。在鲁棒目标中选择 P(1)会影响我们希望考虑的不确定性集合的丰富性以及最终优化问题的易处理性。之前的分布鲁棒性方法已经考虑了 P 的有限维参数,例如矩的约束集、支持度(support)或方向偏差 [14,17,21],以及概率测量的非参数距离,如 f-散度 [4,5,32,29,18,35] 和 Wasserstein 距离 [8,19,45]。与 f-散度(例如χ2- 或 Kullback-Leibler 散度)相反(当分布 P0 的支持度是固定时有效),围绕 P0 的 Wasserstein 球包含一组分布 Q,它们具有不同支持度并且(在某种意义上)保证对未知数据的鲁棒性。
许多作者研究了易处理类型的不确定集合 P 和损失函数 ℓ。例如,Ben-Tal 等人 [4] 与 Namkoong 和 Duchi[36] 使用 f-散度球的凸优化方法。对于由 Wasserstein 球形成的最坏情况的 P 域,Esfahani 和 Kuhn[19]、Shafieezadeh-Abadeh 等人 [45] 与 Blanchet 等人 [8] 展示了如何将鞍点(saddle-point)问题(1)转换为正则化的 ERM 问题,但这只适用于有限类凸损失函数 ℓ 和成本函数 c。在这项工作中,我们处理更大的一类损失函数和成本函数,并为拉格朗日松弛鞍点问题提供直接解决方法(1)。

算法 1 分布鲁棒优化的对抗训练
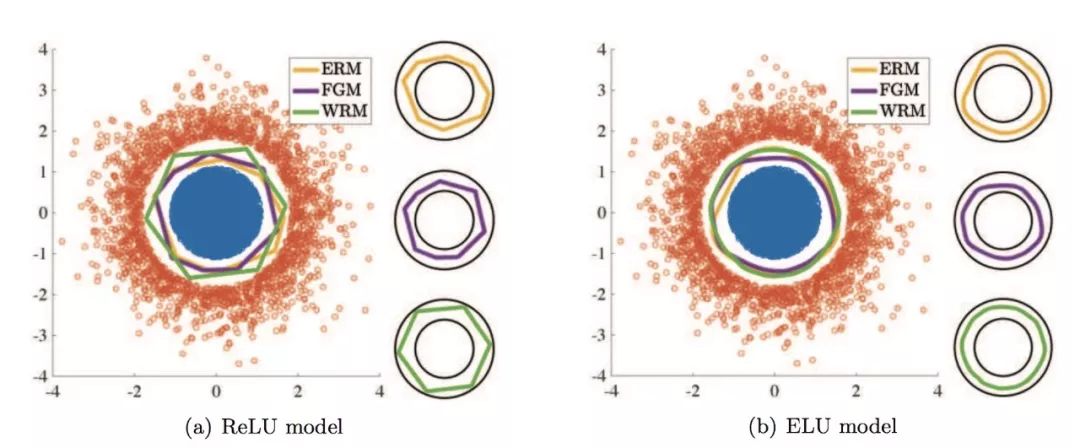
图 1. 合成数据的实验结果。训练数据用蓝色和红色表示。ERM、FGM 和 WRM 的分类边界分别以黄色、紫色和绿色表示。左边为边界与训练数据一起的图示,右边为分开的真实类边界的图示。
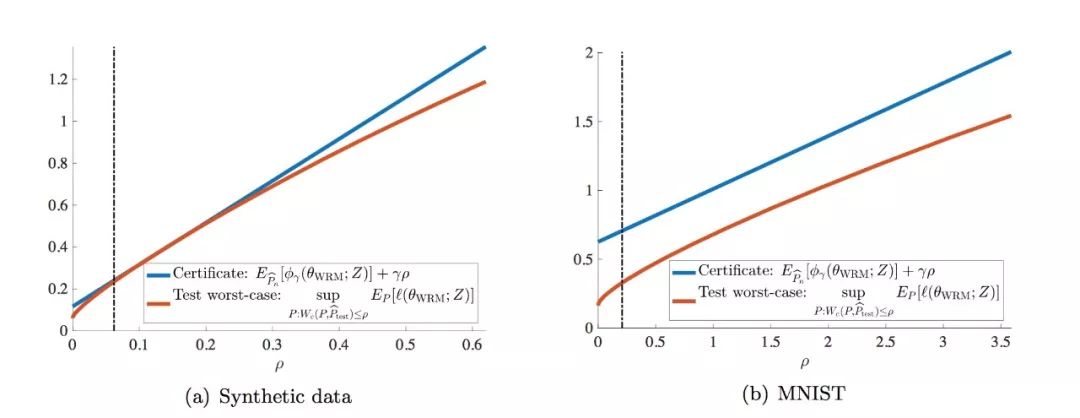
图 2. 用合成数据(a)和 MNIST(b)进行实验的鲁棒性保证(11)(蓝色)和样本外(out-of-sample/测试)最差情况下的性能(红色)之间的经验性比较。在(11)中省略了统计误差项 ǫn(t)。垂直虚线表示在训练集 ρbn(θWRM)上达到的鲁棒性水平。
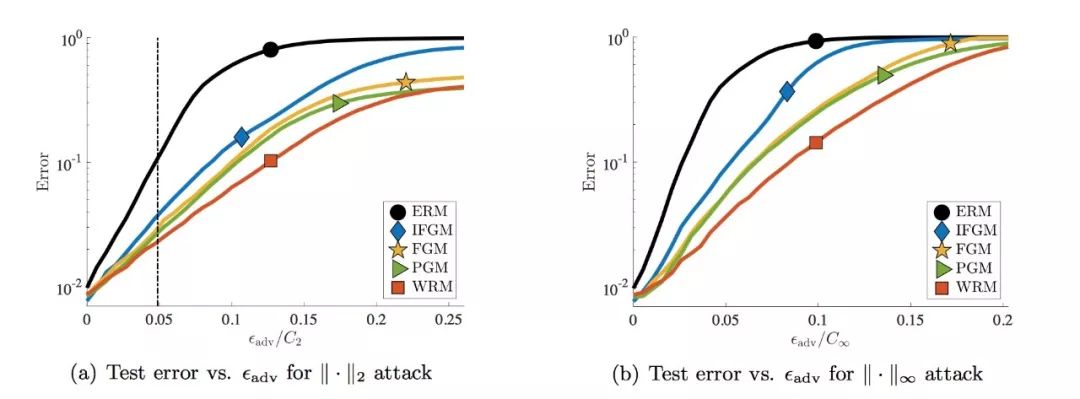
图 3. 对 MNIST 数据集的 PGM 攻击。(a)和(b)分别显示了对于 PGM 攻击在欧氏距离和∞范数下的测试错误分类错误与对抗扰动水平 ǫadv。(a)中的垂直虚线表示用于训练 PGM、FGM 和 IFGM 模型的扰动水平以及估计的半径 pρbn(θWRM)。对于 MNIST,C2=9.21 和 C∞=1.00。
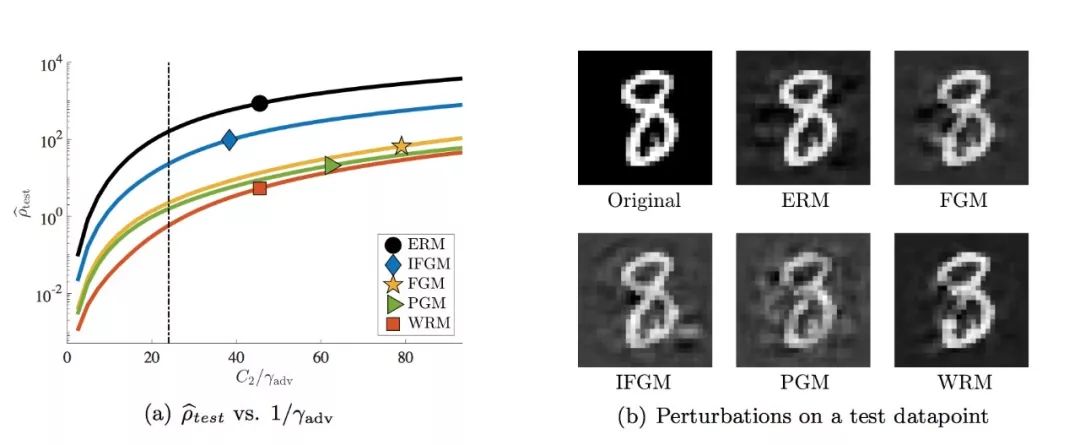
图 4. 损失函数表面的稳定性。在(a)中,我们显示了给定 γadv 的扰动分布 ρbtest 的平均距离,这是对于决策表面的输入的局部稳定性指标。(a)中的垂直虚线表示我们用于训练 WRM 的 γ。在(b)中,我们将最小的 WRM 扰动(最大 γadv)可视化,以使模型对数据点进行错误分类。更多的例子见附录 A.2。
表 1. 1000 次实验后的 Episode 长度(平均数 ± 标准差)
图 5. 训练中的 Episode 长度。纵坐标 Episode 长度的环境上限为 400 步长。
论文:Certifiable Distributional Robustness with Principled Adversarial Training

