八位AI学者论道:下一代机器学习的应走之路

来源 | 智源社区
作者 | 周寅张皓
机器学习在发展的过程中,经历了许多次转折和变化。从最初的符号主义专家系统,利用结构化的知识辅助机器预测,到统计学习方法的出现。2006年以后,更是由于以深度神经网络为代表的联结主义的兴起,使得机器学习迎来了蓬勃发展的时期。
但近年来的多项研究表明,第二代机器学习技术仍存在很多问题,在诸如图像识别,对话,语音识别等领域,现有模型能达到很好的效果,但模型的泛化性能有限,这体现在训练与测试之间误差的巨大差异、模型的鲁棒性、以及跨领域或问题的通用机器学习算法的空缺,引起了人们对下一代机器学习的思考。
近期,在智源研究院成立两周年之际举办的“智源论坛2020”中,由八位来自不同研究背景的智源学者交叉互动,对下一代机器学习应走之路,进行了激烈且深度的探讨。
机器学习方向:林宙辰、王立威、颜水成、张长水、崔鹏
智能信息检索与挖掘方向:徐君
体系架构方向:孙广宇
认知神经方向:方方
整个研讨分为两部分,首先由北京大学教授林宙辰做引导报告《下一代机器学习》,随后八位学者围绕多个问题进行辩论。
1
下一代机器学习
在林宙辰教授的报告中指出,当前深度学习红利已经接近终点,下一代机器学习会是什么成为亟待思考的问题。目前有不同方案,例如张钹院士等人提出的“认知+符号”,Y.Bengio 等人提出的“System 1+System 2”,M. Jordan 则认为根本不需要新的算法,只要有市场推动即可。目前为止,这仍然是一个开放问题。
我们下面看一看林宙辰教授分享的详细内容:
林宙辰:深度学习、机器学习已经很少听到有突破性的进展了。去年三大巨头获得图灵奖,马上有人跳出来说“某个领域获得图灵奖就表明这个领域已经走到尽头了”;我们也体会到近一两年来,深度学习重大进展好像就没有了,大家只能想方设法去充分利用算力。
因此,我和许多做机器学习的学者都在想一件事情:机器学习下一步应该是什么样子?
这是我们今天要讲的题目。我们需要回答两个问题,一个是,它应该是什么;另一个是,我们应该怎么能够达到它。首先得有目标,其次得有途径,才是完整闭环。为了不让这个讨论过于偏离,我们给“机器学习”下了这么一个定义:
Machine Learning is about designing algorithms that can learn and construct predictive or descriptive models from data.
机器学习是一门用来设计算法的学科,这些算法能够从数据中构造预测和描述模型。
从这个定义出发,已经限定了数据是不可或缺的,如果什么都是人教给它,那么我们就不认为它是机器学习的范畴。其次,如果它本身不是一个算法,那么也不属于机器学习范畴。当然,你可以不同意我这个定义;我们把这个定义给说好,可以减少在交流上的误解,否则大家谈得都不一样,就很难达成共识。
我在市面上找了现有几个比较有代表性的工作给大家介绍。后面大家可以提出各位自己的观点。
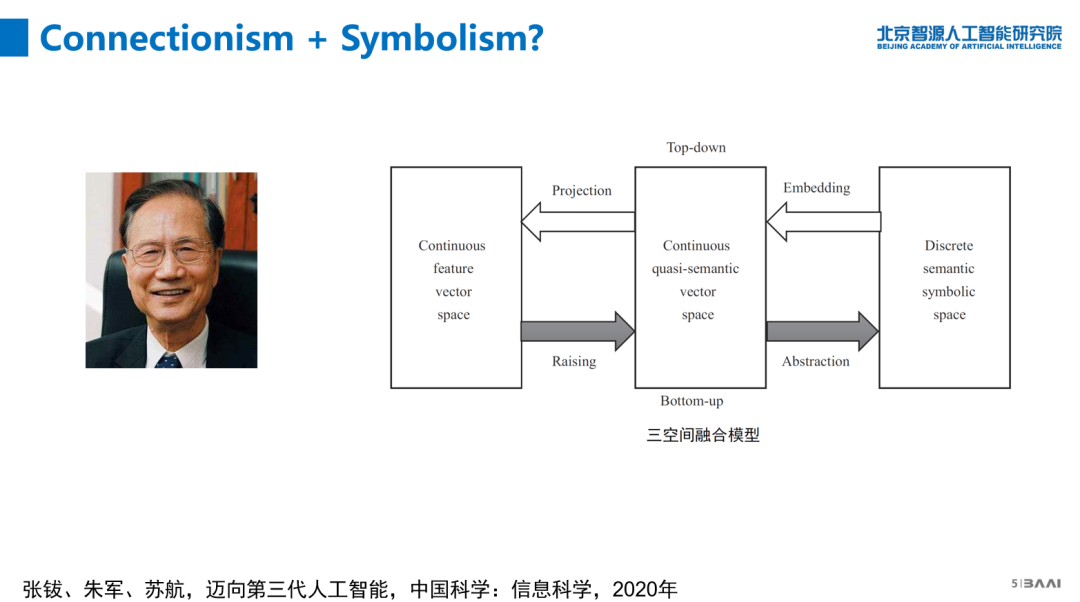
