干货 | CMU博士生杨植麟:如何让AI像人类一样学习自然语言?
本文分享了无监督学习和情景化学习的一些最新进展,其中包括一篇 ICLR Oral 论文的解读。
AI 科技评论按:近几年,由于深度神经网络的快速发展,自然语言处理借此取得了重大突破,但同时也达到了它的发展瓶颈期。因此,研究如何让 AI 像人类一样去学习自然语言成为了现在研究者们最关心的问题。
在近期 GAIR 大讲堂上,来自卡内基 · 梅隆大学三年级博士生杨植麟同学分享了无监督学习和情景化学习的一些最新进展,其中包括一篇 ICLR Oral 论文的解读,点击阅读原文可查看完整视频回放。
杨植麟,卡内基梅隆大学博士三年级,师从苹果人工智能主任 Ruslan S.,主要研究无监督深度学习及其在自然语言理解的应用;过去两年在 ICLR/NIPS/ICML 等人工智能顶会发表 11 篇文章 (9 篇一作);曾在 Facebook 人工智能实验室从事研究工作,本科以年级第一毕业于清华计算机系。
让人工智能像人类一样学习自然语言:无监督学习和情景化学习的最新进展
无监督学习:高秩自然语言模型 (ICLR 2018)
基于生成式模型的半监督学习:利用无标注文本提升问答 (ACL 2017, NIPS 2017)
情景化学习:土耳其机械勇士下降法 (ICLR 2018)
近几年,深度神经网络在自然语言学习任务上取得众多突破,但是仍然依赖于大规模静态标注数据。与此相反,人类学习语言的时候并不需要大规模监督信号,并且可通过与环境的交互理解语言。
先来回顾一下近些年 NLP 的状况。NLP 发展的黄金时期出现在 2013 年末和 2014 年这段时间。这段时间出现三个非常重要的技术:Word embeddings;Seq2seq;Attention,这三项技术基本奠定了 2014 年之后的 NLP 发展基础。
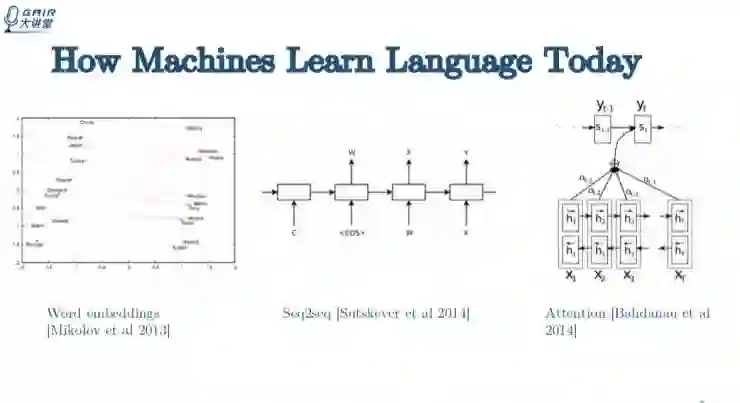
从 2015 年到现在,大家做的主要事情就是把三个技术都用上,做各种各样的变种,用在不同的任务上来检验模型效果。单从效果上来看,还是有到很多突破的。但有两点需要注意,依赖监督学习可能已经做到了极限;监督学习有两个问题,一是依赖大规模标注数据集,二是依赖静态数据集。

反观人类是如何学习语言的?人类只需要非常少的监督信号,通过动态与环境交互,在环境中执行一些行为,得到一些反馈,进行学习语言。

如果让机器像人类一样学习,就需要突破监督学习的瓶颈。接下来讲的就是在这一方面的探索,怎样让机器像人类一样学习自然语言。
先看一下这个,Mastering the Dungeon : Grounded Language Learning by Mechanical Turker Descent。其中的
Mastering the Dungeon 是我们创造的一个游戏环境,Mechanical Turker Descent 是我们发明的算法名字。
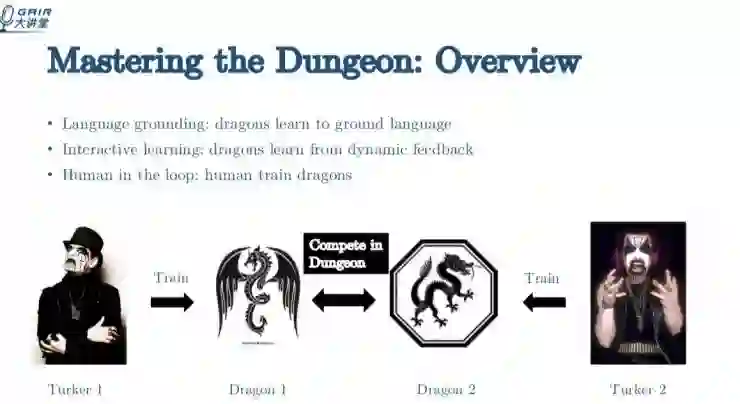
图中的两个人(Turker1 和 Turker2)相当于平台上的两个用户。他们每个人负责训练一个 dragon,如果 dragon 赢了,对应的人会获得奖励。这样 Turker 就会受到激励,会给 dragon 更好的样本学习,让它在比赛中击败其他 dragon。
下图反应了 dragon 在游戏环境中具体是如何交互学习的,以及具体的游戏环境是怎么样的。

