响应速度不给力?解锁正确缓存姿势

阿里妹导读:响应时间长,遇到性能瓶颈时,开发者第一个想到的总是性能优化。《什么技能产品经理不会提,但技术人必须懂?》讲到了什么时候需要使用缓存。但缓存的用法是什么?一旦缓存使用不当,或稍有不注意,反而会翻车,导致系统投入更多的维护成本,陡增更高的复杂度。今天,科怀就来讲讲缓存的正确使用姿势。
Least-Recently-Used(LRU)
Least-Frequently-Used(LFU)
SIZE
First in First Out(FIFO)
方案一:采用bloom filter保存缓存过的key,在访问请求到来时可以过滤掉不存在的key,防止这些请求到db层;
方案二:如果db查询不到数据,保存空对象到缓存层,设置较短的失效时间;
方案三:针对业务场景对请求的参数进行有效性校验,防止非法请求击垮db。
方案一:使用互斥锁,当缓存数据失效时,保证一个请求能够访问到数据库,并更新缓存,其他线程等待并重试;
方案二:缓存数据“永远不过期”,如果缓存数据不设置失效时间的话,就不会存在热点key过期造成了大量请求到数据库。但是,缓存数据就变成“静态数据”,因此当缓存数据快要过期时,采用异步线程的方式提前进行更新缓存数据。
方案一:使用互斥锁的方式,保证只有单个线程进行请求能够达到db;
方案二:多每个key的失效时间在基础时间上再加上一个1~5分钟的随机值,这样就能保证大规模key集体失效的概率,并且需要尽量让多个key的失效时间能够均匀分布;


-
失效:应用程序先从cache取数据,没有得到,则从数据库中取数据,成功后,放到缓存中。 -
命中:应用程序从cache中取数据,取到后返回。 -
更新:先把数据存到数据库中,成功后,再让缓存失效。



在确定数据更新后缓存会失效来进行处理的话,针对数据库以及缓存更新时序就存在如下这几种:

cache.delKey(key); db.update(data); Thread.sleep(xxx); cache.delKey(key);

-
Read Through:当数据发生更新时,查询缓存时更新缓存,然后由缓存层同步的更新数据库即可,对调用方而言只需要和缓存层交互即可; -
Write Through:Write Through 套路和Read Through相仿,不过是在更新数据时发生。当有数据更新的时候,如果没有命中缓存,直接更新数据库,然后返回。如果命中了缓存,则更新缓存,然后再由Cache自己同步更新数据库。如下图所示(来源于网络):

缓存的存在是为了系统高性能,利用内存的IO读取的高速的特性,来提升系统的性能,提高系统吞吐量,另外,缓存的存在会让一部分读请求不会到达db层,分解了db的压力,毕竟db是最容易出现瓶颈的地方。这是为什么利用缓存的两个重要原因。但是,带来的问题就是,数据会存在在两个地方分别是缓存以及数据库中,当数据更新的时候就需要思考让”正确的数据应该放在哪个最可信的存储介质上“,就需要结合业务性质在两个数据存储介质上进行选择。
4.1 数据不一致的原因


