推荐 | 最有趣的机器学习可视化图集

来源:AI前线
本文约3700字,建议阅读10+分钟。
本文翻译整理了“最可爱”的机器学习可视化大数据集。

[ 导读 ]本文是 Ian Johnson 在 OpenVisConf 2018 上所做的关于机器学习可视化的演讲文稿,这个演讲探索了“最可爱”的大数据集,我们做了翻译整理,以下是完整的演讲视频:
数据可视化是把模式展示出来。
我们一直在寻找挖掘更深层次模式的方法。
感觉明显是人类的图案:

我们人类能够识别的图案,但是不能清晰地表达给计算机。

我们甚至从未想过要找的图案:

计算机,只把可爱的猫头鹰的图案展示给我看
在探索新数据集时,可以使用我们的分析和可视化工具包里不同的工具。这些工具包括平均值和汇总统计、折线图和直方图,以及一个不断扩展的自定义可视化目录。
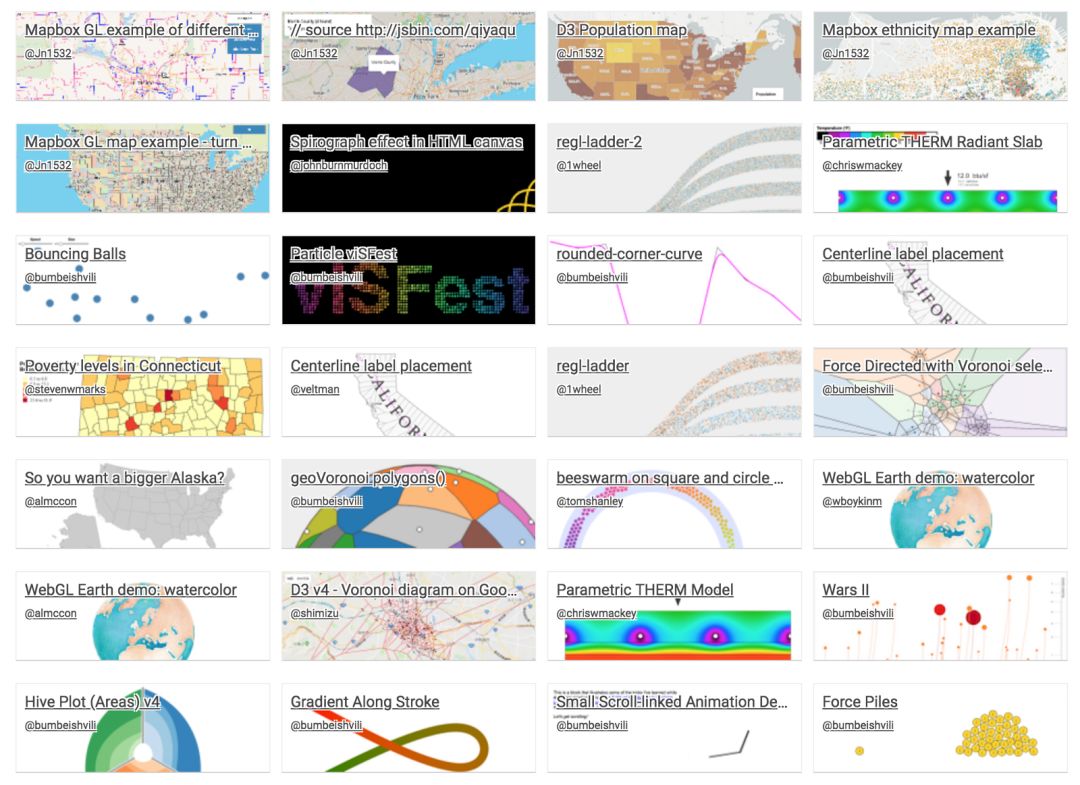
一些用 d3.js 和其他工具制作的图
现在,我想请您把注意力放到一个相对较新的工具集上,该工具集可以改变我们探索大型数据集的方式。

一切用 t-SNE 来做!
这些工具采用机器学习为我们提取模式,并提供浏览数据的新方法。
我想在我喜欢的数据集上演示这些技术,涂鸦游戏(Quick,Draw!)!

涂鸦游戏(Quick,Draw!)!
要是你还没玩过这个游戏,那就来试试吧,它的规则非常简单。它请您根据某个词画个画,然后让 AI 根据您的图画猜猜您写的啥。
当谷歌的创新实验室(Google Creative Lab)创建这个涂鸦游戏(Quick,Draw!)时,他们有先见之明地保存了图画的匿名副本,从此改变了我的生活旅程。到目前为止,全球有数百万人玩过了该游戏,同时,谷歌开源了他们创作的 5000 万幅图画。这意味着,游戏中的 300 个词平均每个有 10 万多幅图画以供探索。

含有 300 多个词的数据集中的其中一些
数据
我们仔细观察该数据,搞清楚它是什么,它不是什么。

什么、何时、何地(what, when and where)
该数据集可以用于很好的演示,因为它是这么有趣,但是,它也是很多严肃数据集的代表。它具有分类数据,比如,画的是哪个词和图画最初来自哪个国家。我们也有一些跟时间有关的维度,比如完成图画所需的时长和完成图画时的时间戳。