首先,连接主义和符号主义的结合。前两波人工智能热潮分别由符号主义和连接主义主导,现在把它融合在一块是最直接的想法,有代表性的像张院士、周志华等是这么认为的;国外也有很多专家这么认为的。但怎么走,没有定论。
张院士近期在《中国科学:信息科学》上发表的文章提出“三空间融合”的模型,连接主义是完全在连续空间里,用feature等进行计算;符号主义完全是在离散空间进行计算。直接串通这两个领域有困难,所以他提出加个中间层,在中间进行计算,把计算结果返回两头。做个类比,相当做机器翻译时,中文和英文不能直接翻译,就都转到日文上面;这可能不是非常准确的类比,但道理是一样的,插入一个中间步骤,让难度下降。

深度学习的三巨头是非常坚决的连接主义者,他们拒绝神经网络需要别的东西帮忙,认为下一代机器学习就是下一代深度学习,只要把神经网络性能推到极致,一定能解决问题。
Bengio 根据人的认知系统提出两个系统:“系统1”是专门针对感知觉方面的,这是现在深度学习所做的事情,这挺有意思,但完全说不清楚,所以深度学习也解释不清楚;系统2是对应于人的逻辑那部分,他认为未来深度学习要解决的问题,尤其是要探讨注意力机制,此外还有意识方面的问题,再扩展现在深度网络的功能,他认为能够完成人的逻辑功能。

第三个是M. Jordan的观点,他认为机器学习已经发生了三代,第四代机器学习则是要跟市场结合在一起。
在他的PPT里是这样说的:在第一代机器学习(1990-2000)下,产生了重要的应用,例如欺诈检测、恢复、供应链管理等。之后每隔十年产生新的一代。他认为第四代机器学习的理论不用去设计,而是根据应用去驱动它就好了,它自然就会产生新的机器学习理论出来,而应用这块则需要跟经济学方面要更多结合。
关于怎样达到下一代机器学习,大家都在想,要跟其他领域结合,例如认知科学、类脑计算、量子计算等,而不要自己关起门来造车,要从其他领域获得新的思想、养分之类的。还有一个大家特别头疼的事情,是不是“数据+算力”就能解决问题,我们后面可以进行讨论。

很多同事认为AI跟cognition要关联,这个问题不大,戴院士在中国人工智能大会上说他要对人脑进行全面建模,甚至进行扫描,有点接近黄铁军教授的还原主义的思想,但是他中间多加了两个桥梁,这样方便通过一步步过去。
类脑现在也是很有可能的。冯·诺依曼的体系是存算分离的,有些运算在冯·诺依曼这个体系上面很不容易实现,但有可能在类脑芯片上面却比较简单。《Nature》上写的关于类脑图灵完备理论,我不是这方面的专家,不太了解类脑图灵完备和通常图灵完备有什么差别,如果有本质差别的话,有可能在类脑的平台上面设计算法,会有什么质的变化?也有一些理论认为人的智能跟量子是不可分的,“顿悟”之类是脑里面的细胞涌现出新的idea,这点我不是特别了解,值得大家共同探讨。
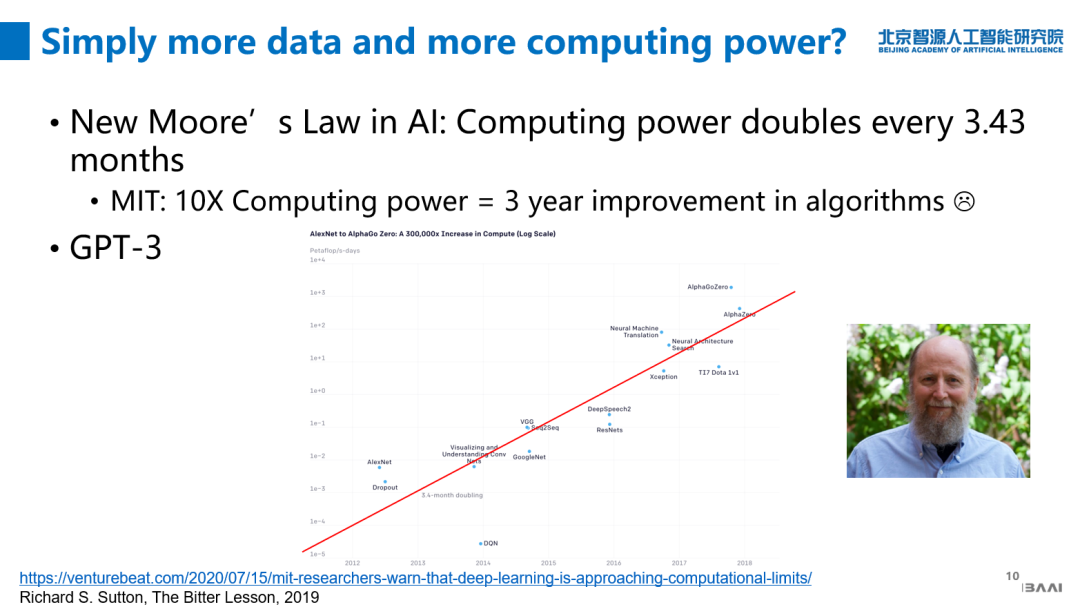
关于堆数据和堆算力。今年有一个数据调研公司提出新的AI界的“新摩尔定律”,说AI算力每3.43月会翻一倍,呈指数增长。MIT 做了进一步的延伸,说每增加10倍算力就等于研究者在过去3年算法上所改进的效果。所以,单纯增加数据和算力是否可以取得人的智力上的贡献?
