纸质说明书秒变3D动画,斯坦福大学吴佳俊最新研究,入选ECCV 2022
羿阁 发自 凹非寺
量子位 | 公众号 QbitAI
有没有空间感差的小伙伴,每次拿到乐高说明书都不知如何下手?

这回,可以动的乐高说明书来了!
清华姚班校友、斯坦福大学助理教授吴佳俊,带领团队研发了一项能把纸上的说明书转化为3D动画的技术,目前该论文已入选2022年计算机视觉顶会ECCV。


看完效果图,有网友直呼:这对所有年龄段的乐高爱好者都大有帮助!

3D动画说明书
尽管乐高的说明书都是由专业设计师编写的,但对于想象力差的人,不得不说,还是3D动画更香。

这一步转化看上去容易,其实背后隐藏着两个技术上的难题。
第一个难题是如何将纸上的2D图像投影成3D动画。
研究团队要做的,是将任务分解为一系列可以顺利、高效执行的短步骤,通过建立一个模型,将说明书上的图像转换为机器可解释的算法,以简化机器学习的任务。
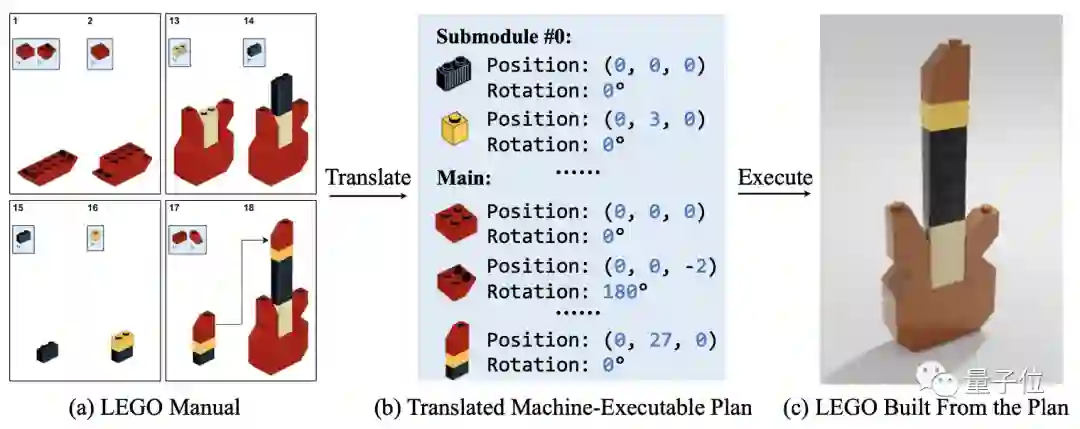
正如上图所示,要想把图a转化为图c,需要提取说明书中的每一个零件的图像位置,以便搭建最终的成品。
研究面对的第二个挑战是,乐高积木的形状实在是太多变了。
虽然很多基础配件形状差不多,但就像图中的吉他头一样,乐高也有不少灵活又复杂的配件。而且,这些配件可能产生的不同组合也大大增加了机器解读的难度:每一个搭建步骤都会形成一个新的不可知的图像。