如何(how)
我们也有形成图画的点序列。这是笔画序列,它们携带着该数据集的大部分意义,它们捕获了我们作为人类在全球范围内代表抽象概念的方式。
它们是最难用传统数据可视化技术来剖解的。
数据可视化
仅仅因为某些事情有困难,不意味着无法完成。自从该数据集发布以来,一些令人惊讶的项目应用了各种技术来呈现数据中的有趣模式。
《涂鸦游戏多久能画好一条狗?》
http://vallandingham.me/quickdraw/
作者:Jim Vallandingham
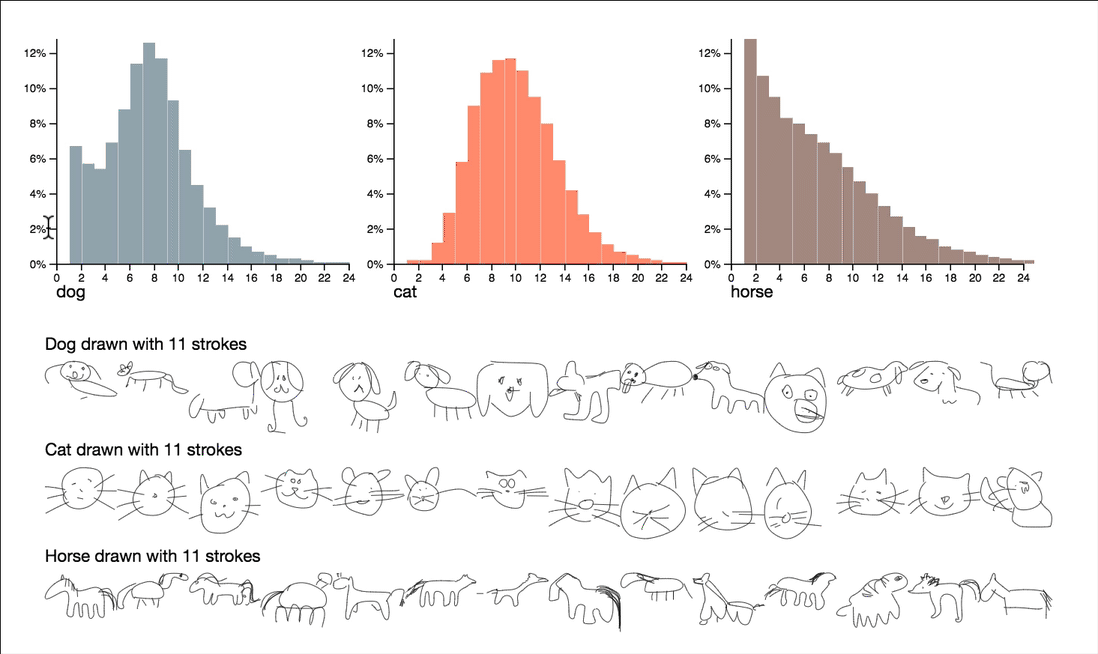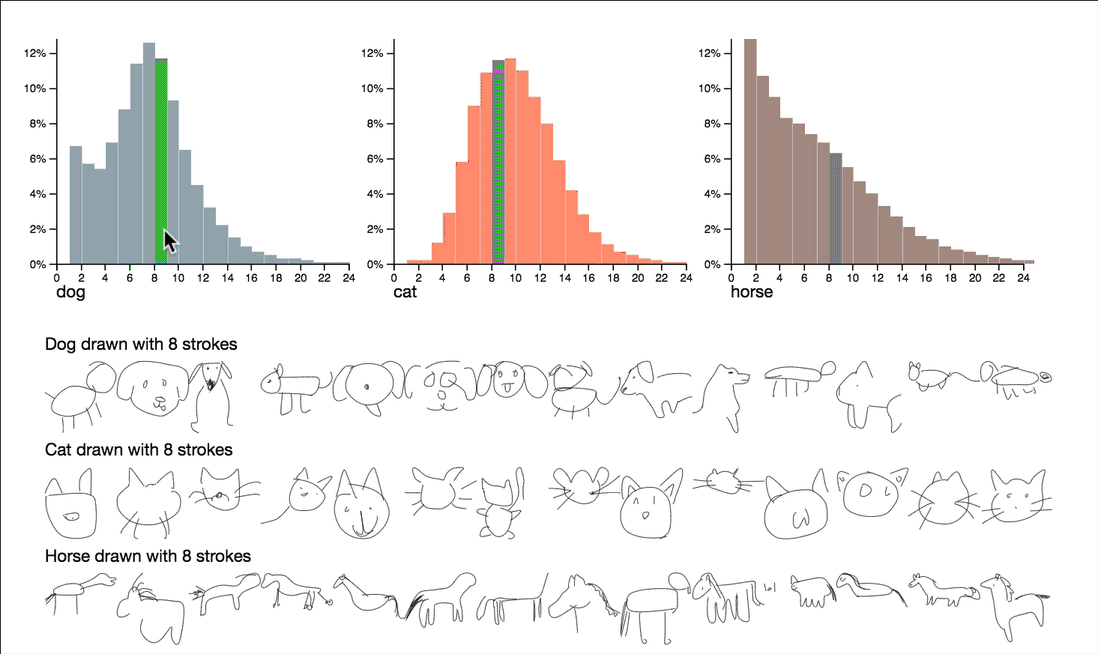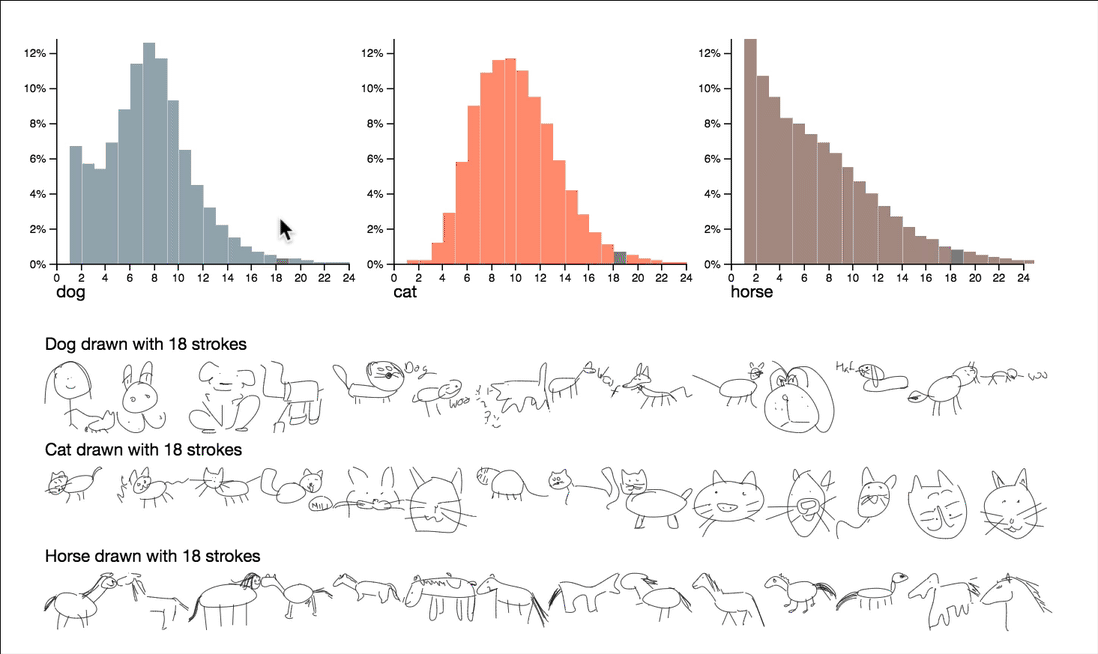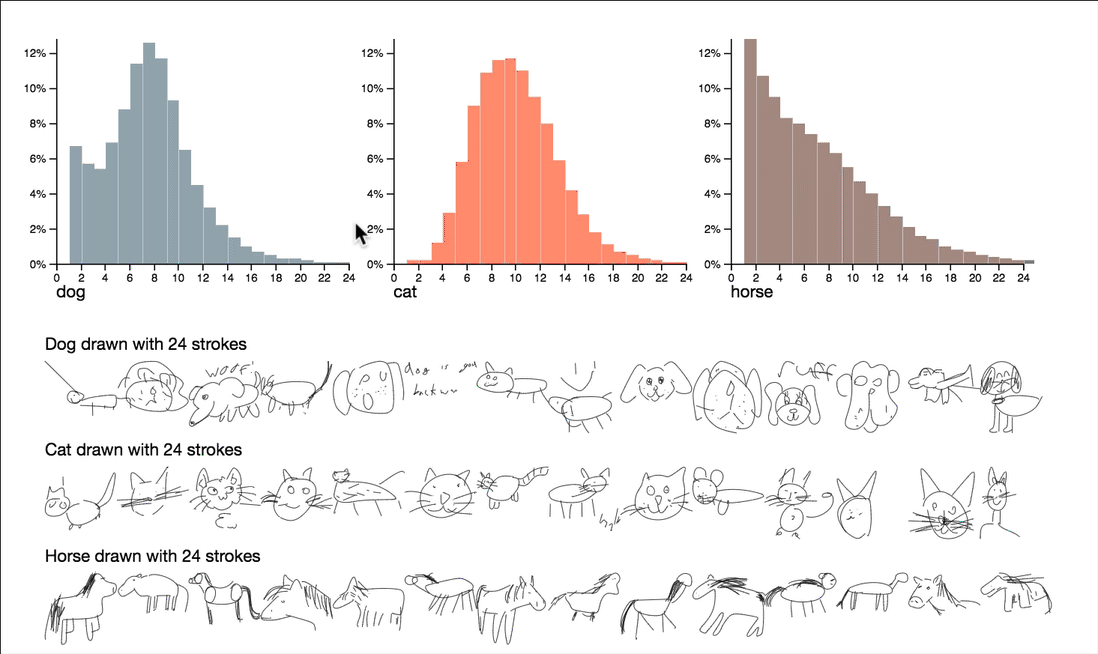
按复杂性分解数据
该项目通过利用笔画数和绘图时长,来探索有关复杂性和质量的问题。可以通过交互式浏览这些属性的摘要统计信息,来呈现一些非常有趣的观察结果。
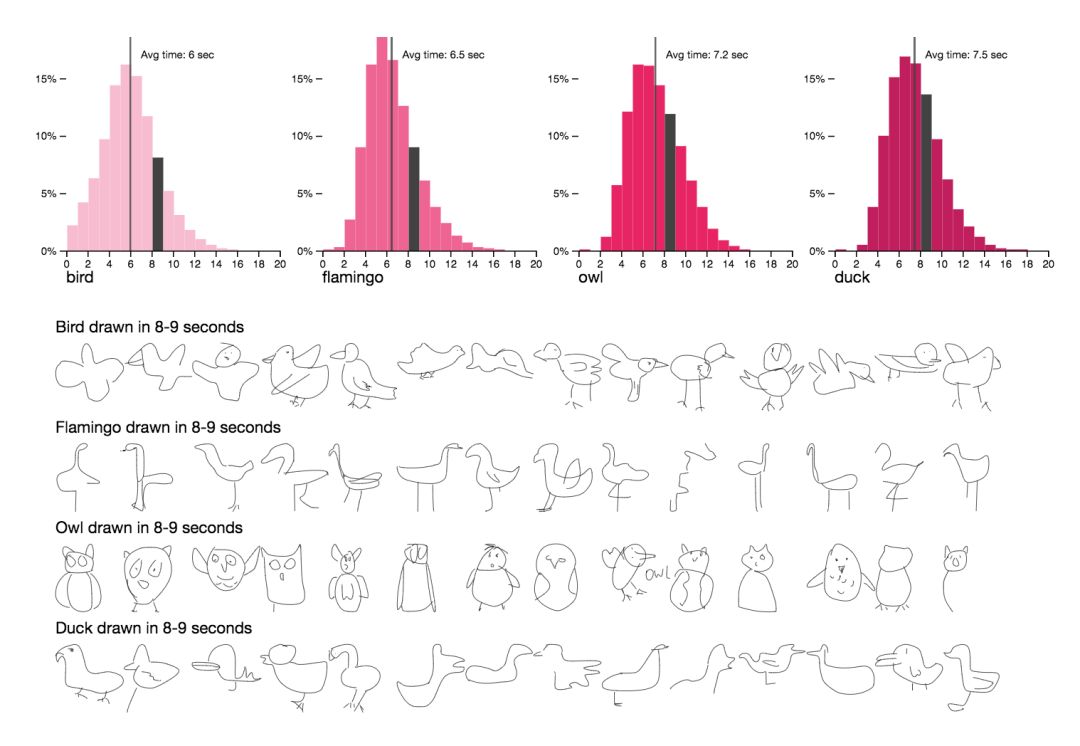
平均而言,画鸭子比画火烈鸟用的时间要长一些。而且,猫头鹰总是那么可爱。
