【沙龙干货】主题二:一个用户行为分析产品的设计与实现

讲师简介
曹犟,神策数据联合创始人,CTO,清华大学2002级计算机系本科,2006级硕士。2008年至2014年就职于百度,先后负责/参与了百度知道的问题个性化推荐、百度日志处理平台、百度用户行为分析平台、百度统一用户画像(User Profile)、百度用户数据仓库(User Data Warehouse)、ID-Mapping 等项目的技术研发工作。在数据收集与传输、数据建模、海量数据处理、数据应用、数据分析等领域有一定的实践经验。 2014年4月至2015年4月就职于北京极科即客科技有限公司(极路由)任数据总监职务。 2015年4月至今作为神策数据创始人并担任CTO职务,负责产品与技术研发工作。
分享内容
今天想跟大家分享一下我们目前推出的一个海量用户行为分析产品---“神策分析”的设计与实现。由于脱离需求和产品谈技术是不合时宜的,所以我首先会先讲一下我们产品所面临的用户需求,我们是如何根据这些用户需求来确定我们的产品设计,以及这些产品设计对于技术选型的一些要求,后面再详细讲一下我们产品整体架构和技术实现。
简单来看我们的产品面临的第一个需求,我们的客户普遍需要一个可以私有化部署的用户行为分析产品,这个需求是可以理解的,也是有很多实际的原因:首先是出于对数据安全和隐私的考虑;其次则是希望能够完成数据资产的积累;第三个则是希望可以对数据做深度的应用与二次开发,满足数据的更高阶的应用需求,而这些都是只有私有化部署才能够满足的。因此,私有化部署是客户对产品的一个非常实际的需求,也我们产品和技术上带来一些挑战。
首先我们做设计和开发的时候,需要考虑因为私有部署所带来的对运维、部署和设计的技术挑战,我们整个开发过程中,有至少三分之一的精力花在解决私有化部署带来的这些技术挑战上;另外一个方面,做整个产品架构设计的时候,就要考虑数据、API、计算和存储资源的开放,要让每个环节都能开放出去给用户使用;第三点,则是让我们决定整个架构以开源技术为主,如果选择一些非常冷门的技术,可能别人在这个基础上做二次开发是一个很难的事情;第四点则是为了满足客户的积累数据资产的需求,我们需要能够向用户提供明细数据,提供最细力度数据,这也是最终决定我们存储选型的一个关键性因素。
到了现在这个年代,特别是移动互联网、O2O已经蓬勃发展了这么多年,每一个产品的业务都越来越复杂,线下成分越来越重,因此全端的数据采集会是一个非常常见的需求。所谓的全端数据采集,就是要打通一个真实用户在不同端的行为,可能是iOS、安卓、Web、微信,也可能是业务数据库、第三方服务,需要能够把同一个用户在这些不同端的行为都贯通起来,一起进行分析和处理。为了满足的这一个需求,我们提供了各种不同的埋点和数据采集的手段,并且需要有一个技术手段来管理这些埋点。与此同时,我们也为客户提供了 ID-MAPPING 功能。在这里,我们对需求做了一个折中,为了保证我们的秒级导入时效性,ID-MAPPING不能向前回溯数据,因此我们选择了牺牲ID-MAPPING的部分功能而保留数据的导入时效性,这是一个客户需求与最终技术实现相互折中的一个最终例子。