如果系统通过消息异步更新操作成本过高或者依赖于外部系统无法进行订阅binlog异步更新的话,就需要来采用过期缓存数据来保障数据最终一致性。
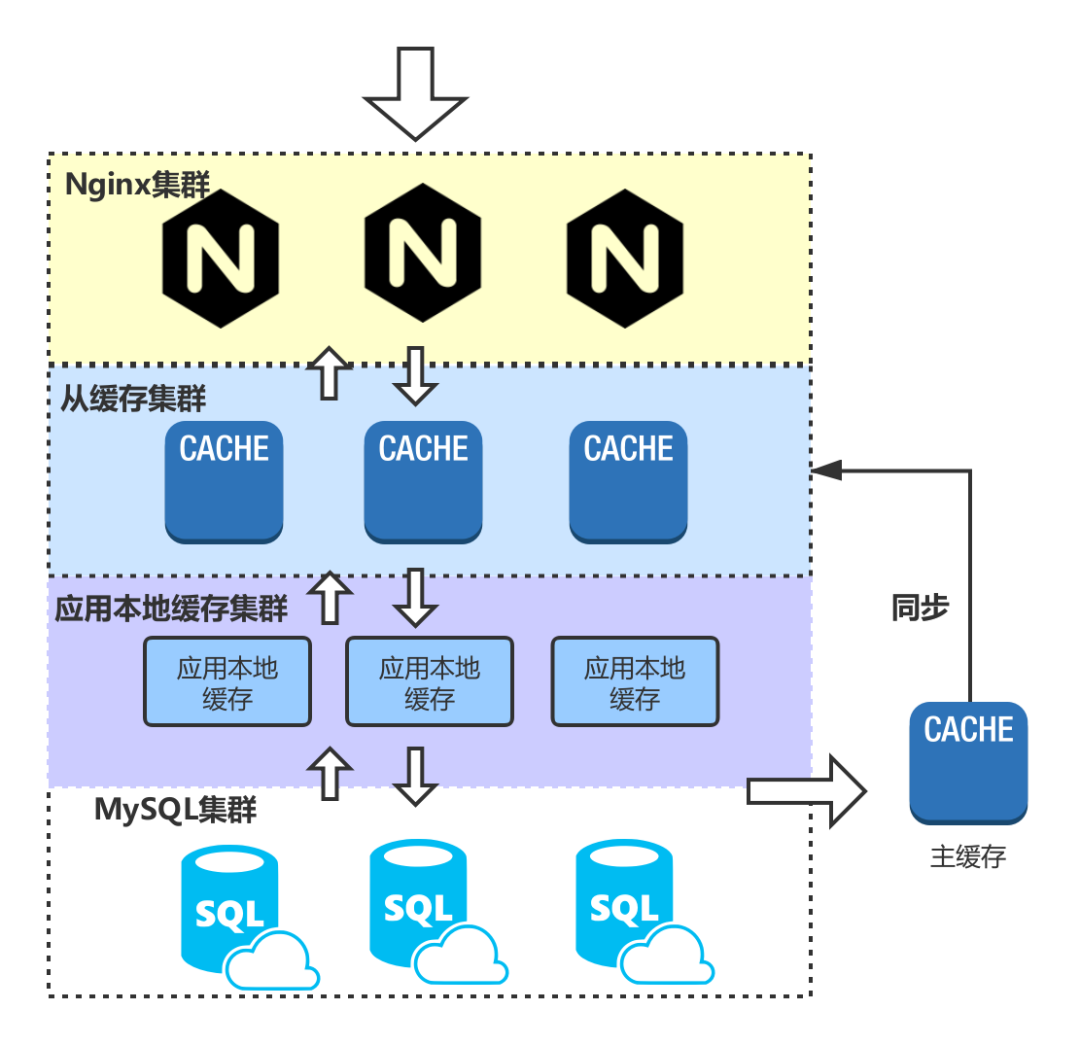
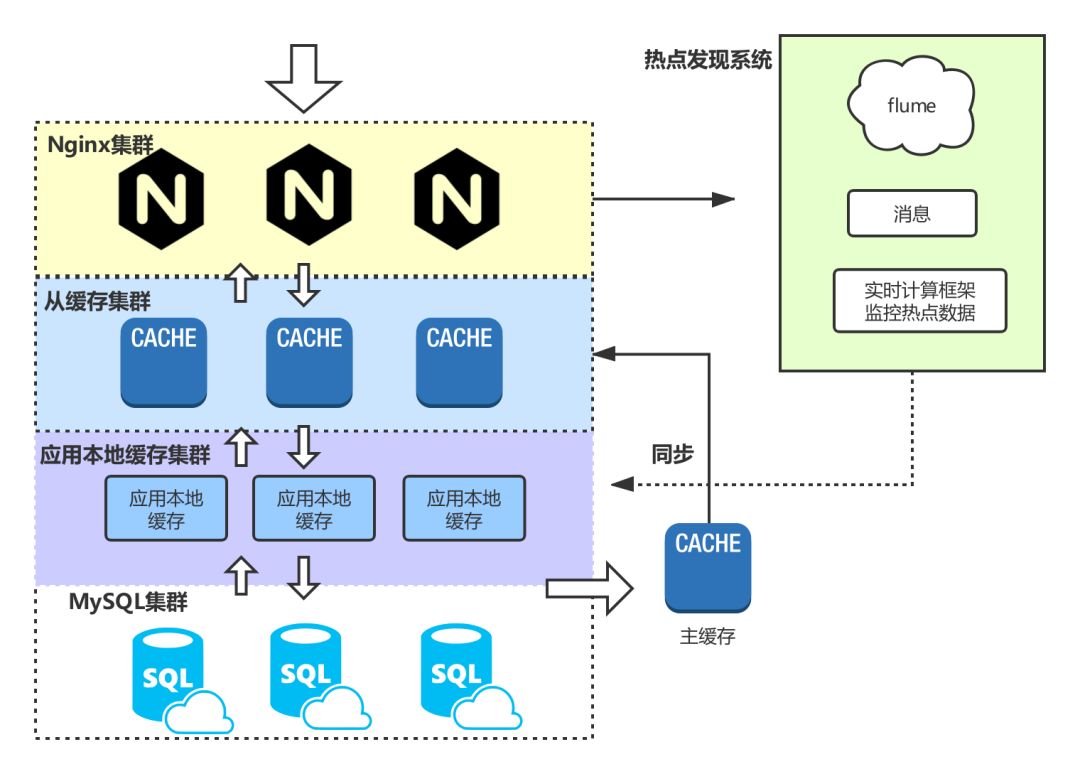
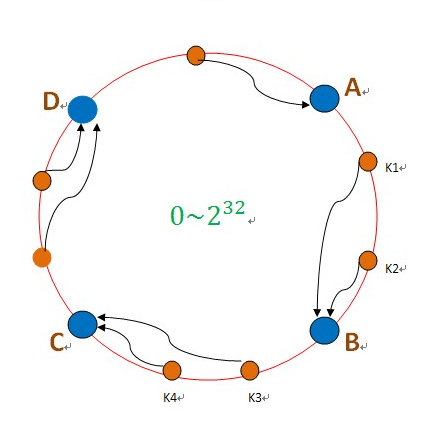
如果key路由策略采用的一致性哈希的话,某一个实例节点故障,只会导致哈希环上的部分缓存不命中不会导致大量请求到达db,但是针对热点数据的话,可能会导致改节点负载过高成为系统瓶颈。针对实例故障恢复的方式有:1. 主从机制,对数据进行备份,尽可能保障有可用数据;2. 服务降低,新增缓存实例然后异步线程预热数据;3. 可以先采用一致性哈希路由策略,当出现热点数据时到达某个阈值时降级为取模的策略。

长按识别二维码,立刻报名
Java的重要性和流行度无需多说啦,你们都懂的![]() ,快识别下方二维码或点击文末“阅读原文”学起来。
,快识别下方二维码或点击文末“阅读原文”学起来。
 ,快
,快



开源 | 全球首个批流一体机器学习平台 Alink

5G的7大用途,你知道几个?


登录查看更多
相关内容

数据库(
Database )或数据库管理系统(
Database management systems )是按照数据结构来组织、存储和管理数据的仓库。目前数据管理不再仅仅是存储和管理数据,而转变成用户所需要的各种数据管理的方式。




相关VIP内容
相关资讯