R 语言之数据分析高级方法「主成分分析」和「因子分析」

作者:姚某某
博客:https://zhuanlan.zhihu.com/mydata
往期回顾:

本节主要总结「数据分析」的「主成分分析」和「因子分析」的思想。
通过学习《 R 语言实战 》关于这两种方法的解释,我们很容易理解这两种方法其存在的意义。——降维。
我们将要面对的数据实在是太大,变量实在太多,因此计算机所承受的压力也会越来越大。信息过度复杂是多变量数据最大的挑战之一,特别是在还要考虑变量间交互关系的时候,变量增加时交互关系的量是按阶乘关系在往上涨的,所以降维在很多时候能够起到减少大量工作量的作用,是数据分析很重要的一个思想。
以上是「主成分分析」与「因子分析」联系,有共同的目的。但是,两者的区别也很大,在实现目标时,两者采用了两种不同的思路,下面我逐一讨论。
1. 主成分分析与因子分析的不同
主成分分析 ( PCA ) 是指,用一组较少的不相关变量代替大量相关变量,同时尽可能保留初始变量的信息。值得注意的是,主成分是初始变量的线性组合。
因子分析 ( EFA ) 是指, 通过发掘隐藏在数据下的一组较少的、更为基本的无法观测的变量,来解释一组可观测变量的相关性。
区别:从定义上其实就很好理解,但是更简单的理解方式:把「因子分析」看作是求得「元素」,这些元素是组成初始变量的因子;而把「主成分分析」看作是求得一种「组合」,这些组合是初始变量配给不同系数组成的「组合」,且每个组合之间不相关。
2.主成分分析
2.1. 主成分
主成分是初始变量的线性组合,用于替代初始变量并尽可能保留初始信息。如第一主成分:
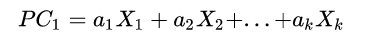
它是 k 个观测变量的加权组合,对初始变量集的方差解释性最大。
至于主成分是如何推导得到的,请看这篇PCA (主成分分析)详解 (写给初学者)(https://my.oschina.net/gujianhan/blog/225241#OSC_h2_1),建议跟着思索一遍,对其底层算法有一点理解,在学习的时候更开心。
2.2. 判断主成分的个数
之前讲到,主成分分析的目的是为了降维,因此对于主成分的个数,我们必须有所取舍。
一般的方法是,基于特征值来判断主成分的个数:
每一个主成分都有其对应的特征值,这个特征值来自于与主成分相关联的相关系数矩阵。且按顺序分配,第一主成分与最大的特征值相关联,第二主成分与第二大的特征值相关联,判断主成分的方法通常有以下 3 种:
1. Kaiser-Harris 准则,建议保留特征值大于 1 的主成分,特征值小于 1 的成分所解释的方差比包含子单个变量中的方差更少
2. Cattell 碎石检验,通过绘制特征值与主成分数的图形,通过图形的弯曲情况,保留图形变化最大处之上的主成分
3. 通过模拟,依据与初始矩阵相同打下的随机数据矩阵来判断要提取的特征值,若基于真实数据的某个特征值大于随机数据矩阵相应的平均特征值,则保留该主成分
使用 psych 包中的 fa.parallel ( ) 函数即可得到图形,通过以上三种方法综合判断主成分的个数。
2.3. 提取主成分
通过 R 中已经包装好的算法来计算即可:
principal(r, nfactors=, rotate=, scores)
# r 是相关系数矩阵或原始数据矩阵
# nfactors 设定主成分数
# rotate 指定旋转的方法
# scores 设定是否计算主成分得分(默认为不需要)
通过以上函数,我们可以得如下的结果
Principal Components Analysis
Call: principal(r = USJudgeRatings[, -1], nfactors = 1)
Standardized loadings (pattern matrix) based upon correlation matrix
PC1 h2 u2 com
INTG 0.92 0.84 0.1565 1
DMNR 0.91 0.83 0.1663 1
DILG 0.97 0.94 0.0613 1
CFMG 0.96 0.93 0.0720 1
DECI 0.96 0.92 0.0763 1
PREP 0.98 0.97 0.0299 1
FAMI 0.98 0.95 0.0469 1
ORAL 1.00 0.99 0.0091 1