我们目前有了如下的一些核心的技术决策,首先我们的产品要能私有化部署,并且花了很大的代价来解决运维的问题;其次,我们要做一个全开放的PaaS 平台,以开源技术为主,便于用户做二次开发;第三,我们要能够保证在十亿数据量下秒级导入、秒级查询的时效性。因此,我们最终没有选择预先聚合数据,而是存储明细数据,也就是说存储一条条最明细的数据,在 MOLAP 与 ROLAP 的抉择之间,我们选择了ROLAP的方案。

前边是对我们产品跟设计的一个简单的回顾,后面主要讲产品的具体技术实现。
我们在做客户端数据采集的时候,对于数据发送策略要做很多很多优化。我这里边详细列了一下我们目前所做的优化的策略,首先是我们整个数据采集策略的核心,以保证用户体验为核心,在用户体验和数据采集的时效性两方面的抉择上,宁愿牺牲部分数据采集的时效性,以保证不影响用户正常使用APP的体验。首先我们数据并不会逐条的实时的向后台发送,先在本地做缓存,网络情况比较好的时候才会往后面发送数据,发送数据的时候也会做一些打包压缩的情况。
后端日志也是比较常用的一种需要采集的数据。采集方案有两种,一种是在模块里面用代码的方式直接调用数据采用的API。之前我们提供了一整套日志打印的库,可以让这个日志直接打印到后台数据仓库里面,并且是以格式化的方式打印,从而保证一条日志在打印之后几分钟就已经能够被查询到。另外一种方案则是为了减少我们业务模块跟后面数据仓库的耦合性,会选择先在业务模块打印文本或者格式化的日志,然后用LogAgent 的方式将这些日志向数据仓库发送。
除了后端日志跟前端操作,业务数据也是一种比较常见的需要采集的数据源,主要通过工具采数据。
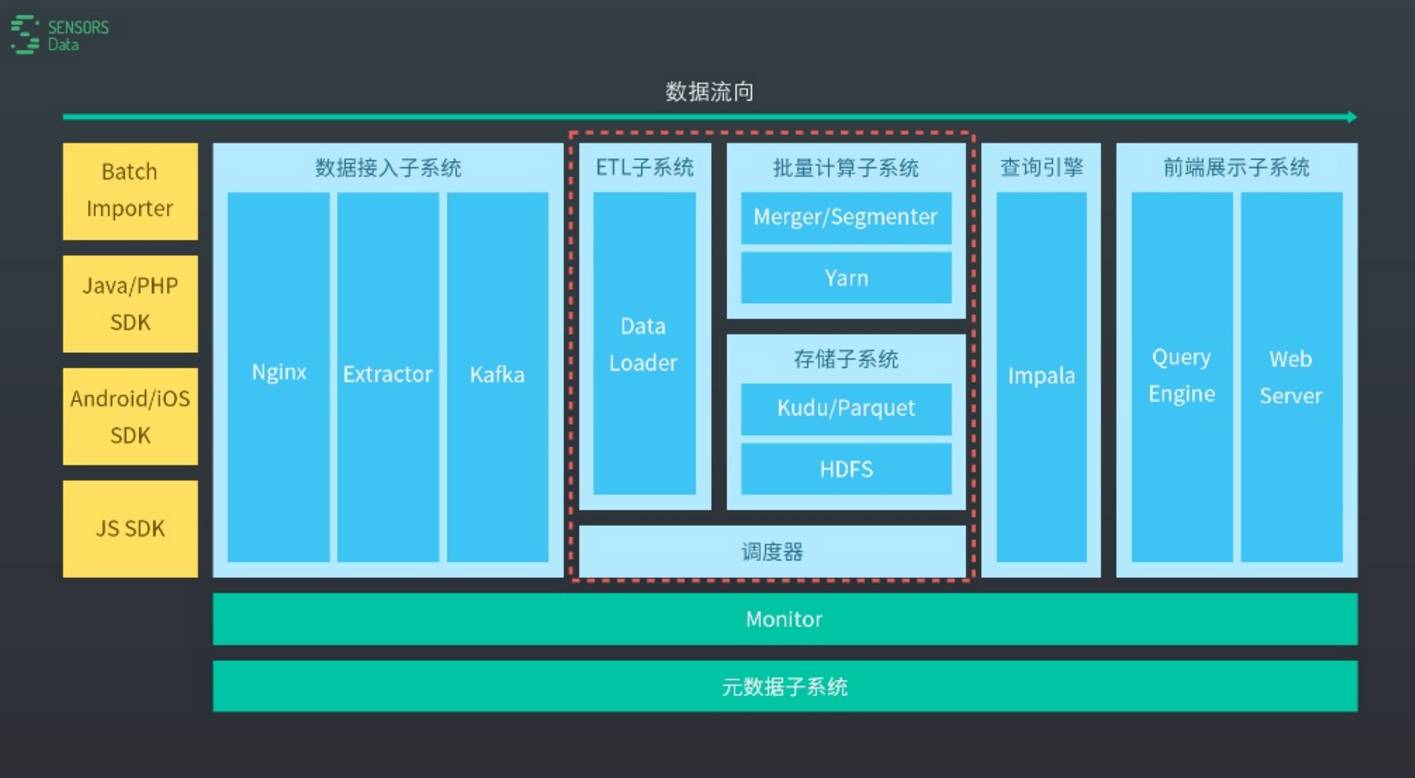
我们的数据接入层,因为我们要支持前端采集并通过公网传输数据,所我们的API采用了 HTTP 协议,所以这是一个很好的选择。
这里我们选择了Nginx做数据接入服务,在只需要接收 HTTP 请求并且打印日志的情况下,Nginx 可以保证很好的可靠性、很高的性能。能够很轻松满足单台接收十几万条用户行为的需求,能够满足绝大多数产品的需要。同时Nginx也能很容易做到负载均衡和服务冗余,这方面有很多成熟的方案。
然后我们有一个模块叫做 Extractor,它会实时读取和处理Nginx日志,然后把处理结果发送到kafka。
我们所有的数据都是要发到KAFKA,是一个高可用的数据分布式队列,用它是作为数据接入与数据处理之间的缓冲,也是数据的一个暂存,并且可以对外提供访问。
怎么样把KAFKA里面的数据实时写到我们的存储系统里面?