请注意,这里的可视化维度是笔画数和绘画时长,这两个都把笔画数序列降到个位数。这些数字给了我们一个可控的方法来探究一下数据,但是它们自己无法捕捉图画的所有特征。
《您如何画圆?》
https://qz.com/994486/the-way-you-draw-circles-says-a-lot-about-you/
作者:Nikhil Sonnad
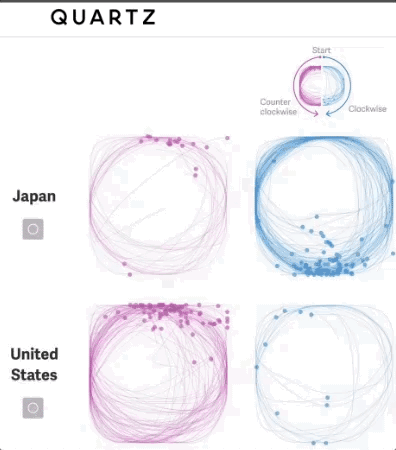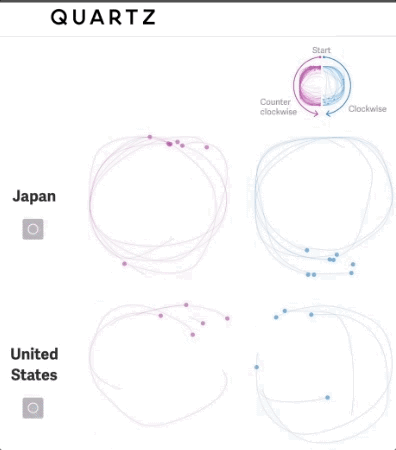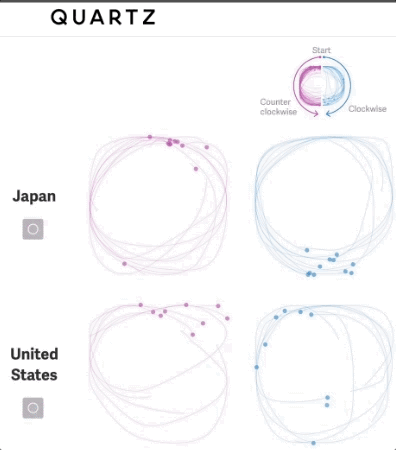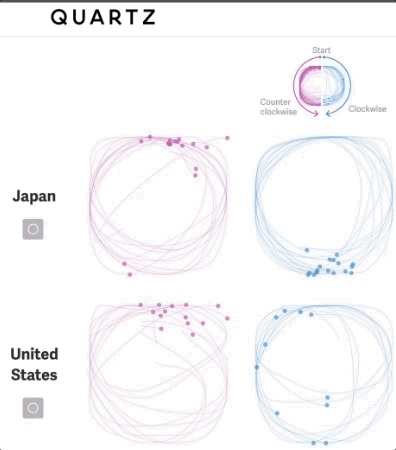
我们可以不仅看到我们绘制的作品,还能看到我们绘制的过程
本文对简单形状进行了深入研究,确定每个圆是按顺时针还是逆时针绘制,并允许在数据集中把这个特征考虑进去。
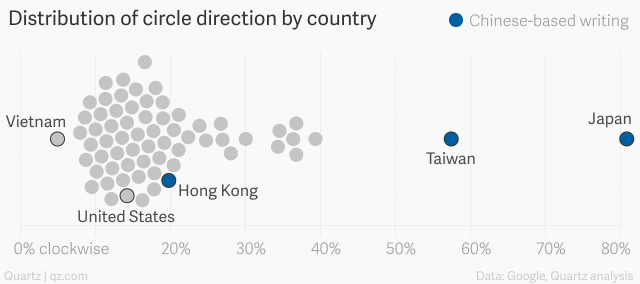
突出文化现象
随后,可以可视化该特征,以传达对全球各地文化差异的理解。
“我们有无数的方法可以巧妙地、无意识地携带我们的文化:我们绘图的方式、用手指计数的方式、模拟真实世界的声音,可以举上几个例子。那是该海量数据集的核心所在。”
—IBM 研究中心视觉 AI 实验室
—Forma Fluens