WRIT 0.99 0.98 0.0196 1
PHYS 0.89 0.80 0.2013 1
RTEN 0.99 0.97 0.0275 1
PC1
SS loadings 10.13
Proportion Var 0.92
PC 1 栏包含了成分载荷,即观测变量与主成分的相关系数,如果主成分不止一个,还会有 PC 2 、PC 3。h 2 栏指成分公因子方差,集主成分对每个变量的方差解释度。u 2 栏指成分的唯一性,即方差无法被主成分解释的比例( 1 - h 2 ) 。
这里的旋转指的是,一系列将成分载荷阵变得更容隐解释的数学方法。旋转的方法有两种:使选择的成分保持不相关的正交旋转,和让主成分变得相关的斜交旋转。最流行的正交旋转是方差极大旋转。使用方差极大旋转,可以得到如下结果:
Principal Components Analysis
Call: principal(r = Harman23.cor$cov, nfactors = 2, rotate = "varimax")
Standardized loadings (pattern matrix) based upon correlation matrix
RC1 RC2 h2 u2 com
height 0.90 0.25 0.88 0.123 1.2
arm.span 0.93 0.19 0.90 0.097 1.1
forearm 0.92 0.16 0.87 0.128 1.1
lower.leg 0.90 0.22 0.86 0.139 1.1
weight 0.26 0.88 0.85 0.150 1.2
bitro.diameter 0.19 0.84 0.74 0.261 1.1
chest.girth 0.11 0.84 0.72 0.283 1.0
chest.width 0.26 0.75 0.62 0.375 1.2
RC1 RC2
SS loadings 3.52 2.92
Proportion Var 0.44 0.37
Cumulative Var 0.44 0.81
列名由 PC 变成 RC,表示成分被旋转。通过观察可以看出,主成分对初始变量的关联程度得到了分化,第一主成分主要由前四个变量来解释(长度变量),第二主成分主要由后四个变量来解释(容量变量)
主成分得分,是用于评价不同观测之间优劣的分数。
1. 如果用于主成分分析的初始数据矩阵我们知道(可能不知道,直接用相关系数矩阵来进行主成分分析),则可以直接添加 score参数来计算每个观测的主成分得分了。
2. 如果初始数据矩阵未知,我们就没办法直接通过参数调节来得到原来观测的主成分得分了,要通过计算得分系数之后,得到主成分得分的求得公式。例:
> rc <- principal(Harman23.cor$cov , nfactors = 2,rotate = "varimax")
> round(unclass(rc$weights),2)
RC1 RC2
height 0.28 -0.05
arm.span 0.30 -0.08
forearm 0.30 -0.09
lower.leg 0.28 -0.06
weight -0.06 0.33
bitro.diameter -0.08 0.32
chest.girth -0.10 0.34
chest.width -0.04 0.27
PC1 = 0.28*height + 0.30*arm.span + 0.30*forearm + 0.28* lower.leg - 0.06*weight - 0.08*bitro.diameter - 0.10* chest.girth - 0.04*chest.width
PC2 = - 0.05*height - 0.08*arm.span - 0.09*forearm - 0.06* lower.leg + 0.33*weight + 0.32*bitro.diameter + 0.34* chest.girth + 0.27*chest.width
主成分得分:
2.4. 评价
主成分得分就可看着是各观测的主成分取值,它是初始变量的线性组合。通过得分的排名来得到观测的优劣排名。
3. 因子分析
3.1. 因子
所谓因子,指的是隐藏在数据下的一组较少、更为基本的无法观测的变量,它被认为可以解释观测变量间共有的方差。直观意义上讲,可以将观测变量视为是因子的线性组合(注意:主成分是观测变量的线性组合,容易弄混淆)。如第 i个观测变量可表示为:
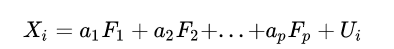
这里的Fj(j=1,2,....p) 就是我们说的因子,Ui 则指的是第i个观测变量独有的部分(无法被因子解释)。
3.2. 判断需提取的公共因子数
这里的方法和判断主成分个数相同,同样采用 fa.parallel ( ) 函数来得到图形,使用三种方法来综合判断。唯一一点不同在于,采用 Kaiser-Harris 准则来判断时,主成分分析保留特征值大于 1 的成分,而因子分析保留特征值大于 0 的因子。
3.3. 提取公共因子
这里采用 R 语言中包装好的算法来计算即可:
fa(r, nfactors=, n.obs=, rotate=, scores=, fm=)
# 相比主成分分析的 principle 函数,这里多出了两个参数
# n.obs 指的是观测数,在使用相关系数矩阵时需要填写
# fm 则用于设定因子化方法
有提取因子的方法有很多,我其实也并太了解如何选择,先知道有哪些方法,有具体项目的时候在作深究:
最大似然法( ml )
主轴迭代法( pa )
加权最小二乘法( wls )
广义加权最小二乘法( gls )
最小残差法( minres )
3.4. 因子旋转
因子旋转的选择有三种:1. 不旋转 2. 正交旋转 3. 斜交旋转
不旋转时得到各因子与各初始变量之间的相关程度,旋转之后能够使因子变得更好解释。
正交旋转
令参数 rotate="varimax" 即可,这时的因子之间强制为不相关
在提取因子后,可得到因子结构矩阵,即变量与因子的相关系数,且较不旋转的结果而言更好解释,可将不同变量重点归于某一因子。
斜交旋转
令参数 rotate="promax" 即可,这时的因子之间有可能是相关的。
在提取因子后,可得到两个矩阵:因子模式矩阵(标准化的回归系数矩阵)、因子关联矩阵(因子相关系数矩阵)。同时还需要考虑因子结构矩阵(变量与因子的相关系数矩阵),但是要通过自编函数 fsm ( ) 求得,自编函数的具体代码参考《 R 语言实战 》一书。
通过考虑以上三个矩阵,我们除了可以向不同变量重点归于某一因子外,还可以得到不同因子之间的相关系数,如果现实不同因子间的关联性很低,可能需要重新使用正交旋转来简化问题。但通常斜交旋转方法更加符合真实数据,虽然这种方法更为复杂。
通过图形显示
可通过 factor.plot ( ) 函数来得到两因子图形,可从图中观测出不同初始变量在哪个因子上载荷更大。
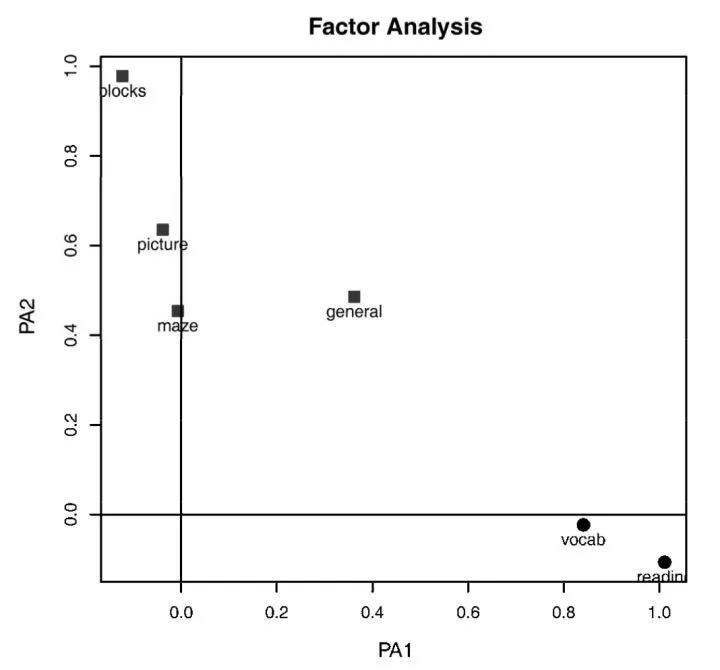
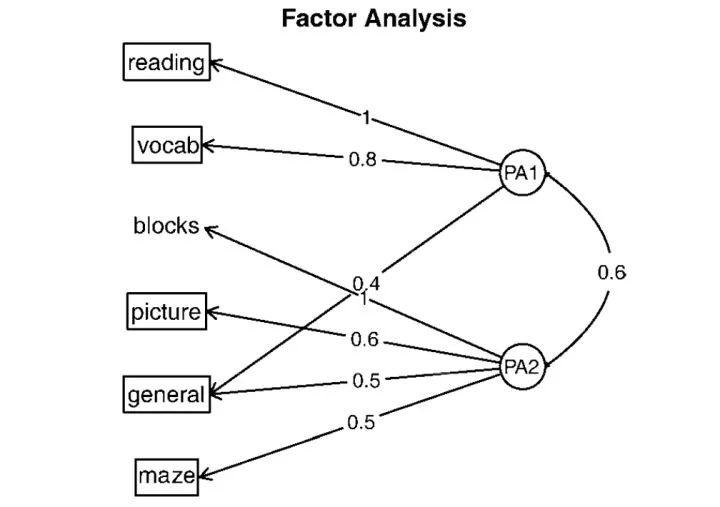
3.5. 因子得分
与主成分分析相比,因子分析并那么关注因子得分,相要得到因子得分,在提取时采用 score=TRUE 函数即可。还可以得到得分系数(标准化的回归权重),在提取因子时得分系数将会体现在返回对象 weights 元素中。
而且,这里与主成分分析不同,因子得分无法精确计算,只能估计得到。原因在于,我们的因子数总比初始变量要少,通常因子得分的估计方法有:回归估计法,Bartlett估计法,Thomson估计法。
3.6. 评价
以各因子的方差贡献率为权,由各因子的线性组合得到综合评价指标函数。
F = (w1F1+w2F2+…+wmFm)/(w1+w2+…+wm )
此处wi为旋转前或旋转后因子的方差贡献率。
利用综合得分可以得到得分名次。
4. 总结
主成分分析和因子分析的步骤可归纳为:
1. 数据预处理2. 选择模型,是主成分分析还是因子分析
3. 判断要选择的主成分/因子数目
4. 选择主成分/因子
5. 旋转主成分/因子
6. 解释结果
7. 计算主成分/因子得分

公众号后台回复关键字即可学习
回复 R R语言快速入门及数据挖掘
回复 Kaggle案例 Kaggle十大案例精讲(连载中)
回复 文本挖掘 手把手教你做文本挖掘
回复 可视化 R语言可视化在商务场景中的应用
回复 大数据 大数据系列免费视频教程
回复 量化投资 张丹教你如何用R语言量化投资
回复 用户画像 京东大数据,揭秘用户画像
回复 数据挖掘 常用数据挖掘算法原理解释与应用
回复 机器学习 人工智能系列之机器学习与实践
回复 爬虫 R语言爬虫实战案例分享



