蘑菇街首页推荐视频流——增量学习与wide&deepFM实践
害!写个这么严肃的技术话题还需要楔子么?这不是让大家放松一下嘛!毕竟是我的处女作,还是要来个看似一本正经的开场白和自我介绍的。
大家好,我是混迹于奋斗X之都——杭州的互联网大龄脱发女程序员一枚,大家可以关注我的公众号:“诗意品算法”。我会尽量保持每个月甚至每周更新一次的频率,在此立证(更新慢你也不能打我,只能用唾沫星子淹死我了哈哈)。
下面进入正题,带你领略蘑菇街有(坎)趣(坷)的从0到1的增量学习历程。
二、背景
在online deep learning炒得尤其火热的今天,我们知道,实时性就是互联网的生命和活力所在。笔者前几天跟一个阿里的朋友吃饭,朋友说,ODL现在是他们组最容易出成果的方向,众人愕然,ODL?哪篇论文里的?随即一拍大腿,原来是deep online learning。。。
试想,如果你刷抖音时,平台捕获到了你最近偏好旅行的即时兴趣,随即在很短时间内给你推荐了旅行相关的内容,你是不是会持续嗑药般地滑动下去?从而产生了心理学中所谓的无限“心流”,但我并不推崇这种类似沉迷游戏般的"心流",这种带有引号的“心流”仅仅是感官的愉悦,与精神的满足与自我的成就感无关,与至高的纯粹的甘美的快乐无关,与灵魂真正的安宁与幸福更是无关,因这并不会让你获得实质性的进步。扯远了,但这就是推荐系统实时性的作用和平台的核心诉求,即,提高用户的停留时长。你发现平台很懂你,下次可能还会再来,从而提高了平台的留存,说白了,跟开餐馆是一个道理,我们必须要有“回头客”呀!
三、何为增量学习
增量学习,顾名思义,是指一个系统在保存大部分以前已经学到的知识基础上,仍能源源不断地从新样本中学习新知识。增量学习与人类自身的学习模式非常相似,在信息化快速发展的今天,我们每天接受大量信息,有早已烂熟于心的旧知识,也有令人耳目一新的新知识,人类会在不遗忘旧知识的基础上,接收新知识,并将这些新知识消化,成为自己的旧知识。这一过程是循序渐进的。增量算法,就是每当有新增的样本时,并不需要重建已有的知识库,而是在原有知识库的基础上,仅做由新增样本引起的更新。实践表明,增量学习可以稳定提升模型性能。
四、增量学习在蘑菇街首页推荐的必要性
我们在大量实验中发现,若一天不更新模型,线上核心指标会出现肉眼可见的下降;甚至两个完全相同的模型,更新的快慢也会在很大程度上影响算法实验的效果。
下面我们用实验来验证此论述。
我们的增量学习架构中,全量模型训练n天执行一次,n>=1,增量训练每小时执行一次。每次增量训练时,都会restore当前增量对应全量版本的checkpoint和上一次增量版本的checkpoint,对当前增量样本的validation验证集进行评估。
我们可以得到每一次增量训练过程中的最优AUC(或者固定epoch的AUC),与全量版本的AUC和上次增量版本的AUC进行比较,得到离线的AUC diff。这里的AUC评估基于同一份验证集,因此完全可比。下面给出本次增量 VS 全量以及本次增量 VS 上次增量AUC的diff:
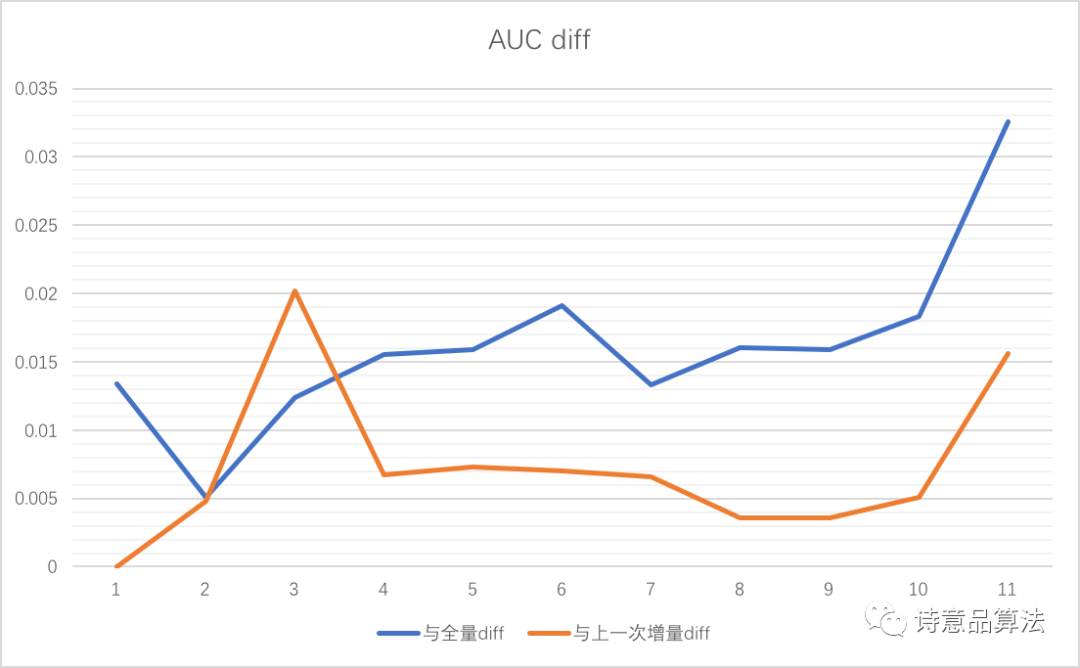