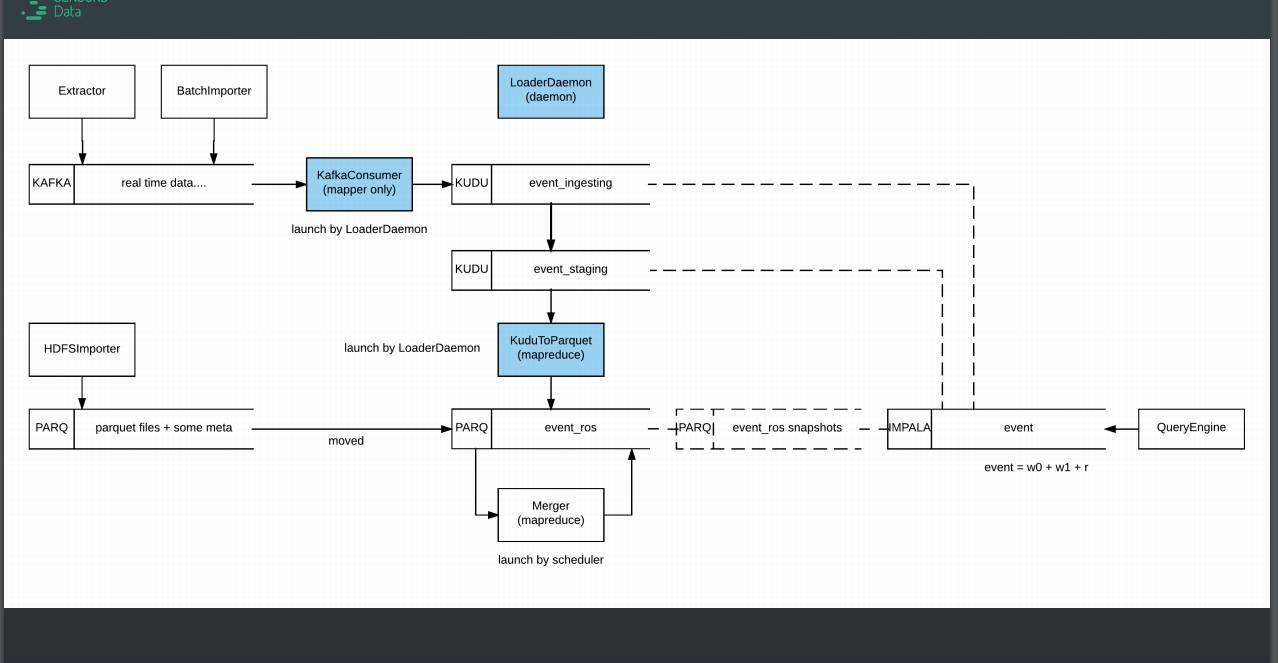
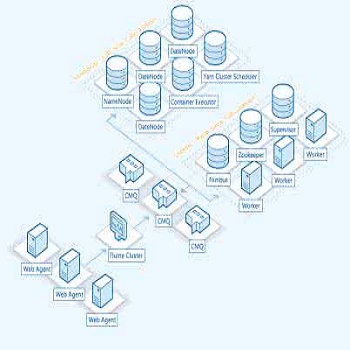
在存储上,我们选择了 Kudu 和 Parquet 两个存储方案。其中,Kudu 被我们用作 WOS,响应实时的写入。Parquet 被我们用作 ROS,保证良好的查询性能。下面是我们的整个存储写入的流程图。简单的来说我们有一个模块叫 KafkaConsumer,是一个常驻内存的 MapReduce程序,会实时地从kafka订阅数据,并将数据实时写入到Kudu中。在Kudu中有两类表,一类是正在被写入,另一类则是不再被写入。当一张表的写入数据量达到阈值时,它就不再会被写入,而是会写入新的表中。每一个不再被写入的 Kudu 表,都会被一个后台程序转换成Parquet文件,并且移动到相应的一系列Partition中。由于这种操作过程,每一个Partition下都可能会有一系列碎文件,则我们后台会有一个定时的 MapReduce程序,用来将碎文件合并成理想大小的文件,目前我们在多次尝试后,选择了 512MB 作为一个比较理想的文件大小,从而提高查询和扫描的速度。

我们跟用户打交道的一个模块是WebServer,它是用来转发前端查询请求的,会接收客户通过我们前端发送过来的查询请求。当然,前端也提供了相应的 API,以满足客户的二次开发需求。WebServer会把这个查询请求转发给QueryEngine,后者会将查询请求翻译成SQL提交给Impala。Impala是一个目前很流行的 MPP 架构的分布式计算系统。前面我们提到,数据是存储在Kudu和Parquet两个存储体系里面,所以在这里我们将他们构建了一个视图,让Impala直接在这个视图上面进行查询,然后把查询的结果返回给前端。
美团点评技术沙龙由美团-点评技术团队主办,每月一期,每期沙龙邀请美团-点评及其他互联网公司的技术专家分享来自一线的实践经验,覆盖各主要技术领域。