强化学习的鼻祖 Richard S. Sutton 在去年写了一个博客,对人工智能近70年进展感到非常悲观,他说这些进展都是算力引起的,不要以为算法在AI里面会起什么关键作用;人的算法在里面可能会起一定作用,但是并没有直接提升算力作用这么明显。今年GPT-3横空出世,直接把参数上升100倍,性能上马上有了质的变化,这好像也迎合了这个思潮,因此,是不是单纯堆算力和数据就能解决问题?
下面请各位学者来探讨。
2
可能路径探讨
由于现场辩论非常激烈,智源研究院将整场辩论中的核心观点整理如下,供读者参考:
1、下一代机器学习的路径设想
依图科技CTO 颜水成博士认为,我们需要考虑如何利用现有的资源最大化应用。
在现有的能力基础上,应尽最大可能地将机器学习应用到各个领域中去,从这个角度来说,是比较接近加州大学伯克利分校教授迈克尔·乔丹(Michael Jordan)思想。具体来说可以将不同场景下的数据尽可能多的拿过来,然后利用当前算力获取尽可能好的性能,接着考虑落地与转化,实现科学技术对社会的服务。
中国人民大学徐君教授更为支持联结主义与符号主义相结合的观点,他认为,当前的人工智能还处在一个“暴力美学”的阶段,即“大数据+算法+大算力”,可以得到很好的实用效果。但是,长期来看,还需要结合脑科学,将符号主义和连接主义融合。当前,最大的困难就是还没有一个很好的数学工具,能够同时进行数值和推理运算。一旦在这方面有所突破,将会比“暴力美学”产生更大的影响力。
有学者对于畅想第三代机器学习保持怀疑态度:
北京大学王立威教授提到一个说法:凡是“什么什么下一代,什么什么2.0/3.0”,都是想跟以前不一样,但又不知道该怎么做。他认为“(这些都是)先做出真东西来,然后再回头来看出来的。”
北京大学孙广宇教授从事硬件的设计工作,他表示对未来技术的发展非常矛盾。一方面期待有更好的东西做出来;但另一方面,新的方法需要新的架构设计,意味着他以前的工作需要推倒重来,这又令人十分担心,因此希望下一代能有一个可以自适应的硬件架构。
清华大学崔鹏副教授提出了较为综合的观点,认为需要结合上述三位专家的观点来设想未来的可能:
崔鹏认为,上述AI专家的观点都对,只不过他们是从不同的维度来谈的。具体地,张钹院士的“符号主义+数据驱动”是从人工智能的实现路径来谈的;图灵奖得主Yoshua Bengio认为第一代推理能力可能比较强,第二代里面感知和学习能力比较强,因此希望第三代具备“感知、学习、抽象、推理”的能力,他是从人工智能的能力层来谈的;而加州大学伯克利分校教授 Michael Jordan 是从人工智能的应用层来谈的。三个人从三个维度来谈,因此我们应该把他们的观点拼起来,组成一个未来10年、20年的图景,但是具体下一代应该怎么划分,大家应该选一个问题,现在没有一个公认的维度,只有做出来才能清楚。
2、怎么看待类似GPT-3的“暴力美学、大力出奇迹”?