从离线AUC的表现来看,随着时间的推移,增量学习的有效性愈发明显。若两天不更新模型,离线AUC的损失高达3.5%。
五、工程实践
1、曾经踩过的坑——第一期增量实践
彼时还是落后的“解放”前,我们尚未接入精排实时打点。所有实时特征表都是从小时级别的hive表中解析并处理得到的。全量和增量训练分别对应不同的hive表,全量样本表使用天级别分区,增量样本表使用小时级别分区。增量特征既涵盖近实时特征(按小时更新),又涵盖离线特征(按天更新)。样本构建使用小时级Spark任务处理,生成小时级的训练样本。使用这种方式进行增量训练存在诸多痛点:
所有特征和样本依赖离线数据,小时级别的原始样本表依赖于小时级别的曝光/点击/事件表。
由于调度系统的不确定性和各种依赖关系的不可控,用户点击互动等正样本极易丢失。
小时级增量任务的整体链路非常复杂,需要人工维护相关的配置规则。
整个流程涉及多张Hive表之间的依赖,且依赖关系复杂。
在主表join特征表的过程中,由于小时级别的时间窗口难以对齐,不可避免地会出现特征缺失的情况。
如,新增小时特征时,需要配置两个任务,一个任务每小时写当天特征表,另外一个任务需要在第二天overwrite前一天的特征表。否则会导致当天23:30~00:30的跨天样本丢失。
数据质量无法保证,新增特征困难。
依赖的特征表需要以小时级任务写天级分区的规范来更新。
新增特征时,无法保证链路稳定性。
我们第一期采用了以下gay gay的手段规避以上问题:天级别样本join小时级别特征/设置上游正样本调度晚于负样本调度/下游延迟一小时消费数据/小时级任务写天级任务分区等等。但这些手段治标不治本,上述问题仍旧得不到彻底解决。
2、接入精排实时特征打点——第二期增量实践
线上产出的实时特征通过在线inference系统实时输出。
新增一条数据链路,消费精排打点 + 用户真实行为数据(包含曝光/点击/停留时长等)进行实时基础样本构建,样本、特征、停留时长等数据在线join后,再将实时基础样本存储到小时级分区的hive表中。
下游的增量样本构建(比如wide交叉编码)+ 模型训练沿用第一期的逻辑不变,增量处理小时级基础样本。
增量学习的全量和增量训练全部依赖于精排实时打点数据,特征构建过程中无任何join逻辑,再也无需担心各表之间的时间窗口是否对齐。
这种策略可以保证,视频和发表者的特征是实时变化的,用户的点击行为、点赞行为等也是实时的,同时,我们在一天内,会对线上模型进行多次更新。
下图为整体数据链路:
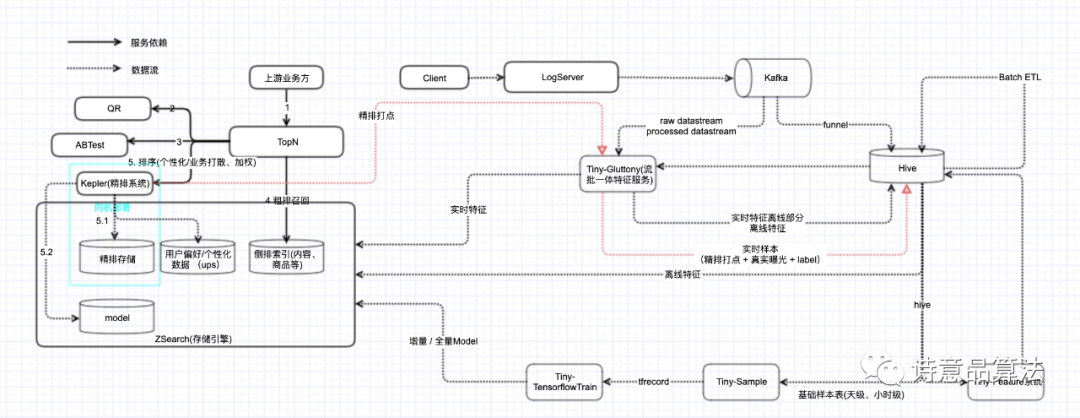
虽然第二期增量实践解决了第一期的很多问题,但第二期增量训练仍然存在一些暂未解决的痛点,多数公司为之头痛的,应该就属多路实时数据在线join导致的样本归因问题了。
多路数据包括用户行为数据(曝光/点击/停留时长事件)、特征等。
因为行为上报的天然串行性,会导致label滞后。用户曝光 < 用户点击 < 用户全屏页行为,其中,<表示早于。
一个视频的负样本(曝光)一般会先到达,后续到达的是视频的点击样本,接着是视频的互动样本(比如点赞评论分享等)。
调研了市面上的两种范式:
Facebook:负样本会先cache,等待潜在的正样本到达,若后续正样本到达,则只保留正样本。由于等待时间可能长达10min之久,因此实时性会有损,但是准确性会有保证。
Twitter/爱奇艺的做法:两条样本都会保留,都会去更新模型,这样实时性最高。比如,在观察到一个实例的正样本到达时,除了使用正样本进行梯度下降之外,还会对相应的负样本进行反向梯度下降,抵消之前观察到的FN样本对loss的影响。其实是对loss做了修正。
我们在实践中采用Facebook的处理方案:
精排打点的数据,并不会全部曝光给用户,因此精排打点的数据需要与真实曝光数据进行join,得到基础曝光集合。
基础曝光集合会在固定窗口内等待label数据,到达等待的时间后,会与label进行join(无论是否等到),得到最终的训练样本集合。
3、一些细节干货
全量训练与增量训练的协同:
每次启动增量样本构建流程时,会自动拉取从上一次构建完的样本(打结束标)到当前时刻的所有样本进行构建。同样的,每次启动增量模型训练时,会捞出所有迄今为止未训练样本对应的增量版本,统一在当前训练流程中进行训练,避免出现样本被漏训练的情况。
全量模型训练与增量模型训练并非同一任务,因为其超参和配置不同。每次全量模型训练完成后,所保存的模型checkpoint路径以当前全量任务命名,增量模型训练无法reload全量任务下的ckpt(任务id无法互传)。如何打通全量与增量模型训练呢?我们在每次完成全量模型的训练后,将全量ckpt拷贝到增量任务所在目录下。注意,copy操作只允许chief节点操作,因为在分布式框架下,若worker快于chief完成训练,并在export模型后执行copy操作,可能会导致chief节点的ckpt保存出现异常。
六、算法实践
1、wide + 增量学习
在大规模wide模型的基础上,全量连续类特征/点击序列pair对的频次过滤条件不一定适用于增量连续类特征/pair对的频次过滤条件。
比如,全量时,某些pair对的频次过滤数量设置为1000,但在增量时,应该设置得小一些。全量时,使用天级别积累的样本进行训练,但在增量时,则使用1小时内的样本进行训练,若仍然使用与之前全量相同的频次过滤条件,会过滤掉近1小时内频次不足1000的特征,即使在后一小时内,这些特征的频次增加到1000,也无法再追回已训练样本中的这些缺失特征值。
解决方案1:全量时,使用一定的阈值过滤低频样本,增量时,为了保证不会误过滤增量中的某些有效特征,我们使用全量1/2甚至1/3的阈值过滤增量中的低频样本,从而降低某些小时级别低频但天级别非低频特征的准入门槛。
优点:可以避免过滤掉某些有效特征。
缺点:这种过滤会带来另外一个问题,频次太低的特征学出的权重不够置信。
解决方案2:构建样本时,之前在全量样本构建过程中被全量阈值过滤的特征,其频次会被保留,等到下一次增量到来时,若全量中被过滤的这些特征再次出现,则会将全量+当前增量的频次作为当前特征的频次。即,某个特征的频次达到准入门槛后,才会进入模型训练。
优点:可以解决本次样本中的特征由于频次过低导致学出来的权重不够置信的问题。
缺点:仍然会过滤掉某些低频特征,损失一部分有效信息。特征在达到准入阈值之前,出现的前n次都被忽略了。