这个交互学习算法的名字叫 Mechanical Turker Descent。第一步,每一个 Turker 会给 dragon 一些训练数据,第二步,用数据集训练出一个模型。第三步,这些模型会放在其他数据集上交互验证,每个模型会得到分数,获得高分的 Turker 会获得奖励。第四步,所有的数据将合并起来,进入下一轮,直到训练出比较好的 agent。
这个算法其实既有比赛,又有合作。Turker 为了赢得奖励,所以他们之间相互比赛,促使他们提供更好的数据给 dragon。同时他们又是合作的,在每一轮结束后都会把数据合并起来进入下一轮,这些数据在下一轮都会共享。
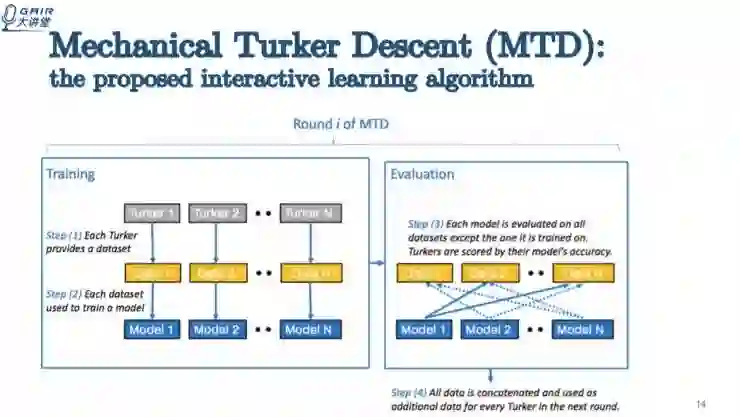
这样的算法有四个优点:
第一,避免数据样本太简单,因为每个 Turker 都是在对方的数据集上做验证,如果太简单,就会导致对方的分数比自己高。
第二,避免数据样本太难,如果样本太难,就不可能训练出模型,同样不能赢得比赛。
第三,难易度适中的数据可以动态适应模型学习的能力。
第四,很难通过作弊获得好成绩。
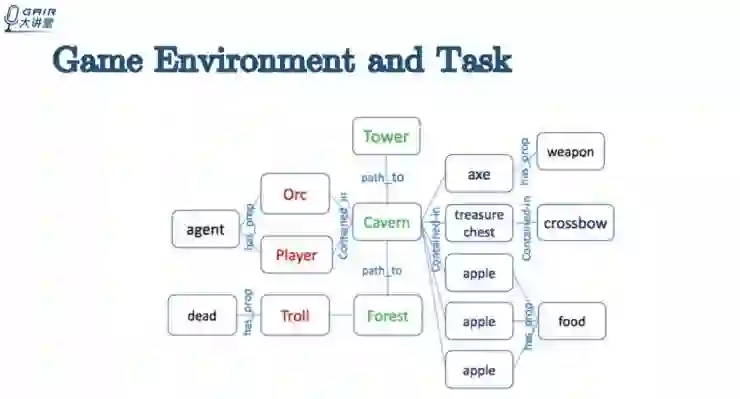
游戏环境和任务设置
实验结果
通过实验得出几点结论,实验中的交互学习算法确实比传统通过标记数据的静态学习效果要好。

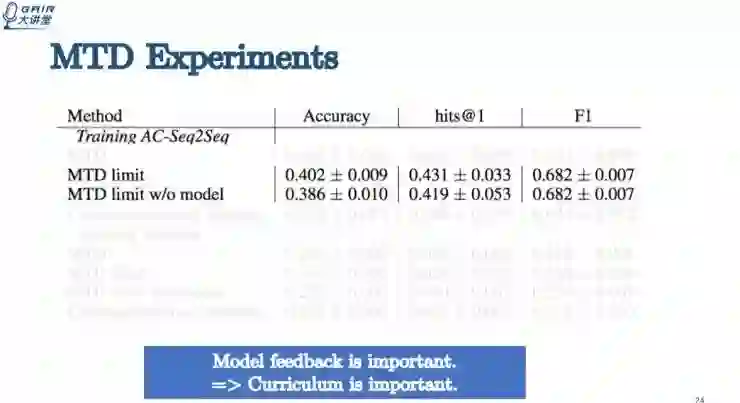
limit 是指限制 Turker 每一轮给的训练数据数量。在给同样奖励的情况下,发现如果不限制 Turker,他会多给 dragon 30% 的数据,最终的模型表现效果也较好。

在模型有反馈和没有反馈的两种不同情况下,其性能表现也有很大的差别。如果把模型反馈去掉,所有的指标都会下降,说明动态调整训练数据的动态分布是非常重要的。
接下来杨植麟同学介绍一篇 ICLR Oral 论文的解读。论文题目为:Breaking the Softmax Bottleneck A High-Rank RNN Language Model。

我们首先证明了softmax不是太好,继而提出了混合softmax, (mixture of softmaxes)的方法,先算K softmaxes, 用weighted sum得到最后的概率。


虽然很简单,但在大家常用的语言模型数据集中,取得了非常好的结果。

由于篇幅限制,这里就不做文字解读了,大家如果感兴趣可以直接去看这篇论文或者点击阅读原文观看完整视频回放。

未来最重要的两个研究方向,一个是无监督学习,另一个是 language grounding。
无监督学习可以学习有价值的和可传递的特征表示,可以改善低资源和高资源任务; 可以用于监督或无监督任务的元学习。language grounding 可以提供足够复杂的环境,是一种非常有效的学习算法。
对了,我们招人了,了解一下?

4 月 AI 求职季
8 大明星企业
10 场分享盛宴
20 小时独门秘籍
4.10-4.19,我们准时相约!

┏(^0^)┛欢迎分享,明天见!