部分学者对GPT-3代表的暴力美学保持乐观
颜水成认为大力出奇迹能够解锁机器学习(比如人脸识别)的应用场景,让大家清楚的知道,哪些任务可以做到什么程度。这样,也为科学家提供一个很好的标杆,让他们能够设计更好的算法来达到极致。
他提出,突破并不一定在方法。只要要就对当前效果有促进就是好的;如果一味埋头苦干解决当前的所有问题,那可能等目标实现了,产出的东西已经不满足那时候的需求了。所以,能对社会有一定价值、一定用途,就应该鼓励。
清华大学张长水教授认为大力出奇迹,花那么多钱,敢想敢干,挺不容易的。不同的人,在动不同的脑筋,在以不同的方式来尝试,因此对未来持乐观态度。
另外的学者持中立态度
崔鹏提出,如果在产业界的话,那大力出奇迹没有问题,应该鼓励支持;而如果在学术界的话,应该强调学习能力,而非计算能力。具体地,学习能力指的是在有限的数据集下,利用数据的深度。
论坛更多的讨论则对算力堆积的模型提出了批评和意见
孙广宇觉得硬件算力在未来一定是可以支持”大力“的,但是他也指出,互联网大数据往往价值密度很低,即使有很大规模的数据,也不一定能有很高的价值,在智源做项目的时候经常碰到这样的问题,即使”大力“也出不了奇迹。而且现在算法发展也很快,对计算资源的需求远超摩尔定律的增长速度,因此某一天它没办法靠纯算力,之后就不能再靠“大力”推这件事情,那个时候做体系结构的人的春天要来了,聪明的人可以设计新的,抛弃冯诺依曼体系的东西,体系结构和算法设计可以同时向前推进。
崔鹏认为所谓的暴力美学,就是用“大数据+大算力”来尽可能让算法的性能达到极致;而真正的智能,需要有新的学习模式,能够从少量样本中学习,获得数据背后本质的规律,这样才能让机器获得更好的泛化能力。徐君教授赞同了崔鹏老师的观点,认为如果仅仅依靠大数据,大力出奇迹,是超越不了已有的知识或模式的;而如果能够利用规则,也许会超越人类已有的知识积累。
王立威举了一个例子,AlphaGo的成功得益于有大数据和大算力,并随即抛出一个问题:暴力美学、大力出奇迹,能不能走出计算机的范畴?很多实际的场景,比如robot与客观世界互动,需要遵循客观世界的物理规律,短时间内是得不到大量的数据的,这样就无法使模型充分学习。因而,更倾向于方法上的创新,能够从相对小的数据中学习(小样本学习)。
北京大学方方教授从脑科学、认知心理学的角度提出了两个观点:第一,人类大脑存在大量抑制性网络,这对人的感知、理解、决策起很大的作用。而将抑制性网络嵌入到人工神经网络中却很难。第二,目前设计的人工神经网络,参数量非常大,依靠大算力将耗费大量能量,这在将来是不现实的。人类那么多神经元,一般仅有2%~3%的神经元被激活,而我们仅仅需要吃二两饭就足以支撑。因此一味增加神经元和参数与人类的智能背道而驰。
3、不同领域之间该怎样有效交流,促进人工智能更好的发展?
徐君从信息检索的角度思考,认为未来需要更多的考虑输入输出的因果关系。当前的检索系统还都是判断相关性,而相关与因果并不等价,因此导致了很多问题。认为未来可以引入因果方面的研究,且信息领域可以方便地对用户进行测试,而不必担心伦理问题。北京大学智能科学与技术系林宙辰教授认为徐君教授的观点很好,未来的AI应该会更侧重人机交互。
张长水认为,通过不同的方向探索,结合,最终会生成一定的指导思想。机器学习是一个大家庭,研究者需要和领域结合、需要和问题结合、需要和认知结合,和做检索的、做语言的、做图像的、做医院的结合,从中发现真的问题所在,但大家都是做机器学习,但是侧重点不同,这样的研究多了,就会慢慢形成一些规律或指导原则,我们需要更多人去做不同的结合。
方方指出人类的认知过程中,大脑的功能是分块的、固化的。但是,实验发现:通过大量的训练后,大脑的功能区是可以发生变化的。很多神经元是万能的神经元。这给设计通用网络带来启发,我们需要做这方面的结合。
4、机器学习的下一个“Breakthrough”会由什么样的方式产生?
王立威的观点是:大力出奇迹出不了Breakthrough 的成果,因为它在方法上并没有本质的创新,而是在已有原理的基础上,通过工程的手段来达到极致性能。学术界还是要有一些人来坐冷板凳,去做一些基础性的研究。
崔鹏认为,我们首先应该明确breakthrough的定义。如果GPT-3算是一种breakthrough的话,那机器学习的下一个breakthrough一定是来源于大力出奇迹。如果是理论上的才算是breakthrough,那很大概率来源于学术界。
孙广宇将机器学习的发展类比芯片的发展,一个是工艺,一个是架构,有点像机器学习里的算法和算力。其实,这两条路线都可以走,互有裨益,边走边看。

点击阅读原文,直达NeurIPS小组!