解决方案3:在蚂蚁金服的在线学习策略——流式频次过滤的基础上,做了一些优化改进。我们称之为基于FTRL的动态L1正则策略。这部分的详述将在第2部分呈现。
2、动态L1正则
对于增量学习来说,降低regret和提高sparsity是我们的重要努力方向。而稀疏性是算法追求的重要特性,随着模型复杂度的升高,其所需的存储、时间资源也随之提高,稀疏模型则会大大减少预测时的内存和复杂度。我们的优化策略正是基于常见的稀疏性优化算法FTRL实现的。在经典的FTRL实现中,所有特征的L1正则参数都是一致的。过大的L1正则系数虽然可以过滤大量低频特征,但由于约束太强,导致部分有效特征也被lasso,影响模型性能。在我们的样本中,大部分特征都是极其稀疏的(尤其是pair对特征)。这种对特征出现频次进行计数,只有达到一定阈值后再进入训练的设计方案会破坏样本完整性,如全量频次24,增量频次1,阈值过滤25,则该特征出现的前24次都被忽略,仅会训练该特征出现的一次,导致模型训练的稳定性差。
我们参考蚂蚁的实时流技术,希望使用特征频次影响L1正则系数,使得不同频次的特征有不同的lasso效果。特征频次和参数估计的置信度相关,特征出现的频次越低,置信度也越低。因此我们在纯频率统计的基础上增加一个先验分布(正则项),频率统计置信度越低,越倾向于先验分布,相应的正则系数也会越大。
实现:
动态L1正则公式,这里借鉴了Momentum中的指数加权平均思路,同时考虑当前频次和历史频次总和的影响,使这两个变量同时影响增量模型训练,历史频次在公式中的系数略低:freq(t) = sum(freq(0, t-1)) * alpha + (1 - alpha) * freq(t)。
整体公式:L1(wi)= L1(wi)(1 + C * max(N - freq(wi), 0) / N),freq(wi)是当前特征的真实出现频次(包含当前增量中出现的频次以及历史总频次),从增量样本构建传给增量训练的hdfs文件里取。C是惩罚倍数,全量和增量时均设置为1.5。N为特征最低门限,全量时设置为1000,增量时设置为100。(均是参考值,超参可调)
修改tensorflow底层ftrl优化器代码(C++实现):
将FTRL优化器中的L1正则标量改成向量的形式,每一维特征对应不同的L1参数。
不同特征对应的L1参数是在tf训练时,通过样本构建产出的特征频次计算得到的,在声明FTRL优化器时传入。
注意:由于wide参数矩阵(feature_size, 1)是按照mod方式进行embedding_lookup的,因此W tensor对应的L1正则参数矩阵(feature_size)也需要按照mod方式重新排序,保证传给FTRL优化器的W矩阵和L1矩阵是一一对应的。
效果:动态L1策略相应的模型规模(大小)减小了34%。同时,模型的稀疏度从78%下降到71%,共减少了9%左右的特征量。动态L1策略应用在wide侧时,过滤了大部分不置信的pair对连接,可大大减少由连接噪声产生的badcase。同时减小了过拟合的风险,提高了模型的泛化性能。
3、FM/Deep + 增量学习