A 代表平均值(Average)
该项目用了不少有趣的方法来可视化数据。特别是利用视觉平均值来突出文化模式。

糟糕,我忘了我的转换器
视觉平均值的工作原理是,绘制数千微弱透明的图,并叠加在一起,以呈现出主导图案。当我们根据可以合并的文化模式,按照国家来过滤图时,效果相当好。
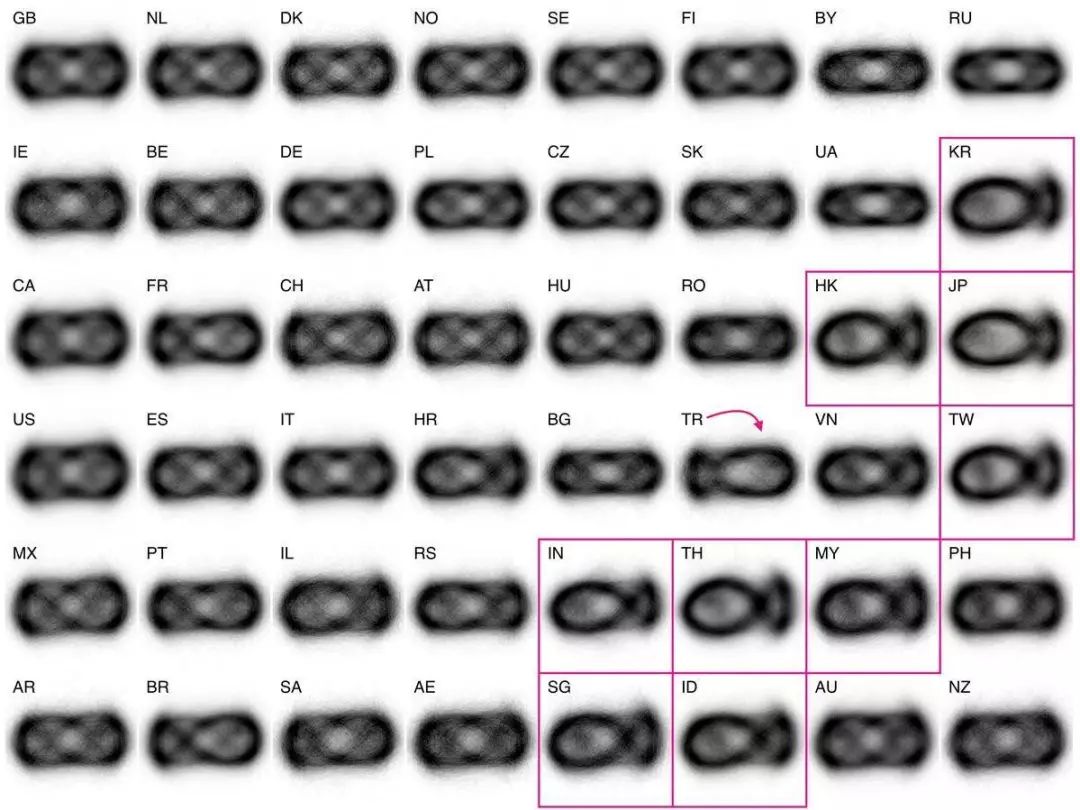
《按照国家来划分的视觉平均值》
https://twitter.com/kcimc/status/902229612666658816?lang=en
作者:Kyle McDonald
Kyle McDonald 在这个史诗般的推特风暴中把视觉平均值的概念推到了极致。
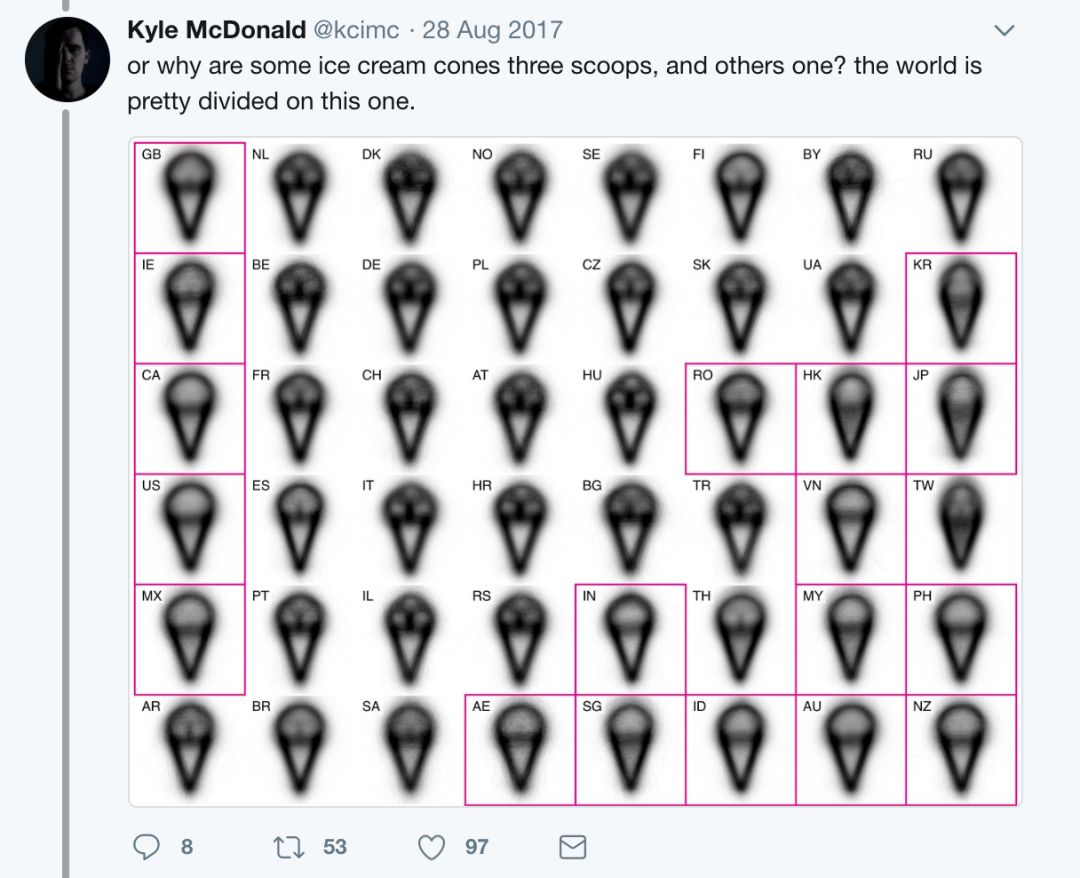
霜淇淋(soft-serve)在哪里?
他充分利用小倍数来比较几个类别的模式。
寻找尼姆(小丑鱼)
这些确实给了我们一些有趣的反思点,但是,难以深入挖掘,因为所有细微差别的模式都被平均化给清洗掉了。
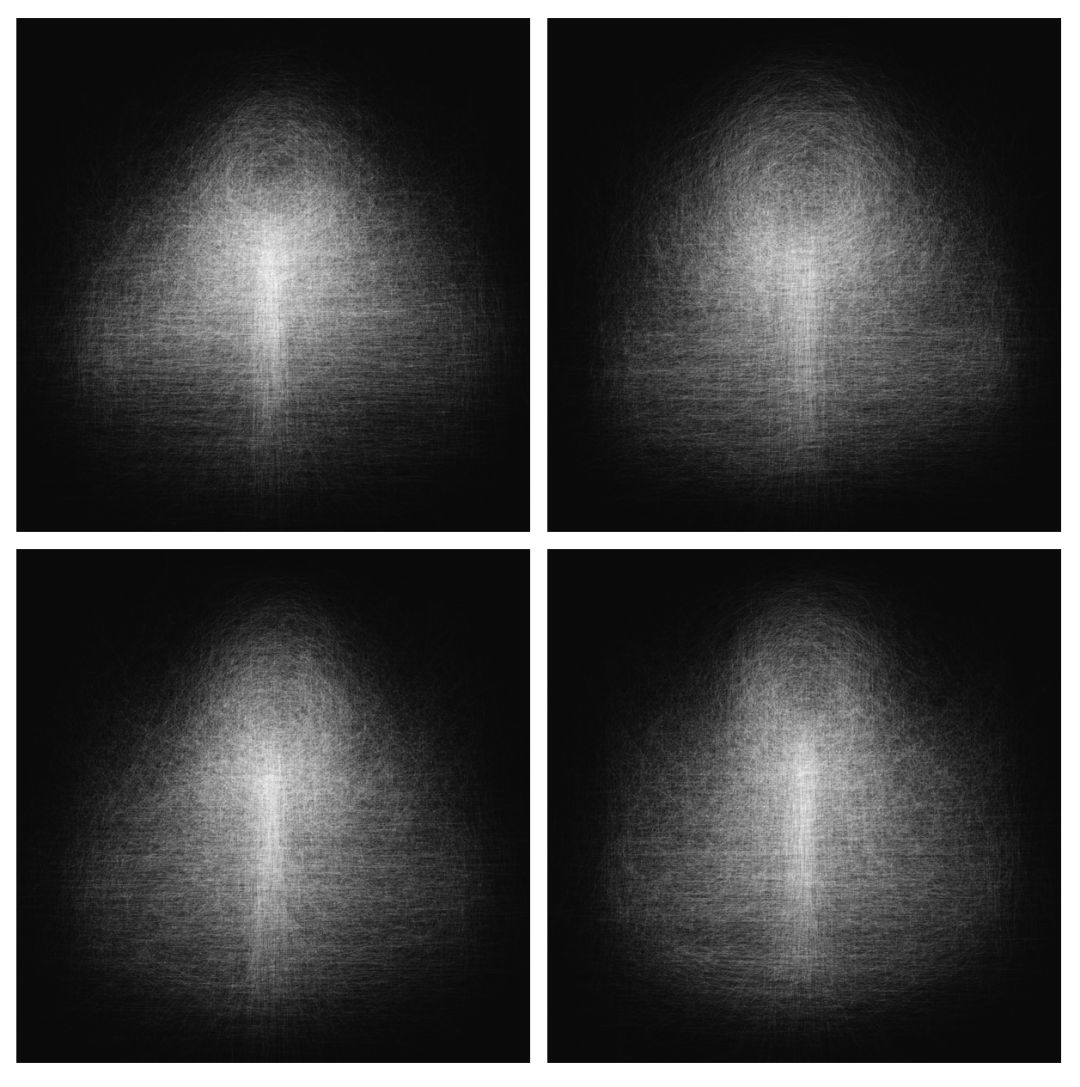
我们平均化瑜伽姿势后,真的看不出什么东西。国家:美国、韩国、德国、巴西
因此,如果我们有方法来捕捉因为平均化而丢失的细微差别,以自动寻找在笔画中的有趣特征,并一次多维度剖解数据,会怎样?
机器学习
进入深度神经网络。这不是魔术,但是,它们具有一些令人惊讶的能力,并且,事实证明,我们只有这一个网络在涂鸦游戏上的数据集上受过训练。它被称为 sketch-rnn。

