NLP未来,路在何方?12位巨佬联名指路!
文 | Sheryc_王苏
美 | xxr
源 | 夕小瑶的卖萌屋
CMU、华盛顿大学、南加州大学、MIT、MILA、密歇根大学、爱丁堡大学、DeepMind、伯克利、Apple…如果我说来自这些地方的dalao共同发表了一篇文章,你相信么?但别惊讶,在即将召开的EMNLP'20的长文列表里,我们就真找到了这样一篇“奇文”。一篇论文引得众星云集,那解决的必然不是小问题。这不,作者也很贴心地把他们所希望解决的问题斜体独行地放在了论文的首栏里——
Where is NLP going?
……
在未来的这几分钟里,让我们暂时放下自己正在改的模型、正在写的论文和正在追的SOTA,重拾自然语言处理的初心,跟随大佬们的脚步,去畅想一下未来的NLP究竟是什么样的吧。
论文题目:
《Experience Grounds Language》
论文链接:
https://arxiv.org/abs/2004.10151
NLP,到底该怎么搞?
这是每一个NLP人都希望探索的终极问题。在经历了21世纪初的神经语言模型、2013年word2vec算法、2018年的预训练模型等等的里程碑过后,当今的NLP已经在许多任务上取得了令人欣喜的效果。但是,在欣喜于一个个子任务的突破之后,我们也该停下来思考我们每个人在初识NLP时的那个问题:如何才能让机器真正地理解人类语言呢?
本文提出了未来NLP的发展方向:只靠文本,是学不会语言的;学会语言,需要的是“语言之外的事件”和“社会环境”。这样虚无缥缈的两个词,隐含的却是未来NLP所需要添加的潜在的新组件。
为了更加具象,作者引入了“世界范围”的概念,英文名称World Scope,简称WS(不觉得和作者王苏有点关系么(逃))
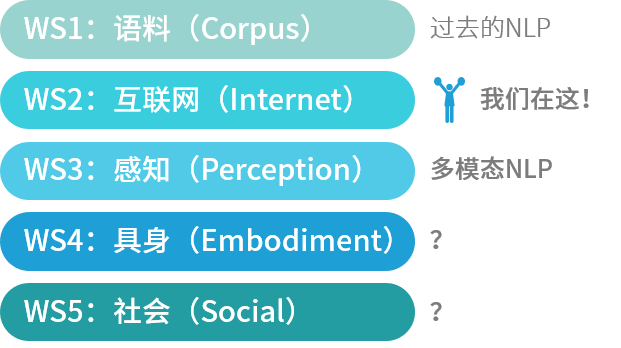
那么这五个世界分别表示什么,又象征着NLP的发展到了哪个阶段呢?现在,让我们把NLP系统想象成自家孩子,看看咱家宝贝儿是怎么一步步从过去只会总结文本模式到未来能够能动地改变世界的吧~(为了方便,我们就叫她N宝)
WS1:少量语料的世界——当系统学会表示

N宝终于拿到了她能接触到的第一个语料!此时的她,看的多半是类似于Penn Treebank的经典数据集,而她既没有容量很大的大脑(指模型),又接触不到其他东西(指感知和大量语料),于是研究者费尽心机地思考如何让她用少量文本也能学到些什么。这时的发展,正是集中在文本表示上。
所谓的“含义”(meaning)到底在哪里呢?一个很直观的想法是认为含义隐藏在文本的语法结构中,于是早期的NLP方法大都采用了诸如语法的分析结构。
但慢慢地,人们发现,文本的含义还有另外的表示方法。20世纪末-21世纪初,Elman和Bengio等人证明了向量表示可以捕获语法和语义信息;21世纪初,利用基于互信息的层次聚类表示方法和隐马尔科夫链生成词类别的方法证明了一个词的上下文隐含了这个词的含义;同样是21世纪初,以隐狄利克雷分布模型LDA为代表的主题生成模型证明了获取含义需要大量的上下文信息。正是基于以上的观察,才有了近年来诸如word2vec和GloVe的词向量表示,以及ELMo、GPT和BERT等等的上下文预训练表示。
然而,关于文本表示,有一个一直以来的矛盾,伴随着符号主义和连接主义的争论走到了今天——把词表示为符号,我们就可以利用一个词的字典释义,从而用其他词表示它,这种“以词释词”的方法服从直觉,解释性一流;然而,把词表示为向量,我们就能够利用诸如神经网络的“连接主义”系统进行处理,这种“以数释词”的方法难以解释,但架不住它好用。
这样的符号主义/连接主义争论经常会在当今的各大人工智能论坛见到,而在连接主义大行其道的当下,能在顶会论文见到这样的争论实在难得啊(=・ω・=)
WS2:文本的世界——当系统学会阅读

不是N宝不愿意上网,是多年前她的小脑瓜实在是处理不了网络上这么多纷繁复杂的信息。然而,多亏了专做N宝大脑的黄老板(黄仁勋:?)和革新了N宝大脑的Transformer结构(谷歌:?),有了增强算力和模型加持的N宝终于开眼看到了更广阔的的世界——非结构的,多语言的,跨领域的,无标签的,单拿出哪个都很让人兴奋吧,但BERT全都要!