为了解决这两个挑战,研究团队提出了一种新的基于机器学习的框架:手动执行计划网络(manual-To-executable-Plan Network, MEPNet)。
其核心思想是将基于神经网络的二维关键点检测方法与2D-3D匹配算法相结合,实现对不可见的3D对象的高精度预测。
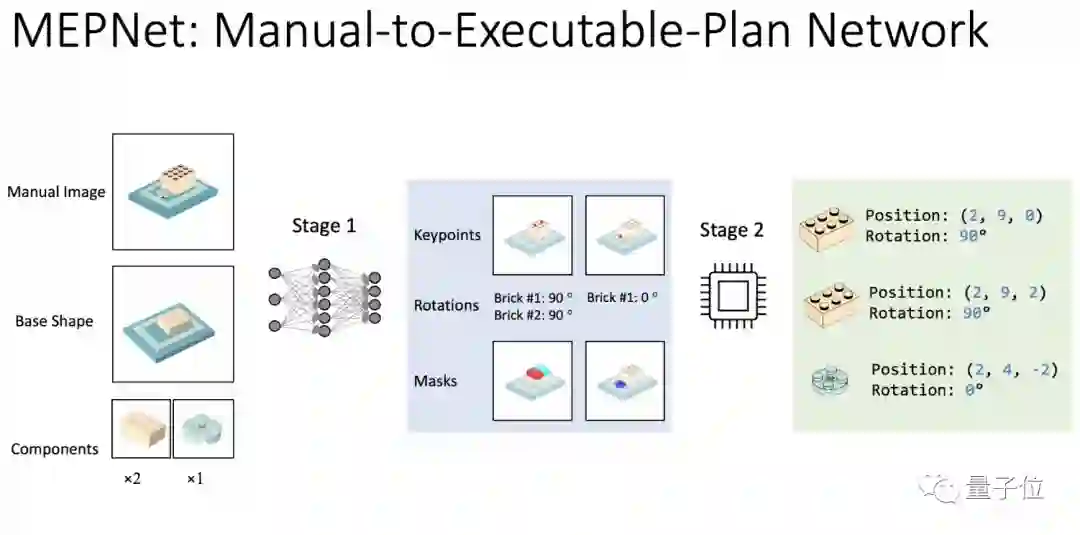
MEPNet的运行有两个阶段。第一阶段要做的,是将基础形状和新零件的3D模型、目标形状的2D图像作为输入信息,为每个零件预测一组2D关键点、旋转角度和掩码。
在第二阶段中,通过寻找基础形状和新零件之间的可能联系,再将第一阶段预测的2D关键点反向投影到3D图像中。
值得一提的是,这个方法在训练时不需要任何ground truth图像。
另外,MEPNet的数据集表现优于其他现有方法。与基于端到端的学习方法相比,MEPNet保持了基于机器学习的模型效率,并可以被更好地推广到生成未知的3D对象上。
最值得注意的是,MEPNet能够利用合成数据进行单独训练,从而应用到真实的生活场景中。
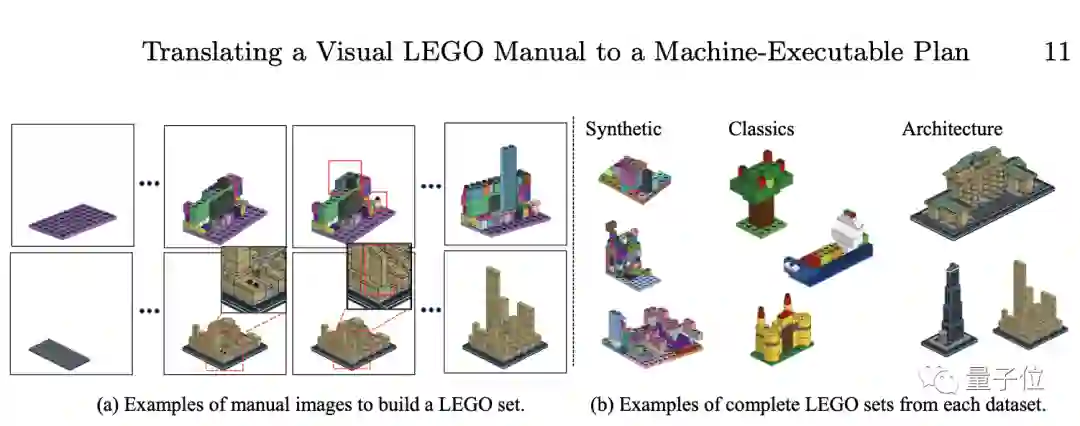
目前,所有代码和数据已开源,感兴趣的小伙伴可以关注一下。
作者介绍
该篇论文来自斯坦福大学吴佳俊团队。作者还包括:Ruocheng Wang、Yunzhi Zhang,麻省理工大学的Jiayuan Mao以及Autodesk AI Lab的Chin-Yi Cheng。
吴佳俊,现任斯坦福大学助理教授,隶属于斯坦福视觉与学习实验室 (SVL)和斯坦福人工智能实验室 (SAIL)。在麻省理工学院完成博士学位,本科毕业于清华大学姚班,曾被誉为“清华十大学神之一”。

论文第一作者Ruocheng Wang,硕士毕业于斯坦福大学计算机科学专业,是吴佳俊门下的学生。本科毕业于浙江大学计算机专业,还在加州大学洛杉矶分校与Adnan Darwiche教授一起工作过一段时间。

One More Thing
虽然整篇论文都在以乐高为例,但作者也在论文中提到,其实这项技术还能应用到其他类型的组装说明书上。
好多“苦安装久矣”的网友就号召赶紧推出宜家版:

不过,在一片欢呼声中,也有网友提出了不同的声音:
我不知道这是惊喜还是毁了我玩乐高的乐趣。
对此,你怎么看?你是喜欢看着说明书拼乐高,还是自己发挥呢?
参考链接:
[1]https://cs.stanford.edu/~rcwang/projects/lego_manual/
[2]https://twitter.com/_akhaliq/status/1552118469214314496
[3]https://arxiv.org/abs/2207.12572
[4]https://jiajunwu.com/
— 完 —
「人工智能」、「智能汽车」微信社群邀你加入!
欢迎关注人工智能、智能汽车的小伙伴们加入我们,与AI从业者交流、切磋,不错过最新行业发展&技术进展。
ps.加好友请务必备注您的姓名-公司-职位哦~

点这里👇关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见~