论文链接:https://arxiv.org/abs/1710.10571
摘要:神经网络容易受到对抗样本的影响,研究者们提出了许多启发式的攻击和防御机制。我们主要从分布式鲁棒优化的角度出发,它保证了对抗输入扰动下的性能。通过对在 Wasserstein 球中的潜在数据分布采用拉格朗日惩罚形式的扰动,我们提供了一种用最坏情况下的训练数据扰动来增加模型参数更新的训练过程。对于平滑损失函数,相对于经验风险最小化,我们的过程证明地实现了稳健水平的鲁棒性,并伴有很小的计算/统计成本。此外,我们的统计保证使我们能够有效证明整体损失函数的鲁棒性。对于不可察觉的扰动,我们的方法达到或优于启发式方法的性能。

☞【学界】OpenPV:中科院研究人员建立开源的平行视觉研究平台
☞【征稿通知】IEEE IV 2018“智能车辆中的平行视觉”研讨会
☞【学界】ParallelEye:面向交通视觉研究构建的大规模虚拟图像集
☞【CFP】Virtual Images for Visual Artificial Intelligence
☞【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞【观点】孙剑:计算机视觉存六大困难,很多问题很难用函数逼近解决
☞【学界】周志华组最新论文提出“溯因学习”,受玛雅文字启发的神经逻辑机
☞【让高中生掌握深度学习】掀起DL炼金术之争的Ali,这次要像教物理那样教深度学习