以BERT为代表的基于Transformer的预训练语言模型在众多下游任务上的优异表现,在寥寥两三年时间里把NLP领域的排行榜屠了个遍。在我们为新诞生的预训练模型欢呼雀跃时,内心也难免会为它们越来越庞大的体积和“饭量”感到触目惊心。
从训练语料来说,2013年的word2vec使用了16亿个token,一年后的GloVe使用了8400亿个token,而BERT直接吃下了整个维基百科+一万多本书。从模型参数上来说,从2018年ELMo的 到GPT-3的 也不过只用了两年时间。
更重要的是,这类预训练模型的效果存在明显的边际效益递减:对于16年提出的词预测任务LAMBADA[1],从15亿参数的GPT-2,到170亿参数的TuringNLG,提升甚微;到了1750亿参数的GPT-3终于有了8个点的提升,但背后的多出来的算力开销,它值吗?
更重要的是,这类预训练模型很难解决许多更难的NLP任务、例如较难的共指解析(“我把车停在了那个小停车场,因为它足够[小/大]了。”)。之所以称之为“较难的”,是因为它们是经过精心选择的处于数据分布尾端的共指关系。如果N宝没停过车,她怎么会知道这个问题的答案不是从前半句里简单地提取出那个“小”字呢?解决这个问题的关键,在于经验。论文标题中的“Experience”,为未来可能的发展指明了方向。
这时,我们终于意识到,再怎么非结构多语言跨领域无标签的文本,也终究是文本;再往预训练语言模型砸嘛尼,也不一定能换来真正智能的N宝。N宝不缺文本了,她只是需要更系统地感知这个世界而已。
WS3:视觉与声觉的世界——当系统学会感知

N宝不再只是一头扎进书海里的书呆子了,她终于拥有了能看到世界的眼睛、听到世界的耳朵和触摸世界的双手,尽管眼睛耳朵和手也都是机器学习模型。但是,如果不看不听不碰的话,她怎么能理解“动如脱兔”、“噤若寒蝉”的真意,怎么体会到打工人钢铁般的意志(不)
这多出来的感知究竟是什么?是人类在进行决策时的多重依据,也是人们在认识世界时达成的共识,同时也是语言学证明的人类在学习语言时必需的外部输入。海伦·凯勒学习语言的故事脍炙人口,缺失视觉的辅助尚且如此,剥夺所有感官后,学到的语言还会是一样的吗?
文章引用了一种表示人类知识的方法:Frames and Scripts[2]。这种方法在上个世纪80年代被用来表示人类知识。通俗来讲,这一方法将人类世界的静态组成和动态动作流程利用类似于面向对象编程的方式进行建模:Frames利用类图构建事物之间的关联关系,而Scripts利用流程图构建一系列动作的发生过程。但即使成功表示了类别之间的关联关系,类别中的各个属性、流程图中的各个行为和条件依然没有和现实产生对应。大框架有了,细节却面临了同样的问题,因此,这种建模依然很片面。这恰恰说明了多模态对于理解知识的重要性。
既然是多模态,那自然要提及其中涉及的每个领域向多模态发展的努力。这其中,计算机视觉(CV)和自然语言处理(NLP)的结合自然是发展最多的一个。
计算机视觉领域已经提前意识到了与自然语言处理交互的重要性,并提出了一系列可以复用的模型,而计算机视觉领域也在近几年来开始解决视觉问答VQA、视觉推理和视频翻译等等CV+NLP的交互任务。这些多模态任务的标准数据集可以支持大规模视觉+文本、甚至视觉+文本+语音Transformer模型的训练。
NLP领域的发展同样支撑了多模态的应用,由于CV领域广泛采用的ImageNet[3]分类采用了WordNet[4]描述上下位词关系的层次分类,在加入了WordNet中每个概念的图像信息后,我们甚至可以在概念的向量表示中学习到仅利用文本无法获得的特征。比如,WordNet中“人”是一系列不同职业的上位词,其中包括“消防员”,“医生”等等;单纯凭借文本难以捕捉这些类别的区别;但在加入了“人”、“消防员”、“医生”的图片进行多模态学习后,我们可以利用像素级的掩码精确地获得不同类别的具体差异,甚至可以将自然语言描述拓展到从未见过的类别中,学习到新类别的特征…
这正是零次学习(Zero-shot learning)的想法,利用一段对未知类别的描述,让模型理解在训练过程中没有见过的类别的特征。对于文本的单一模态学习,用文本描述文本是WS1的想法;而多模态学习通过添加额外的感知方法,让零次学习的效果得到了大幅提升。那么问题来了,多模态之后,N宝又要做些什么呢?
WS4:行为的世界——当系统学会试错

N宝对世界观察了许久,她能读能看能听,我们感觉她好像理解了这个世界。但实际上,她对这个世界似懂非懂。
在她眼中,词语不过是一串数字或是像素组成的特征而已,每个名词概念到底隐含着什么内在属性,每个动作到底会带来什么影响,每个形容词到底描述了些什么特点,N宝都不懂。被动的学习已经满足不了她了,她想用她的感知去主动地理解语言背后的含义。当N宝有了行动的能力,她就有了具身,有了和外界互动的条件。
试想一下,对于“橘子更像是棒球还是香蕉?”这样的问题,你会作何回答?
WS1系统会认为橘子和香蕉经常出现在类似的上下文里,所以橘子和香蕉更像;WS2系统会认为橘子和棒球都是圆形的,但说不上来棒球和橘子的质地和大小;WS3系统会了解到橘子、棒球和香蕉的外表,所以同样会认为橘子和棒球更像,却说不清楚棒球、橘子和香蕉的软硬程度的重量。只有当系统能够接触到这些物体并产生互动时,它才会更加系统地回答,橘子和棒球具有相似的材质和重量,但橘子和香蕉具有相同的软硬程度和用途。
实际上,人类在学习知识时在不断地与外界产生互动并获得反馈,而这些持续的反馈构成了我们学习这个世界时的监督信号。这些信号甚至产生于我们学习语言之前,那么问题来了,这些婴儿时期产生的反馈究竟形成了什么呢?
对于人来说,这些反馈形成了我们的直觉和常识,而这些内容正是我们在日常交流时不会使用语言直接表述的隐含内容。对于机器来说,这些试错过程中得到的反馈形成的可能是“先于语言”的表示(pre-linguistic representations),它们可以被用来作为NLP系统泛化的基础。在语言学上已经证明,孩子从书本上学的东西很难被她们直接搬到现实生活中加以利用。我们利用大量的参数,希望用统计学的方法另辟蹊径地实现生物进化的成果,但缺少了与真实世界的交互,或许我们离这个目标确实遥远。
在WS4的世界,我们就需要借助机器人学领域的研究成果了。尽管从现在看,利用机器人学的成果远比利用CV的成果困难,但为了实现真正理解语言的目标,NLP的研究者应该同样关注机器人学的发展。随着动作空间的加大,NLP系统就能够学会更多的指令,让智能家居和智能机器人不再是现在这样仅靠指令集操作的机器,而是成为真正能应用在任何场景下真正的智能系统。
WS5:社会的世界——当系统学会能动
能动和能动并不是一个意思——WS4的能动是“会动”,而WS5的能动是“主观能动性”的能动。N宝的成长目标是要造福社会的,而人类社会的可是很复杂的。她要在与人打交道的过程中体现出她行为的目的性,让她真正能够实现人工智能系统的使命。到这个阶段,N宝就已经成为一个持久存在的,具有特定社会属性和经验的智能代理了。
NLP系统一直以来都是人工智能领域里最受关注的领域之一,毕竟图灵测试就是以对话系统为基础的测试。但是,在进行图灵测试时,人经常会受到框架效应(Frame effect)的影响:当聊天机器人表明自己以英语作为第二语言或是表现出弱势时,人自然会大幅降低对对方的期望,让原本真实性不高的回应也看起来像是真人一样。
那么,为什么说WS5对于语言学习至关重要呢?
首先,从说话者的角度,语言要产生作用。
从哲学上讲,语言的功能(Function)是含义的来源;从语言学上讲,基于使用的语言学习理论表明,有用的语言构建是一切的基础。这些理论在近年来开始关注语言在人类的起源和发展过程中起到的作用,表明了语言对于社会生活的重要性。
WS1-4逐步地扩展了语言含义的组成,逐渐地,语言可以由结果转变为起因,从单纯的数据转变为有用的信息。当下,NLP系统生成的语句只能以一种与社会隔离开的方式被被动的评价,而要做到衡量NLP系统对社会的影响,必须主动地让NLP系统参与到诸如谈判,合作,情感支持等等语言活动中来,让NLP系统能够推断人的情感状态和行为的社会效益。
当下的语言模型利用上下文构建每个词的释义。但实际上,一个词的含义需要被放在特定的语言和社会环境下进行综合考量。正比如,“大失所望”的词典意思是不令人满意,可是,只有在孩子学习语言时说出过或是听见过那句“你让我大失所望”时,她才能真正懂得这个词对人来说多么有分量。一个词的含义远不止词本身的意思:它最丰富的表达蕴含在了它对外界产生的影响之中。
其次,从聆听者的角度而言,语言要成为了解对方想法的工具。
“想法”并不局限于一句话本身的意思,而更多地指对方的需求,意图,感情,知识和身份。对“想法”的研究被称为“心智理论”(Theory of Mind)。这一理论被建模为讲者-听者模型(Speaker-listener model),从计算角度而言,又被进一步发展为“理性言语行为模型”[5](Rational speech act model, RSA,一种基于贝叶斯推断的有效沟通建模)。
对交流的理解只用静态的数据集是远远不够的。对于同一个样本的标注,不同的标注者可能提供不同的标注方法,这就会引入伪关系和偏差。动态且灵活的评价可能会解决这个问题,但如何保持一个NLP系统的身份,如何面对外界可能带来的变化依旧需要进一步研究。
那么,怎样让NLP系统拥有能够在社会环境下理解语言的能力呢?
首先,如果单纯利用一个诸如神经网络的通用的函数拟合器来给文本做分类,它可能单纯利用了文本中的语法语义信息,却永远不会认为文本中出现的人、事物和因果关系是真实存在的。这需要我们向模型中引入足够的归纳偏置(Inductive bias)来解决这一问题。其次,基于交叉熵的损失函数使得NLP系统不够关注数据分布的尾端,导致出现较少的事件被忽视了。最后,由于现有的系统依然无法达成像人类一样的归纳能力,NLP系统的零次学习能力依然有待提高。因此,WS1-4的数据无论再大,以目前的系统设计也难以让NLP系统学到足够丰富的知识来降低模型的困惑度。
最后,从社会环境的角度而言,语言是用在人际交流中的,所以语言本身就携带着地位、身份、意图和其他一系列的变量,但我们当下所使用的基于众包的数据标签并没有考虑这一系列对社会生活至关重要的信息。所以,对于生成模型而言,为了考量模型与社会之间的交互性,需要给予模型一个社会地位及身份,将其置身于特定场景中来进行评价。
但是,社会交流中存在那么多变量,该怎么进行标注呢?我们需要跳出这个圈子:训练-验证-测试集的划分以及基于对比的评价方式限制了我们的想象力。我们的终极目标,是让NLP系统通过参与到社会当中进行学习,让用户与系统自由交流,使得系统在探索与试错中逐渐达成对其身份的社会语言学构建。当模型能够在测试过程中能够与人进行交互,我们便可以窥视到模型的决策边界,加深对模型的了解了。
那么,要怎么进入下一个WS中呢?
好问题~实际上,现在已经有很多研究在探索WS3-5的需求了。作者在文章中给出了4个这样的研究方向:
-
第二语言习得(Second language acquisition):不同的国家虽然语言不同,却有着类似的社会模型,其中包括类似的物体指代(例如动物,水果…)和人的内在状态(例如快乐,饥饿…)。现有的研究已经开始向神经机器翻译模型引入这种相似性了:ACL'20的一篇论文[6]利用了WS3的图像信息作为增强双语对应关系的枢纽,未来会发展为利用WS4的模拟世界信息,以及最终走向WS5的真实世界信息。 -
指代消解(Coreference resolution)和 词义消歧(Word sense disambiguation):无论是确定文本中代词对应的名词还是探究一个词在文本中的确切意思,都最终需要对心智理论的探索,通过对听者需求和经验的建模综合地完成任务,而非简单地通过文本寻找到与代词最接近的名词,或是用局部的文本信息确定词义。类似TextWorld[7]的WS4虚拟环境为进一步探索这两个问题提供了新的可能。 -
新词学习(Novel word learning):人对于物体的描述可能不仅局限于语言,有时还会加入肢体语言配合形容物体的形状或大小,这需要WS3系统进行多模态的感知;此外,在描述新的物体时,我们不仅会描述它的外观,还会描述它的功能,这需要WS4系统对动作和功能的认识。例如,在描述手风琴时,我们会说它“背着像吉他,但弹着像钢琴”。手风琴与吉他和钢琴的相似性仅体现在使用动作上,这种动作上的描述只有更高级的系统才能够认识。 -
冒犯性语言(Personally charged language):每个人都有自己不愿意听到的话。比如,“笨蛋”这个词对于不同的人有着不同的理解:有些人可能认为这样的说法是开玩笑,无伤大雅;但有些人会认为这是对自己努力的否定,从而受到伤害。只有当系统走向WS5,获得了社会交往的知识,才能明白在不同环境和条件下人的情感究竟如何。
看了这么多,这篇文章究竟想说什么?
作者王苏在阅读这篇几乎不包含任何数据和公式的文章时,体会到的吃力感完全不亚于任何一篇充斥着公式的文章。许多哲学和语言学概念在近年来很少被提及,甚至一部分概念根本查不到相关的中文翻译,只好结合维基百科和一些查得到的讲义来努力理解。这也难怪,毕竟这篇文章是众多领域大佬从NLP、CV、语言学、哲学和机器人学等等不同的角度为NLP的未来规划的前行路线。
然而,文中所说的许多东西虽然目前已经有工作开始了相关的探索。虽然诸如“具身”、“社会属性”等等名词看起来和现在的NLP社区不怎么沾边儿,而且这些名词实在是过于虚无缥缈,这也恰好给予了研究者充分的想象空间,让每一个目标得以用不同的方法实现。例如,WS4的“试错”概念和强化学习有着千丝万缕的联系,而WS5的社会属性又不由得让我们想起了微软亚研院致力于提升智商+情商的微软小冰[8](小冰的论文对于研究对话系统的同学非常值得一读,大推荐)。
所以,在为越来越大的模型和计算开销发愁之余,换个角度来看看我们所在的领域,以大局观看看我们的发展阶段,思考思考踏入未来需要学习和发展什么样的技术,也许就能实现弯道超车呢~
要跟紧潮流鸭!加油吧,NLP人(= · ω ·=)
[1]The LAMBADA Dataset: Word Prediction Requiring a Broad Discourse Context. https://arxiv.org/abs/1606.06031
[2]一个关于Frames and Scripts的讲义:https://www.cs.bham.ac.uk/research/projects/poplog/computers-and-thought/chap3/node9.html
[3]ImageNet. http://www.image-net.org/
[4]WordNet: A Lexical Database for English. https://wordnet.princeton.edu/
[5]一本关于RSA的教材的第一章,其中包含了对RSA的解释:https://www.problang.org/chapters/01-introduction.html
[6]Unsupervised Multimodal Neural Machine Translation with Pseudo Visual Pivoting. https://arxiv.org/abs/2005.03119
[7]微软的机器闯关游戏TextWorld: https://www.microsoft.com/en-us/research/project/textworld/
[8]The Design and Implementation of XiaoIce, an Empathetic Social Chatbot. https://arxiv.org/abs/1812.08989
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套! ![]()
![]()
![]()
后台回复【五件套】
下载二:南大模式识别PPT ![]()
后台回复【南大模式识别】
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心
。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。
记得备注呦
推荐两个专辑给大家: 专辑 | 李宏毅人类语言处理2020笔记 专辑 | NLP论文解读 专辑 | 情感分析
整理不易,还望给个在看!