对于FM/Deep与增量学习的结合,淘宝搜索模型已有一些探索。他们“将模型权重按照sparse的程度分为三个部分,分别为freezing embeddings,changing embeddings和changing weights。其中,freezing embeddings对应模型中的high sparse embedding如user_id、query id、item_id。changing embeddings对应其余embeddings,如user profile embedding、商品品牌embedding、商品统计特征embedding。changing weights对应模型中的所有MLP部分权重。” 搜索大模型包含Embedding和MLP,embedding包含一些high sparse的id特征,比如itemid,其数据规模之大,是无法进行纯实时更新的。加之embedding参数需要充分的数据才能学习充分,未充分学习的结果就是模型在当前样本上过拟合且在未来样本上缺少泛化性。因此阿里采取固定high sparse embedding,实时更新MLP参数的方式进行模型训练。
但是这不适用于我们的推荐场景。阿里的电商搜索场景不需要更新id embedding,是因为:1)上新商品无需实时展现给用户;2)流量充足,上新商品可以进行充分EE后再透出;3)物料池子足够大,丰富度有很大保障。视频推荐系统则不同,推荐系统的新发表物料需要尽快曝光给用户,无论从用户还是发表者的角度来看,这点都极其重要。当天的新发表内容在上述的增量更新方案下,几乎无法出现。
我们目前的FM/Deep embedding仍然照常更新,但其是否能进入训练的准入门槛,由其对应id出现的频次决定。对于deep部分的训练,我们也采用与动态L1正则类似的技术。
4、wide / FM / Deep的频次过滤初始值设置
需要注意的是,同样是序列的频次过滤,wide和fm/deep的频次过滤阈值完全不同。我们的平台支持对每个序列设置不同的频次过滤阈值,即在当前序列中,某个特征出现次数的最低准入门槛。wide侧,用户点击序列与当前待排内容组成了pair对。而fm/deep侧的点击序在编码时,均是单侧的,无交叉,某视频可能在这批样本里的点击序中出现了100次,但在当前样本曝光中只出现了一次,我们将这种特征加入训练,无疑是非常危险的。同一序列特征,在wide侧是经过交叉后再编码的,在fm/deep侧却是直接编码的。因此,fm/deep侧的频次过滤阈值要远远大于wide侧的。这是一个宝贵的经验。如果fm/deep侧点击序列的频次过滤阈值设置得过小,会导致线上效果变差。
七、未来展望
目前我们使用实时样本进行流式训练,部署流程仍采用全量模型切换的方式,时效为小时级。后续我们将会探索流式训练和实时更新结合的方式,同步探索样本归因的有效解决方案。wide & DeepFM + 增量学习已经在蘑菇街成功上线,我们进行了长达10天以上的AB对照实验。相比于基线,增量学习实验上的效果累计提升:人均曝光和人均点击10+%,UVCTR5+%。用户停留时长和浏览深度也有10+%的提升。
感谢组内优秀小伙伴的支持:未闻、厚朴、阳明、浮尘、无羡等。
参考:



