Storm精华问答 | 最火的流式处理框架——Storm
戳蓝字“CSDN云计算”关注我们哦!

Storm是Twitter开源的分布式实时大数据处理框架,被业界称为实时版Hadoop。 今天就为大家带来Storm诞生到发展再到实践,赶快学习起来吧!

Q:Storm的诞生。
A:在2011年Storm开源之前,由于Hadoop的火红,整个业界都在喋喋不休地谈论大数据。Hadoop的高吞吐,海量数据处理的能力使得人们可以方便地处理海量数据。但是,Hadoop的缺点也和它的优点同样鲜明——延迟大,响应缓慢,运维复杂。
有需求也就有创造,在Hadoop基本奠定了大数据霸主地位的时候,很多的开源项目都是以弥补Hadoop的实时性为目标而被创造出来。而在这个节骨眼上Storm横空出世了。
Q:Storm的特点
A:Storm带着流式计算的标签华丽丽滴出场了,看看它的一些卖点:
分布式系统:可横向拓展,现在的项目不带个分布式特性都不好意思开源。
运维简单:Storm的部署的确简单。虽然没有Mongodb的解压即用那么简单,但是它也就是多安装两个依赖库而已。
高度容错:模块都是无状态的,随时宕机重启。
无数据丢失:Storm创新性提出的ack消息追踪框架和复杂的事务性处理,能够满足很多级别的数据处理需求。不过,越高的数据处理需求,性能下降越严重。
多语言:实际上,Storm的多语言更像是临时添加上去似的。因为,你的提交部分还是要使用Java实现。
Q:Storm已经发展到0.8.2版本了,如今它取得的成就
A:有50个大大小小的公司在使用Storm,相信更多的不留名的公司也在使用。这些公司中不乏淘宝,百度,Twitter,Groupon,雅虎等重量级公司。
从开源时候的0.5.0版本,到现在的0.8.0+,和即将到来的0.9.0+。先后添加了以下重大的新特性:
使用kryo作为Tuple序列化的框架(0.6.0)
添加了Transactional topologies(事务性拓扑)的支持(0.7.0)
添加了Trident的支持(0.8.0)
引入netty作为底层消息机制(0.9.0)
Transactional topologies和Trident都是针对实际应用中遇到的重复计数问题和应用性问题的解决方案。可以看出,实际的商用给予了Storm很多良好的反馈。
在GitHub上超过4000个项目负责人。Storm集成了许多库,支持包括Kestrel、Kafka、JMS、Cassandra、Memcached以及更多系统。随着支持的库越来越多,Storm更容易与现有的系统协作。Storm的拥有一个活跃的社区和一群热心的贡献者。过去两年,Storm的发展是成功的。
Q:在Storm的学习过程中,感觉难以理解的部分有:1)Storm的反馈机制的设计原理;2)HBase用在线上栏位高可用保障方面的采集过程;3)前端栏位快照数据回流,每次访问过程中商品。这三个问题应该如何理解?
A:1)可以简单参考下图
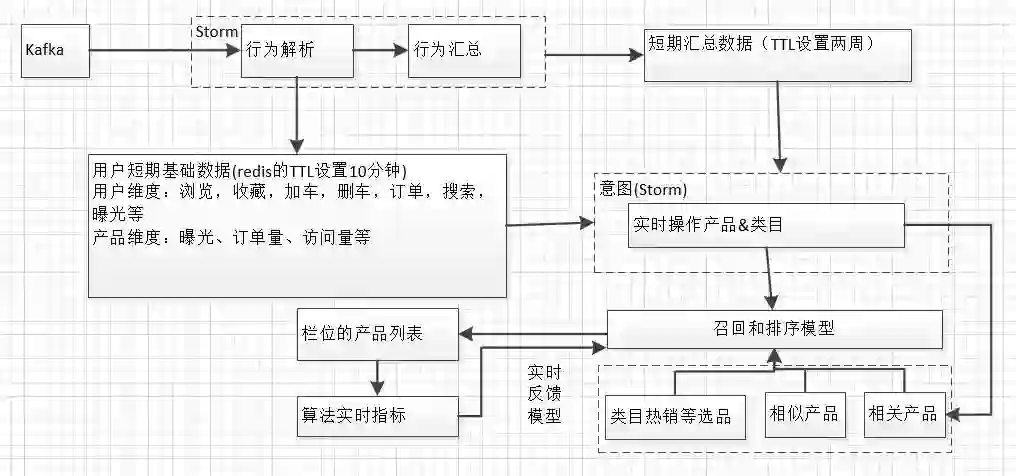
实际生产环境中需要计算栏位的产品列表不同算法的一些实时指标,不断的反馈模型,修正相关因子或权重。
2)比如,采集0.98等版本的HBase,用默认的JMX不是很好,读到的某些数据往往是溢出的,不是很准,用HBaseClient接口收集相关更精确的数据
3)尽可能的保存每一个点击行为的当前的快照,比如商品当前的订单量、访问量、价格等,用来离线训练,这些数据全部都走tracker方式,数据量比较大,在调用服务端API的时候可以异步写到Kafka,再通过Gobblin等sync到HDFS。
Q:Kafka在Storm中的角色是什么呢?是作为分流的解决方案,还是作为通信的工具?Kafka的前置机是什么?数据量大的时候Kafka会不会崩掉?
A:Kafka在Storm之前扮演一个缓冲的消息队列;Kafka最开始的前置一般有Flume等,其他消息也可以直接往Kafka写,Storm的中间过程也可以存到Kafka中,当做一个消息队列来用;双十一的时候,分区设置小,Kafka满了,来不及处理崩过,写Kafka的时候;如果客户端直接写Kafka,也要注意,并发量大会把Kafka搞挂。采用异步写+本地缓存写Kafka,比如log4j写Kafka,基本的异步和本地缓存等已经做了,数据量再大的时候,加一层Flume等。

福利
1、扫描添加小编微信,备注“姓名+公司职位”,加入【云计算学习交流群】,和志同道合的朋友们共同打卡学习!

2、公众号后台回复:白皮书,获取IDC最新数据白皮书整理资料!
推荐阅读:
Elastic Jeff Yoshimura:开源正在开启新一轮的创新 | 人物志
深入浅出Docker 镜像 | 技术头条
19岁当老板, 20岁ICO失败, 21岁将项目挂到了eBay, 为何初创公司如此艰难?
码二代的出路是什么?
机器学习萌新必备的三种优化算法 | 选型指南
小程序的侵权“生死局”
@996 程序员,ICU 你真的去不起!