一条妙计确保你的AI模型总是有帮助

作者 | 栗峰
编辑 | 唐里
当我们在讨论温度的时候,我们不会认为自己扔掉了大量的信息。如果我问某人外面有多热,他们开始列举各种空气粒子的位置和速度来说明,那我会赶紧走开。
现实是,作为人类,我们对“能提供充足信息”和“有用”之间的区别有着与生俱来的理解能力。我们会告诉别人外面很热,但不会说它的温度是38.94摄氏度,这样既不麻烦又能说明问题。这种删减和总结信息的行为是预测的本质,在本文中,我将解释如何定义、度量(近似)和利用这一过程来改进预测模型和人工智能(以及在预测天气这样的问题中给出正确的答案)。
1.玻尔兹曼对熵的理解
没有什么比一个好的理论更实际的了。
- 路德维希·玻尔兹曼
如果你熟悉熵的概念,你可能已经了解了其中一两个系统的定义(例如热力学熵,信息熵,等等)。不然的话,别人会告诉你它其实是一种“随机性”的衡量标准(定义随机性是另一个主题)。
我认为熵的定义有很多种,所有这些定义描述的都很详细,在不同的情境中都多多少少有用(尽管我通常反对将其称为是一种“随机性”的衡量标准)。我最喜欢的定义之一,最早是在1875年左右由天才路德维希·玻尔兹曼(Ludwig Boltzmann)提出的,现在通常被称为玻尔兹曼熵或是玻尔兹曼熵公式。
玻尔兹曼认为,熵与微观状态和宏观状态之间的关系直接相关。对于系统给定的任何宏观上的描述,如果能与更多的微观状态下的描述相结合,熵就会更高。这个理论最初提出的时候是用来描述容器中的气体例子的,在这个情境中会比较容易理解它的含义。
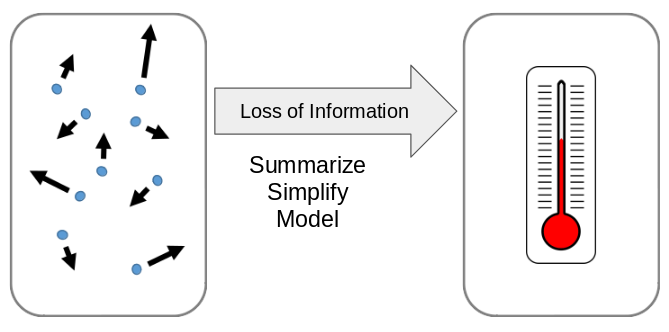
图2:摘要中增加了熵,并创建了方向性
在左侧,这个系统的微观状态被定义为:容器中所有气体粒子的速度、质量和位置(这是非常具体的描述)。相反,在右侧,将微观状态概括为温度,就产生了一种可能的宏观状态(这个描述就不那么具体了)。在宏观状态下有一些非常有趣的特性:它是不可逆的(你不能只根据温度这一个条件就对所有粒子进行完全描述);它不那么复杂(信息少所以得到的结论也少);但它仍然是准确的(容器真的是38.94摄氏度);最重要的是,它不太具体(不止一个微观状态适合它)。
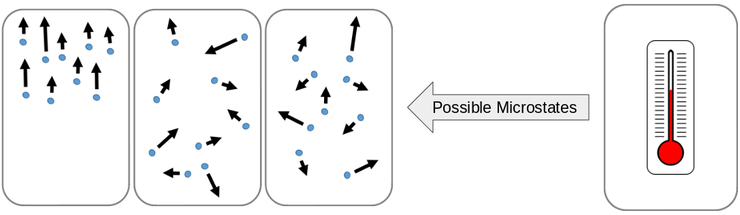
图3:给定的宏观状态将具有多个与其兼容的微观状态。
这就是玻尔兹曼熵的关键:每个宏观状态都有许多与之兼容的微观状态。定义温度的方式意味着显示在左侧(上图所示)的三个容器中的任何一个都会产生相同的温度。这种微观状态越多,熵就越大:“这个容器的温度为38.94°C”。
尽管温度这个条件很普遍,但它并不是玻尔兹曼熵唯一适用的方面。任何人与人之间的对话中都包含高熵语句,人们会仔细选择具有描述性的语句,同时也不会太过具体。例如,我可以将这篇文章的缩略图描述为“一副内容是蒙娜丽莎的剪贴画,可以重复使用”(它确实是这样的)。但是,假若你还没有看到这个特定的图像,那么这些微观状态中的任何一项都可能同样适合该宏观状态:

图4:所有这些都可以对应“一副内容是蒙娜丽莎的剪贴画,可以重复使用”。
经过这个例子的说明,很明显可以看到,熵可以出现在意想不到的地方,但到目前为止,我们还没有采取任何措施将其与AI或预测联系起来。在此之前,我们先来聊聊地图。
2.地图中存在的问题
“以猫为例,猫最好的物质模型是另一只猫,或者说最好是一只完全相同的猫。”
- Norbert Wiener,科学哲学(1945)
我们来做一个小小的思考实验。 想象一下,我问你去多伦多那个奇怪的新加菲猫主题披萨店的路线,但我们俩都没有手机,我只有纸和笔。如果你知道怎么走,那你可能不会犹豫,你画出来的地图看起来会像是这样:
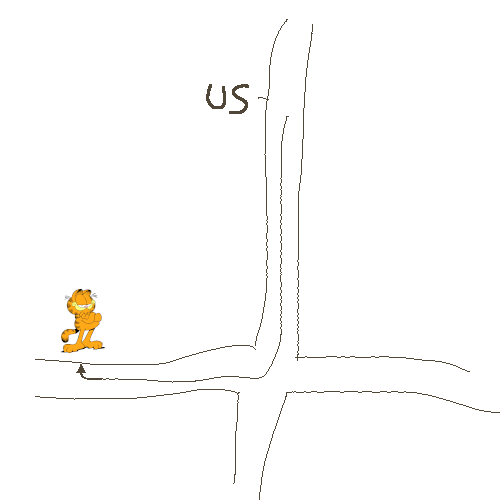
图5
对我们俩来说不好的一点的是,我很容易被搞糊涂。我必须继续询问:“北是哪边?”
你只能郁闷的叹口气并继续补充
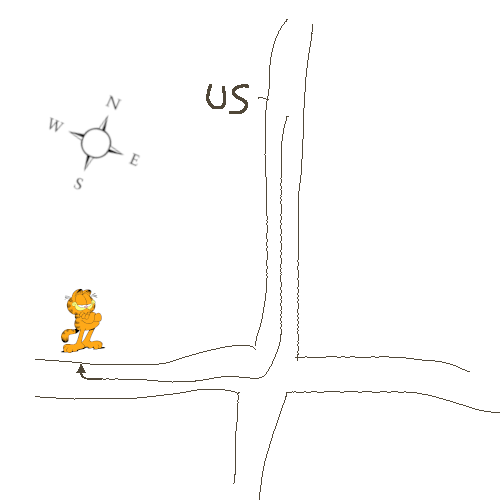
图6:我想这些已经画的已经够多得了
你可能已经能看出来这是什么意思了,但我还在要求更为详细的说明。直到最后,你的地图看起来很可能会像这样:

你为了让我了解清楚儿增加了很多的细节,但其实其中的绝大部分都是毫无意义的,地图的意图是引导我去吃美味的千层面披萨。事实上,如果我们继续这样下去,我们最终会意识到,一份最准确、最具描述性、最完整的觅食地图其实就是整个地区的一比一复制品,餐厅里面也坐满了急急忙忙吃东西顾不上说话的人。如果你要靠地图来导航,那地图里的信息需要比真实地区的信息少一些。如果这张地图和这个地方本身的熵值是一样的,那么对我来说没有任何帮助。
模型的实用价值介于完整的描述和抽象的草图之间。如果你不相信我,只需看看多伦多市的地图和多伦多的地铁图上显示的内容有什么不同:

图8
如果把地图上显示的路线做一些扭曲,把一些路线多重叠交叉了那么几次(改变了拓扑结构),那么它就不再是一个有用的工具了。然而,以正确的方式扭曲它,忽视关于尺度和距离的信息,地图将会变得更加有用,可以快速了解在下车前剩下多少站点。在对系统进行建模时,它应该包含尽可能少的细节,以便能最大限度的达到预期目的。
[我强烈建议你在Twitter上使用@mapTOdotca,如果你想要了解地图的话]
3.天气的状况
预测是困难的。尤其是关于未来的预测
-Niels Bohr
你对明天的天气做出的最准确的预测是什么?当那个重要的日子(明天)来临的时候,什么样的预测最有可能实现。
天气晴朗,最高温度27°C,最低温度18°C,伴随涨潮和海洋变暖
下午2时至4时将有2mm的降水。
气温会比昨天有所上升
以上全部
当然,这个问题的答案取决于你对天气的了解,以及随着时间的推移天气它会如何发挥作用,但如果你没有任何预测天气的能力,你最好的选择是选项#3,即气温会比昨天有所上升。与其他预测相比,这一预测具有很高的熵。会有许多天气的微状态与“气温比昨天有所上升”这个预测相兼容。
如果你尝试预测天气,并不一定需要低熵预测。如果你在考虑是否应该带雨伞去上班,你只需要知道今天是否会下雨。如果你在耕作,你可能需要更少的熵:那里的总降雨量是多少?
在所有这些不同的天气预测例子中,有一点是不变的,预测总是需要比用于生成预测和/或模型的高度详细的数据具有更多的熵。
4.总结谬误
混乱是一条阶梯
- Littlefinger
每当我开始建模的时候,我首先花一些时间尝试把我的问题都按照详细程度在一个梯子上从下到上列出来。我这么做的原因是为了避免陷入总结谬误:相信你做出的有用的预测的熵和你的数据的熵在同一水平上。要避免这个谬误只需要一条规则,它不困难,但是很有用:总是向梯子的上方做预测。始终在比用于生成预测的数据更高的熵水平上进行预测。
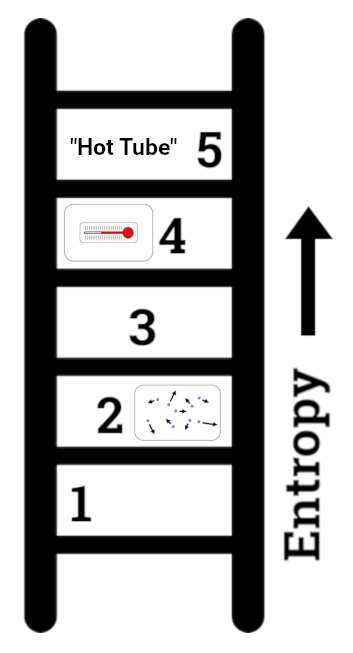
图9
现在,在我自己的日常生活中,这通常与预测小分子药物和蛋白质之间的相互作用有关。如果我说来自高分辨率晶体结构的详细结构数据是我在1级的输入数据,那么我可以用它来构建能够预测更高层次的东西的模型。这些信息非常详细,它描述了蛋白质和药物相互作用时所有原子的位置。
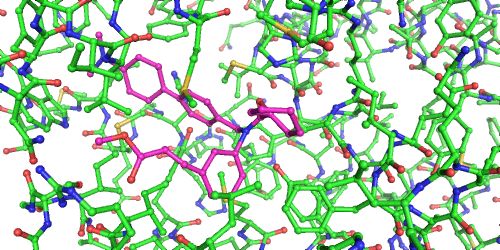
图10:如此美丽的低熵蛋白质和药物结构,药物结构用粉红色来表示。
我预测的内容比较少,例如:小分子药物X与蛋白X相互作用吗?这类似于使用关于粒子的详细信息来了解温度与容器处于“热”或“不热”之间的关系。这样,在未来,如果我给我的模型设定一个温度,它将预测“热”。在这种情况下,我的模型只是预测“是的,这种药物会以某种方式与这种蛋白质相互作用。”如果我想设计一种更好的药物,这个二元预测对我来说仍然是有用的,但它还不够详细,无法重建特定的原子用以预测交互的细节。如果我的模型那么做了,那我是不会相信的。一般来说,你只应该爬上梯子,而不是再次退下来进行预测。这就是总结谬误。
5.最后的思考
“所有的模型都是有错误的,但其中有一些是有用的”
- George Box
如果你像我一样,会花很多时间来考虑自己的模型,或者尝试使用和理解其他人的模型,那么我希望你发现的东西是有用的。最重要的是要记住,即使目前在大肆宣传的人工智能和机器学习,人工智能仍然是有局限性的。理解和尊重这些限制条件并不会阻碍你,相反,它会让你专注于真正重要的事情:什么对你有用?
顺便,记得天气预报要做简单一点。
原文链接:https://towardsdatascience.com/when-is-ai-trustworthy-when-is-ai-useful-215aaee24a6f
拓展阅读:The User Illusion by Tor Nørretranders(文章链接:https://www.penguinrandomhouse.com/books/330619/the-user-illusion-by-tor-norretranders/9780140230123)其中定义了一个叫“exformation”的概念。
更多内容
专访俞栋:多模态是迈向通用人工智能的重要方向
「LSTM之父」 Jürgen Schmidhuber访谈:畅想人类和 AI 共处的世界 | WAIC 2019
历年 AAAI 最佳论文(since 1996)
一份完全解读:是什么使神经网络变成图神经网络?

阅读原文 查看更多论文~





