实例+代码,你还怕不会构建深度学习的代码搜索库吗?

本文为 AI 研习社编译的技术博客,原标题 How To Create Natural Language Semantic Search For Arbitrary Objects With Deep Learning,作者为 Hamel Husain 。
翻译 | 陈涛 赵朋飞 汪星宇 校对 | 刘娇 整理 | MY
本文展示了一个端到端的实例,说明如何构建一个可以语义化搜索对象的系统。项目作者是 Hamel Husain (https://www.linkedin.com/in/hamelhusain/) 和 Ho-Hsiang Wu 。

Hubot 的图片
项目的动机
不可否认的是,现代的搜索引擎非常强大:你可以随时从互联网上搜集到知识信息。美中不足的是,它还不是万能的。在许多情况下,搜索只是被当做严格的关键字搜索,亦或者当对象不是文本时,搜索便无用武之地。此外,严格的关键字搜索不允许用户进行语义化搜索,这意味着无法查询到相关信息。
今天,我们分享一个可复现的最小可行性产品,以此来说明如何对任意对象进行 [语义搜索](https://en.wikipedia.org/wiki/Semantic_search)!具体来说,我们将向您演示如何创建一个可对 python 代码进行语义化搜索的系统——但该方法同样可以被推广到搜索其他实体(比如图片或者声音片段)
为什么语义搜索如此何令人兴奋?考虑下下文的例子。

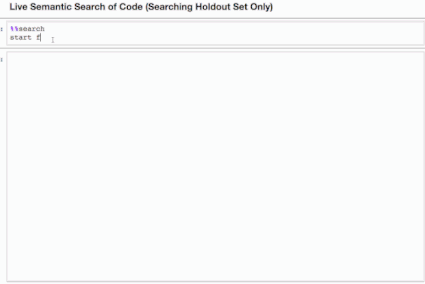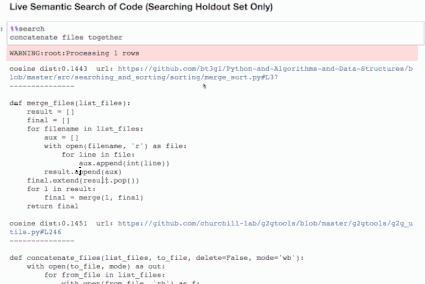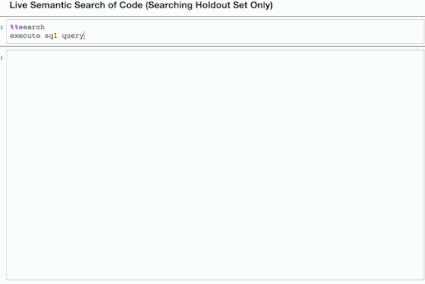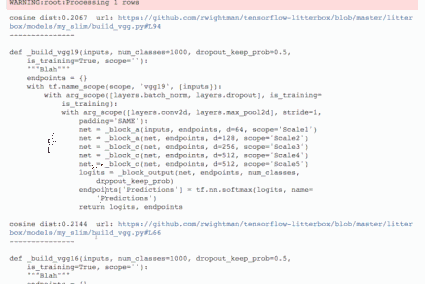
对 python 代码进行语义化搜索。*请参阅后文的免责申明
图中提交的搜索查询是「Ping REST api and return results」。然而,搜索能够返回合理的结果,即使该结果的代码和注释中不包含单词 Ping、REST 或 api。
这彰显了语义搜索(https://en.wikipedia.org/wiki/Semantic_search)的强大之处:除了通过关键字,我们还可以通过意思搜索内容,从而最大限度地提高了用户找到所需信息的机会。语义搜索具有重要意义——比如,此搜索过程将允许开发人员在仓库中搜索代码,即使他们并不熟悉代码的相关语法,亦或是没能输入正确的关键字。更重要的是,你可以将此方法推广到其他对象的搜索,诸如图片、音频以及其他我们尚未想到的内容。
如果这还不够令人兴奋,那么现在就演示一下当你读完本教程后能够构建的系统:

有时候,当我无法建立一个漂亮网站时,我会使用 Jupyter notebooks 及其自定义魔术功能来创建演示。这是一种交互式演示工作的快速方法。
直观了解构建共享向量空间的过程
在深入了解技术细节之前,最好还是先对如何实现语义搜索有一个直观了解。核心思想是将搜索文本和我们想要搜索的对象(代码)表示在同一个共享向量空间中,如下所示:

例子:文本 2 和代码应由类似的向量所表示,因为它们直接相关
目标是将代码映射到自然语言的向量空间中,经过余弦相似度的距离度量后,描述相同概念的(文本,代码)组中的向量距离更近,而无关的(文本,代码)组中的向量离得更远。
有许多方法可以实现这一目标,然而我们将演示使用预训练模型的方法。该模型从代码中提取特征,并对此模型进行微调,从而将潜在代码特征映射到自然语言的向量空间中。需要注意的是:我们在本教程中交替地使用术语向量和嵌入。
先修知识
在阅读本教程之前,我们建议你先熟悉以下内容:
序列到序列模型:复习前一个教程中的知识会很有帮助。
仔细阅读这篇论文并充分理解其中提出的方法。我们在本文中使用了相似的概念。
概述
本教程将分为 5 个具体步骤。这些步骤如下图所示,可以作为你阅读教程时的一个有用参考。当你完成教程后,回看此图将有助于你进一步了解所有步骤是如何组合在一起的。
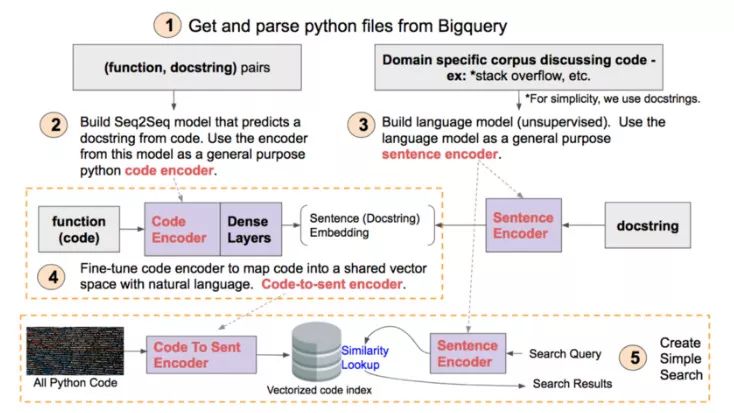
本教程的思维导图。高清版本在这里(https://github.com/hamelsmu/code_search/blob/master/notebooks/diagram/Diagram.png)
1-5 的每个步骤对应于这里(https://github.com/hamelsmu/code_search/tree/master/notebooks)的 Jupyter notebook。我们将在后文详细讨论每个步骤。
第一部分——获取和解析数据
第一部分笔记https://github.com/hamelsmu/code_search/blob/master/notebooks/1%20-%20Preprocess%20Data.ipynb
谷歌公司收集了开源社区 GitHub 中的数据,并将其存储于 BigQuery 中。这是一个很好的公开数据集,适用于各种有趣的数据科学项目,也包括本项目!当你注册了 Google Cloud 账号后,你将会得到 300 美元,这足以查询到此次练习所需要的数据。获取数据非常方便,因为你可以使用 SQL 查询语句来选择要寻找的文件类型以及其他关于仓库的元数据,例如提交数和打星数等。
笔记中介绍了获取数据的步骤。幸运的是,一些谷歌 Kubeflow 团队中的牛人已经完成了这些步骤,并且贴心地存放好了此次练习需要用到的数据,详见其中的信息。
搜集到数据后,我们需要将这些文件解析为(代码,文档字符串)组形式的数据。对于本教程,一个代码单元可以是顶级函数可以是方法。我们希望收集这些数据组作为模型的训练数据,该模型能对代码进行概括(具体我们过会再说)。我们还想删除代码中的所有注释,只保留代码本身。这似乎是一项艰巨的任务。但是在 Python 的标准库中有 ast 库,其可用于提取函数、方法和文档字符串。我们可以通过先将代码转换为抽象语法树,然后使用 Astor 包将其转回代码,从而将代码中的注释删除。本教程不涉及抽象语法书及其相关工具的工作原理,但这些都是非常有趣的主题。

关于此代码使用的场景,详见于笔记(https://github.com/hamelsmu/code_search/blob/master/notebooks/1%20-%20Preprocess%20Data.ipynb)
为了给建模准备数据,我们将数据分为训练集、验证集和测试集。我们还保存了原始文件(我们将其命名为 lineage),以便记录每个(代码,文档字符串)组的来源。最后,我们对不包含文档字符串的代码应用相同的转换,并分开保存,因为我们也希望能够搜索此类代码。
第二部分 :使用 Seq2Seq 模型构建代码归纳器
第 2 部分笔记
https://github.com/hamelsmu/code_search/blob/master/notebooks/2%20-%20Train%20Function%20Summarizer%20With%20Keras%20%2B%20TF.ipynb
从概念上讲,我们可以建立一个 Seq2Seq 模型来归纳代码,与我们之前介绍的 GitHub issue summarizer 完全相同——我们使用 python 代码代替原来的 issues 数据,并且使用 docstring 来代替 issue 标题。
然而,与 GitHub 的 issue 文本不同的是,代码不属于自然语言。为了充分利用代码中的信息,我们可以引入特定领域的优化方法,如 tree-based LSTMs 和语法感知标记 (syntax-aware tokenization)。简单起见,在本教程中我们将代码当作自然语言进行处理(最终获得了合理的结果)。
建立函数归纳器本身是一个很酷的项目,但是我们不会在这上面花太多时间(有兴趣的读者朋友可以试一试)。这个模型的完整端到端训练过程都已经记录在笔记上了。我们不讨论这个模型的预处理或架构,因为它与问题归纳器完全相同。
我们训练这个模型的动机不是为了对代码进行归纳,而是想要对代码进行通用的特征提取。从技术上来说这一步是可选的,因为我们只是通过这些步骤对后面的模型进行权重初始化。然后我们从这个模型中提取编码器并进行微调,以适用于另一个任务。下面是这个模型的一些示例输出截图:
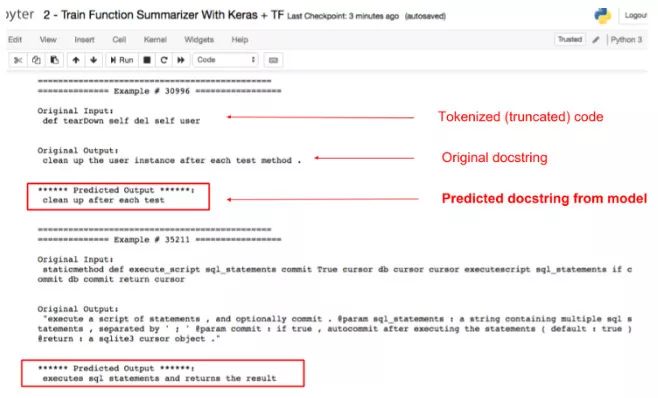
函数归纳器在测试集上的采样结果,点击这里查看。
从图中可以看到,虽然结果不完美,但是却有力地表明了该模型已经学会从代码中提取一些语义信息,这就是我们这个任务的主要目标。我们可以用 BLEU metric 对这些模型进行定量评估,这也在笔记中讨论过。
应该注意的是,训练一个 seq2seq 模型来归纳代码并不是代码特征提取的唯一技术。例如,你也可以训练一个 GAN,使用鉴别器作为特征提取器。其他方法超出了本教程的范围,故不在此叙述。
第三部分:训练一种语言模型来编码自然语言短语
第 3 部分笔记
https://github.com/hamelsmu/code_search/blob/master/notebooks/3%20-%20Train%20Language%20Model%20Using%20FastAI.ipynb
现在我们已经创建了将代码表示为向量的机制,我们需要一种类似的机制来对自然语言短语进行编码,就像在 docstring 和搜索查询中的那样。
有很多通用的预先训练的模型可以产生高质量的短语嵌入(称为句子嵌入),这篇文章对这方面做了很好的概述。例如,谷歌的通用句子编码器在很多案例中使用的很好,可以在 TensorFlow Hub (https://www.tensorflow.org/hub/modules/google/universal-sentence-encoder/1)上获取。
采用预训练好的模型不仅方便,而且便于获取特定领域的词表和 docstrings 的语义。有很多技术都可以用于实现句子嵌入,对句子中每个词的词向量求平均是一种比较简单的方法,而那些通用语句编码的技术则更为复杂。
在这篇教程中,我们将利用 AWD LSTM 这个神经语言模型生成句子嵌入。令人难以置信的是,fast.ai 库可以让你非常便捷地使用这个技术,而且不用考虑太多的细节。下面是我们创建这个模型的代码片段,关于代码如何工作的更多内容,请参考这个笔记(https://github.com/hamelsmu/code_search/blob/master/notebooks/3%20-%20Train%20Language%20Model%20Using%20FastAI.ipynb)。

以上是使用 fast.ai 时 train_lang_model 函数的一部分
在构建语言模型时,需要仔细考虑将要用于训练的语料库。理想情况下,你会使用与目标问题类似的语料库,这样就可以充分地捕获相关的语义和词汇。例如,对本实验来说 stack overflow 数据是一个很好的语料库,因为这个论坛中包含了非常丰富的代码讨论。但是为了保持本教程的简单性,我们依然将 docstring 集用作语料库。这是个次优选择,因为 stack overflow 通常比单行 docstring 包含更丰富的语义信息。这个可以作为练习,感兴趣的读者可以替换语料库并观察它对最终结果的影响。
训练完语言模型后,我们接下来的任务是是用这个模型为每个句子生成嵌入。完成这个工作的通用方法是合并语言模型的隐状态向量,例如这篇文章提到的合并池化方法。然而,为简化起见,我们直接取所有隐状态向量的平均值。我们可以快速地从 fast.ai 的语言模型中提取隐状态向量的平均值,代码如下:
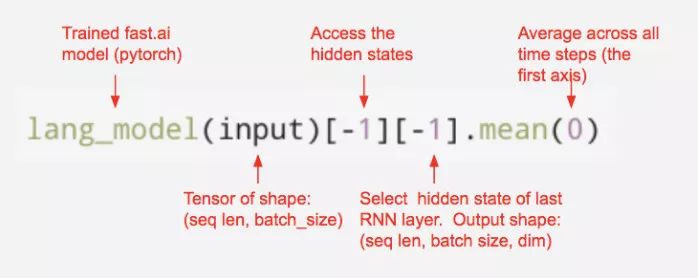
这里应用了如何从 fast.ai 语言模型中提取句子嵌入
一个评估句子嵌入的好方法是衡量它们在情感分析、文本相似性等下游任务的功效如何。你可以使用通用的基准测试来衡量嵌入质量,这里举出了一些例子。然而,这些基准测试可能不适合我们的问题,因为我们的数据针对特定领域。现阶段,我们尚未为代码语义这个任务设计任意可以开放源码的下游任务。在没有这样的下游任务的情况下,我们至少可以人工判断意义相近的短语之间的相似性来检查这些嵌入项是否包含语义信息。下面的截屏展示了一些案例,我们通过向量化 docstrings 的方式来搜索用户目标短语的相似性(参考这份笔记):

手工检测文本相似度是否合理,更多例子请参考这份笔记
需要注意这只能检查数据的合理性——一个更严格的方法是测量这些嵌入对各种下游任务的影响,并用它形成对嵌入质量更客观的 看法。关于此话题的更多讨论情参照这份笔记。
第四部分:训练模型以将代码向量映射到自然语言中相同的向量空间
第4部分笔记
https://github.com/hamelsmu/code_search/blob/master/notebooks/4%20-%20Train%20Model%20To%20Map%20Code%20Embeddings%20to%20Language%20Embeddings.ipynb
在这一部分重温本文开始介绍的示意图可能会对你有帮助。在示意图中,你将找到第四部分中的这个图:

第四部分的演示流程图
这部分大多根据前面的步骤进行。为了预测文档字符串嵌入,在这个步骤中我们将会对第二部分中的 seq2seq 模型进行微调。下面是我们从 seq2seq 模型中提取编码器并添加全连接层进行微调的代码:
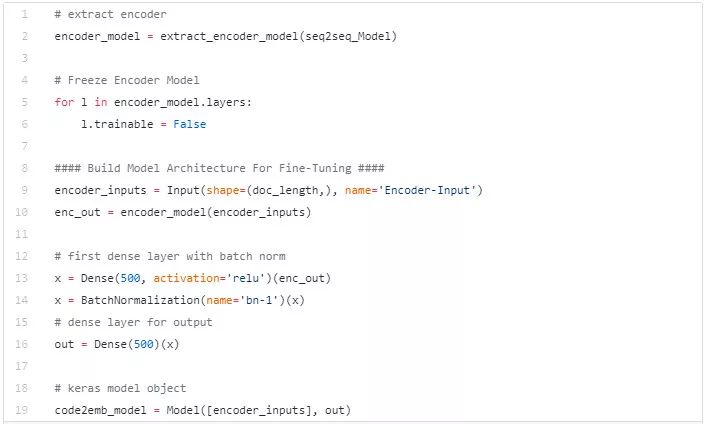
建立一个模型将代码映射到自然语言的向量空间。在这份笔记里可以了解更多相关内容。
在我们训练完这个模型的整合版本之后,我们分解模型的层并且对这个模型再训练几轮。这有助于对模型进行微调以更好地完成此任务。这里有完整的教程 this notebook.
最后,我们的目的是将代码向量化,因此我们可以建立一个搜索索引。为了评估本实验的效果,我们会将不包含文档字符串的代码向量化,来看看这个模型会如何计算我们没有见过的数据。
下面是一个(取自这份笔记)实验的代码片段. 我们使用了 ktext library 来进行预处理步骤。

使用 code2emb 模型将代码映射到自然语言的向量空间。在笔记中可以了解更多内容。
向量化代码之后,我们准备进行最后一步!
第五部分: 创建一个语义搜索工具
第5部分笔记
https://github.com/hamelsmu/code_search/blob/master/notebooks/5%20-%20Build%20Search%20Index.ipynb
在这一步中,我们将使用我们在前面步骤中创建的模型构建一个搜索索引,如下所示:

第 5 部分的图(截取自本文开始处的流程图中)
在第 4 部分中,我们向量化了不包含任何文档字符串的所有代码。下一步是将这些向量放到一个搜索索引中,以便快速检索最近的邻居。nmslib 是一个很便捷的包含最近邻的 python 库,在使用之前你必须先生成搜索索引:

使用 nmslib 建立索引的方法
现在你已经建立了你的代码向量搜索索引,你需要一个方法来将你的字符串变成向量。为了完成这个你将用到在第三部分中的语言模型。为了使这个过程更简便,我们提供了一个在 lang_model_utils.py 中的课程: Query2Emb, 在这里有示例。
最终,一旦我们能够将字符串转华成查询向量,我们就可以为这个向量检索最近邻:

这个搜索索引将会转化两个项目:(1) 一个索引表,它包括了数据库中最近邻居位置的整型数据(2)从查询向量到它的最近邻的距离(这里使用 cosine 距离)。一旦获取了这个信息,创建语义搜索就比较简单。如下代码可以作为示范:

一个将所有需要构建语义搜索的部分聚合在一起的类。
最后,这份笔记向您展示如何使用上面的 search_engine 对象创建如下的交互式演示:
这与教程开头的 gif 是同样的。
恭喜你学到了这里!希望创建语义搜索的方法能对你有帮助。
那么,假如搜索任意的东西应该怎么做呢?
尽管此教程仅描述了如何为代码创建语义搜索,你可以在搜索视频,音频和其他数据时使用类似的技巧。假如不能像第二部分中那样直接从代码中提取特征模型,那你需要训练或找到一个预训练模型,它可以从对象中自动提取特性。唯一的先决条件是您需要一个具有自然语言注释的足够大的数据集(如音频的转录本或照片的字幕)。
我们相信你可以根据在本教程中学到的想法来进行你自己的研究,欢迎来信交流(参见下面联系方式)。
限制和遗漏
本博客中讨论的方法被简化了并且仅对可能的情况做了浅层的描述。我们所展示的是一个非常简单的语义研究——然而,为了使这样的研究 更有效,你可能需要额外搜索关键词或者需要额外的过滤器及规则。(比如搜索一个具体协议,用户,或者组织和其他机制来进行参考)
可以利用代码结构(如 tree-lstms)来提取特定领域的特征。此外,还有其他一些标准的技巧,如利用那些我们为了简单而省略的 attention 和 random teacher forcing。
搜索质量的评价问题经常被我们忽略。这个复杂的问题值得进行专门的研究。为了有效地对这个问题进行迭代,你需要一个客观的算法去衡量搜索结果的质量。这个问题会成为未来某个博客的主题。
联系方式
我们希望您喜欢本篇博客,请随时与我们联系:
Hamel Husain: Twitter, LinkedIn, or GitHub.
Ho-Hsiang Wu: LinkedIn, GitHub
资源
此文章资源地址: The GitHub repo (https://github.com/hamelsmu/code_search)
为了让那些试图复制这个示例的人更容易,我们将所有依赖项打包到一个 Nvidia-Docker container. 不熟悉 Docker 的读者可以查看这篇博客(this post to be helpful)。链接: link to the docker image for this tutorial on Dockerhub。
我对任何努力学习深度学习知识的读者的第一建议是去学习 Jeremy Howard. 的 Fast.A。我在那里学到了许多在本篇博客中需要的知识。另外,此教程应用到了 fastai library。
关注 this book,它虽然是早期版本,但为语义搜索提供了一些有用的细节。
Avneesh Saluja 的演讲强调了 Airbnb 如何研究利用共享向量空间来对列表和其他数据产品进行语义搜索。
致谢
版面设计 search UI 是由 Justin Palmer 设计的(你可以在这里看到他的其他作品 here)。同样对校对和付出精力的编者表示感谢:Ike Okonkwo, David Shinn, Kam Leung。
原文链接:
https://towardsdatascience.com/semantic-code-search-3cd6d244a39c
想浏览更多深度学习文章?
欢迎点击“阅读原文”
或者移步 AI 研习社社区~