可以在 sketch-rnn 演示页面上自行玩耍一下
尽管和该网络玩耍以及为绘图机提供有创造力的应用程序是非常有趣的,但是,更令我们这些数据可视化人员激动的是,为了生成图画而必须编码的模式。
那么,我们怎样得到这些模式?
一种处理方式是,询问网络它认为给定图画的可能性,就像 Colin Morris 在其《糟糕的火烈鸟(Bad Flamingos)》一文中所做的。

机器学习的背叛。火烈鸟?¯_(ツ)_/¯
处于顶部的是网络认为极有可能是火烈鸟的图案,而处于底部的,网络认为不可能是火烈鸟的图案。这给了我们一个有趣的视角来查看数据,但是它仍然把所有的数据减少到一个维度。这是个问题,因为关于火烈鸟的一些最有趣的描述和那些明显不是火烈鸟的词混在一起了。
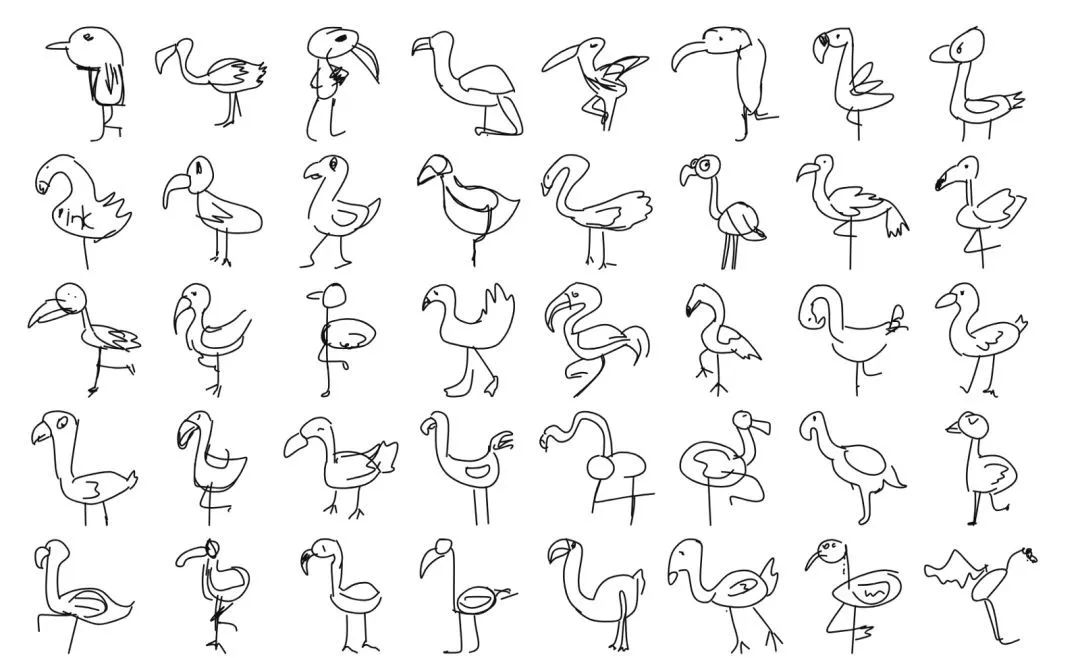
如果我们要找坏蛋火烈鸟,怎么办?
我们希望有更广泛的数据视图,一旦我们对网络的操作有更多的了解,我们就可以得到。Sketch-rnn 属于称为自动编码器神经网络家族,寻找把输入数据“压缩”成一个较小的表示方法,以便稍后用于生成新的输出。
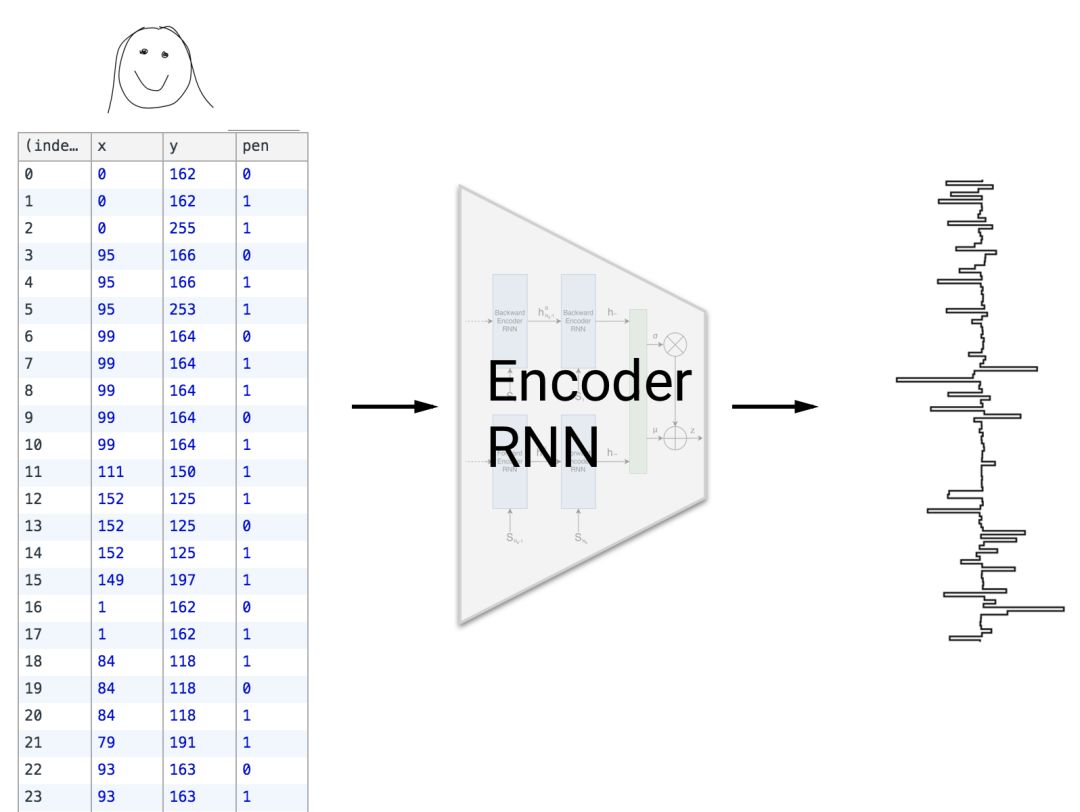
编码器接收图片,并把图片压缩成一个特征向量
该网络由两部分组成,其中,编码器网络尝试找出一种方法,以比输入更少的维度来表示数据,另一个是解码器网络,其尝试只使用编码后的数据精确地重建原始数据。
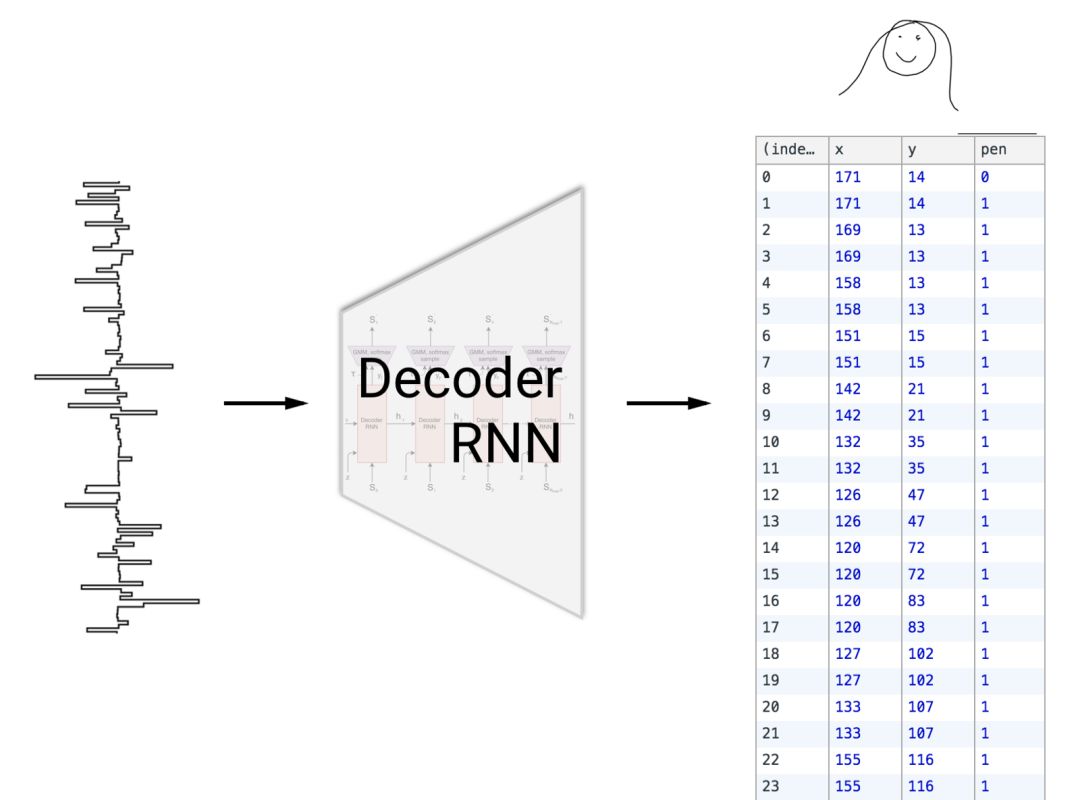
该解码器把特征向量作为输入,并输出新(非常类似的)图。
我们称编码后的数据为特征向量,它是解锁我们技术的关键。
特征向量
可以为网络中的每张图提取特征向量,这给了我们一种方法对图进行数字化比较。
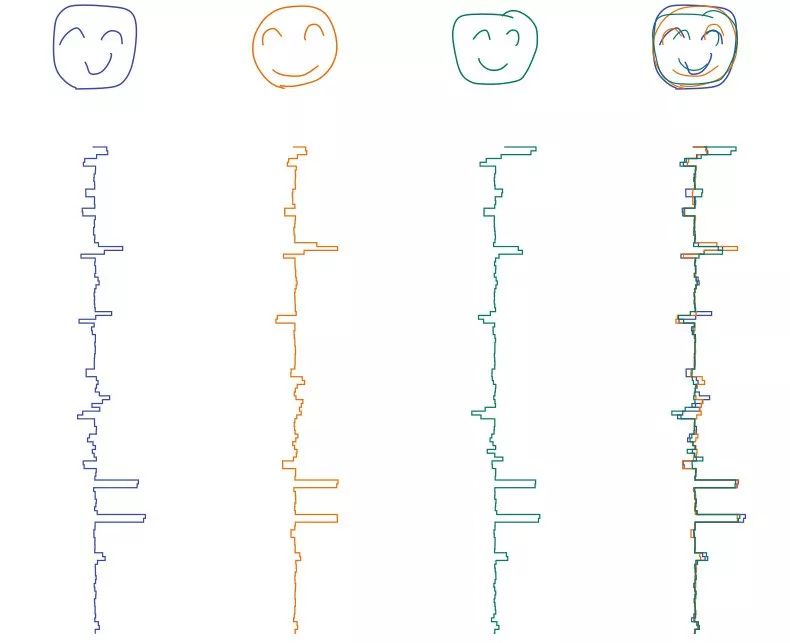
类似的脸有类似的特征向量
当我们比较它们时,类似的特征向量就意味着类似的图片。在我们的网络中,特征向量有 128 个数字,还是有很多要处理。因此,我们需要一种方法来进行高维数据点之间的比较。
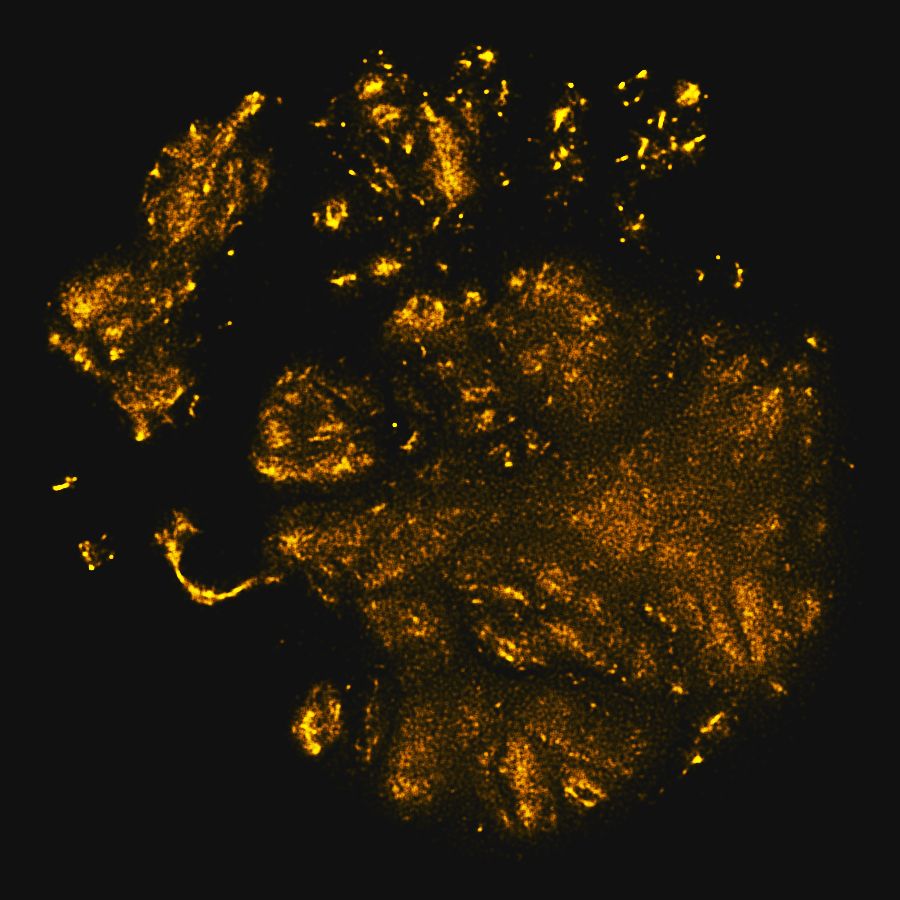
包含我们所有脸的图
幸运的是,有个叫做 t-SNE 的算法很棒,它对在高维度数据中可视化相似性很有帮助。它不是个银弹,但是,它给了我们一个很有趣的方法来探索我们的数据。在这里,每张图由一个小的半透明黄点表示,该算法把类似的图放在彼此靠近的位置以创建这张二维图。
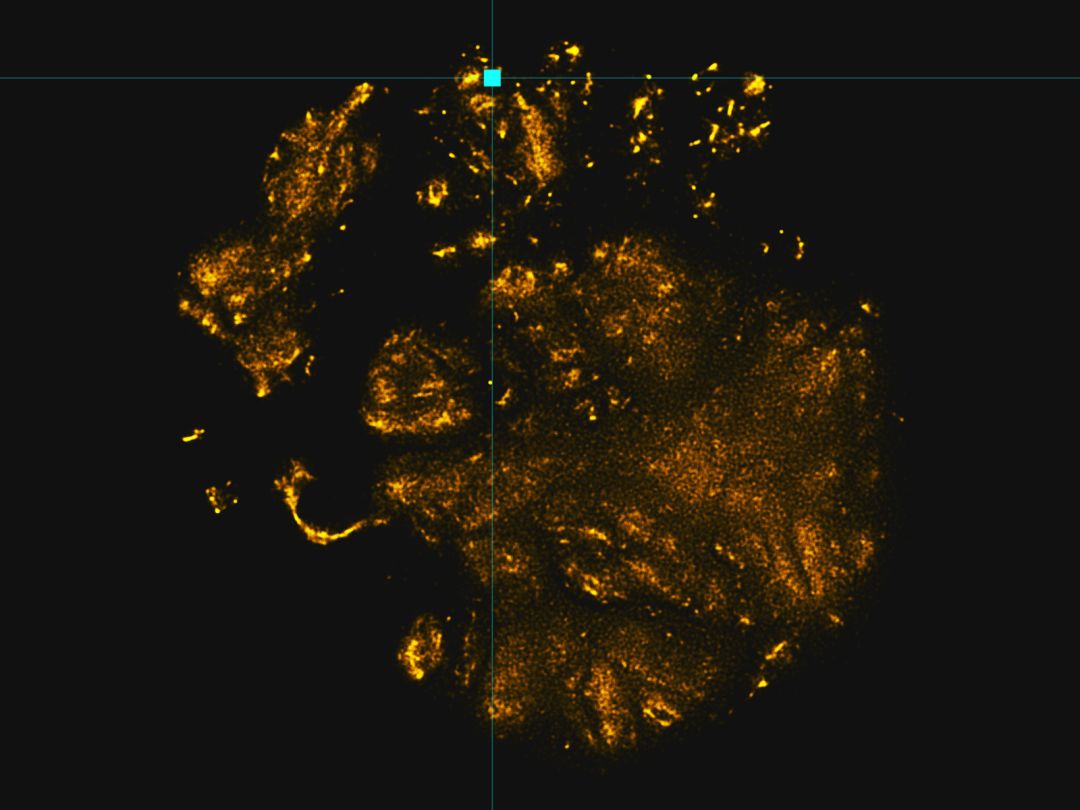
我们可以放大该图的一小部分,查看一组类似的图片。

作为人类,我们用我们的眼睛看到这里的图案很清晰,是眼睛和笑脸。
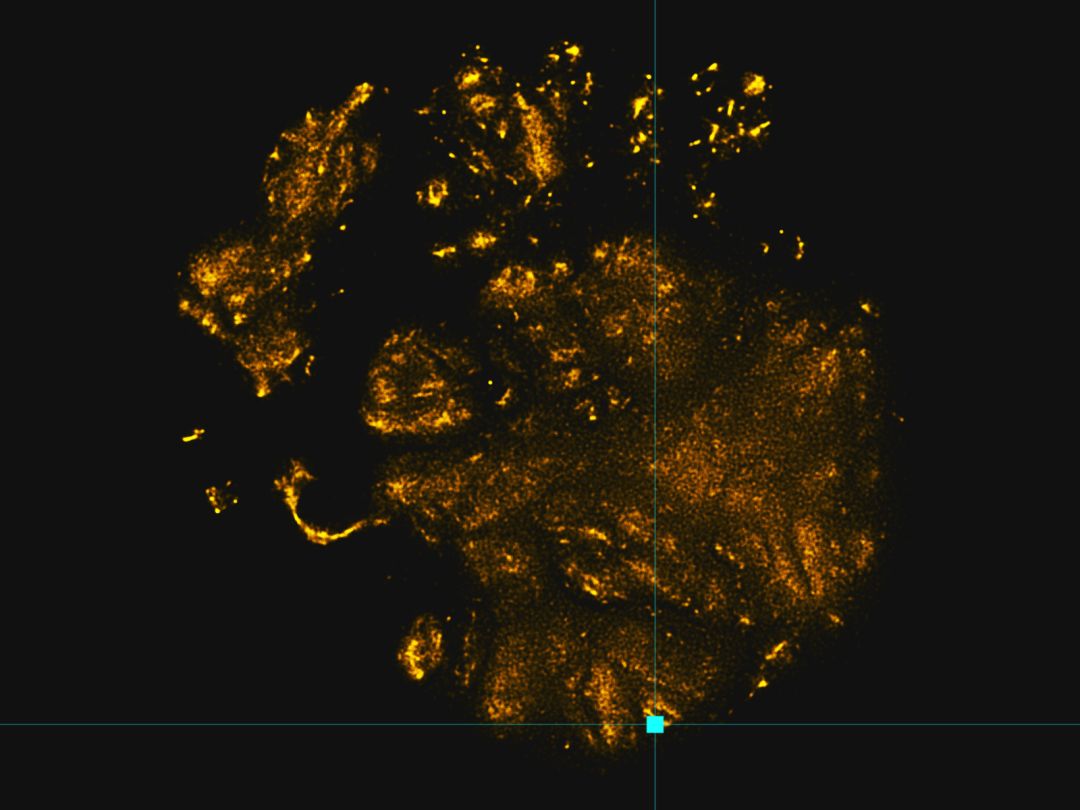
我们来看看一个完全不同的集群。

我们可以看到这个集群突出了相当不同的图,这是悲伤的脸图。
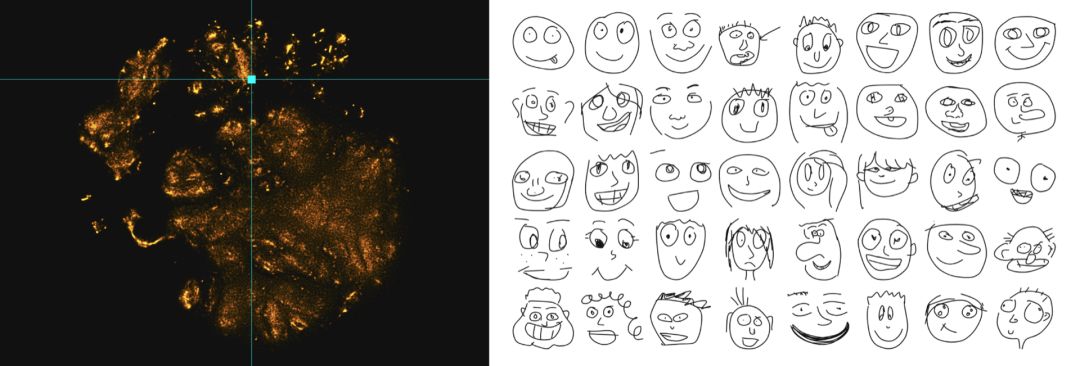
古怪的维度
我们回到研究图的复杂性上来。我们可以直接检查复杂性,而不是使用代理来处理像笔画数或绘图时长这样的复杂性。
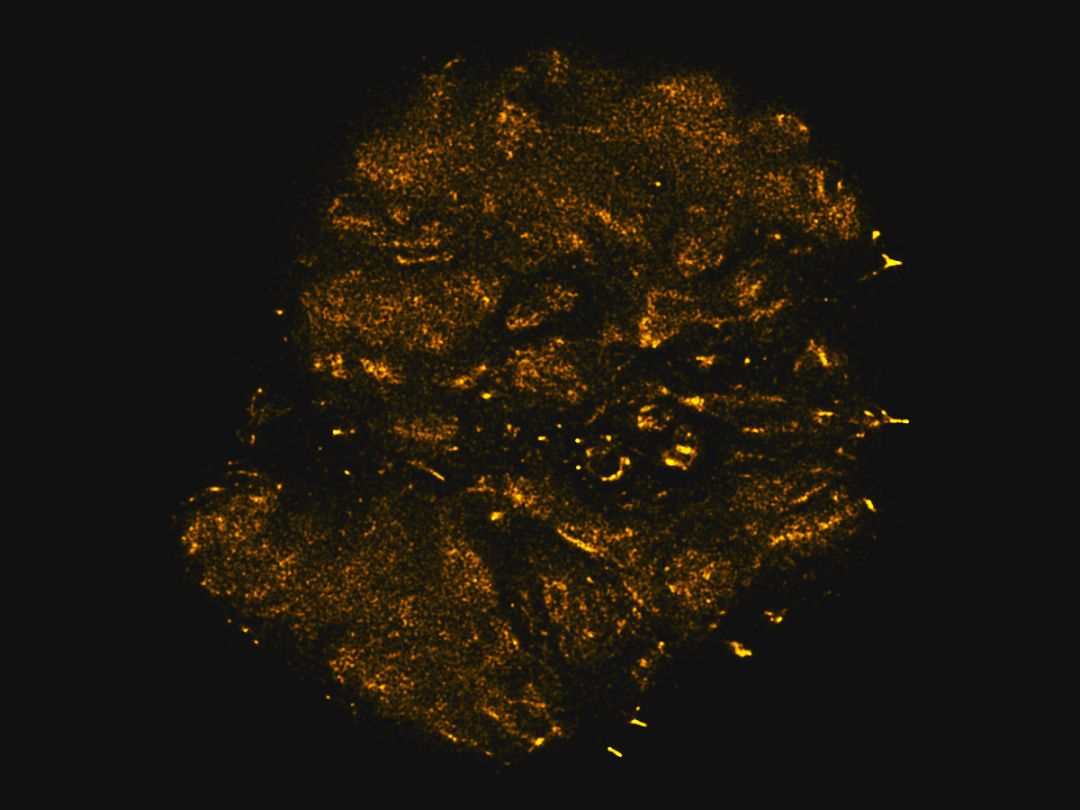
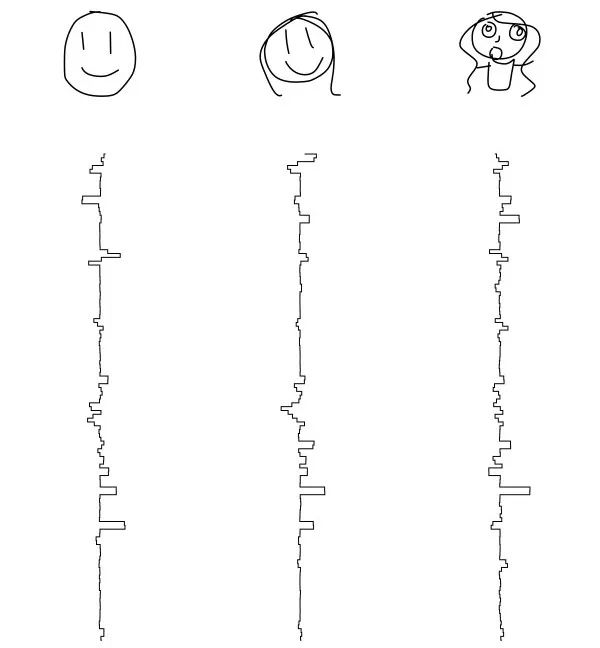
猫图
这里有种方法来画一只简单的猫,所有这些都是一笔画:
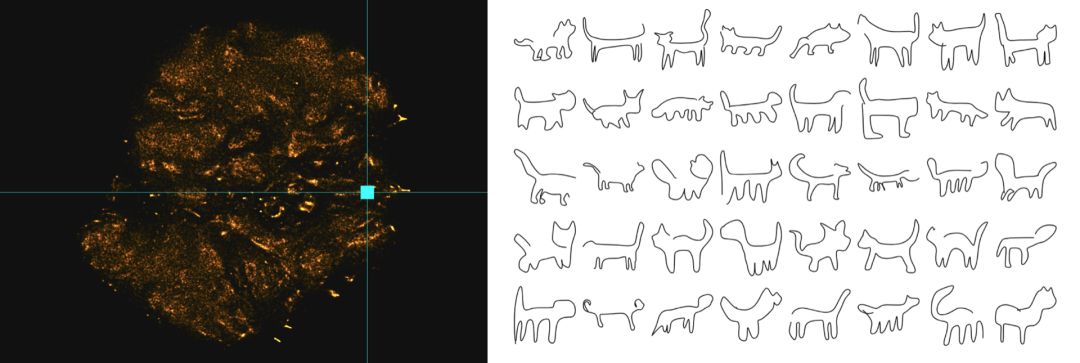
这是另一种简单方法来捕捉猫的本质特征,尽管这次的笔画数是 3。在这两种情况下,如果把这些都放在孩子眼前,他们会认出那是猫!
现在,我们离开数字世界,进入人文领域:

这里有一些大致相同的复杂的猫的图,但是,很明显,我们在观察胡须而不是微笑:

我们无需就此打住,我们可以拥有全部特征!

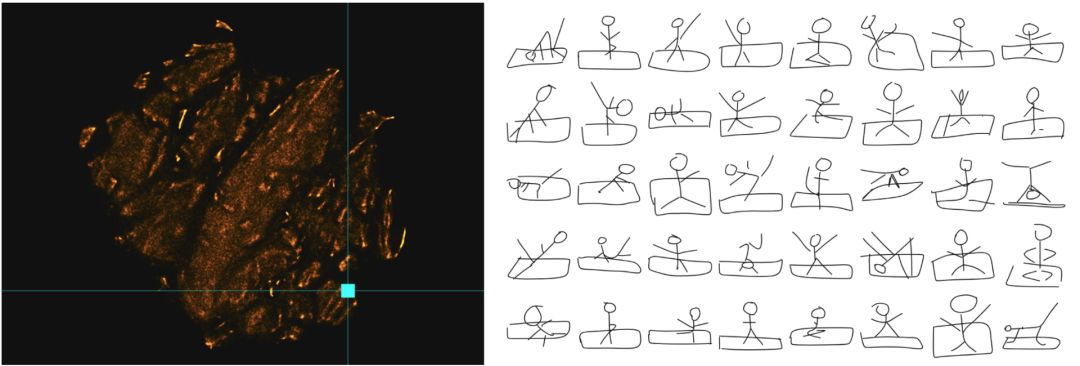
因此,现在我们正在浏览比单个维度更丰富的空间。让我们回顾一下像瑜伽姿势这样的平均概念问题上。
瑜伽姿势图
平均值的问题在于,它们采取单一模式的假设正态分布。我们可以看到的是,代表瑜伽姿势有几个模式,从不同的姿势开始。
不要忘了呼吸
人们绘制一种姿势的方式:

人们放弃的方式:

现在,我想暂停一下,退回到我们图片的特定数据集,确保我们清楚在这里发生的两件事。
第一件事,t-SNE 是用于高维度数据可视化的常用技术。

采用 t-SNE 进行数据可视化
作者:Laurens van der Maaten
第二件事,神经网络可以处理各种数据上。在摘自 Chris Olah 的令人惊讶的文章《Deep Learning for Human Beings》的这张图中,句向量(paragraph vector)用 t-SNE 进行可视化,以呈现维基百科文章中的主题。
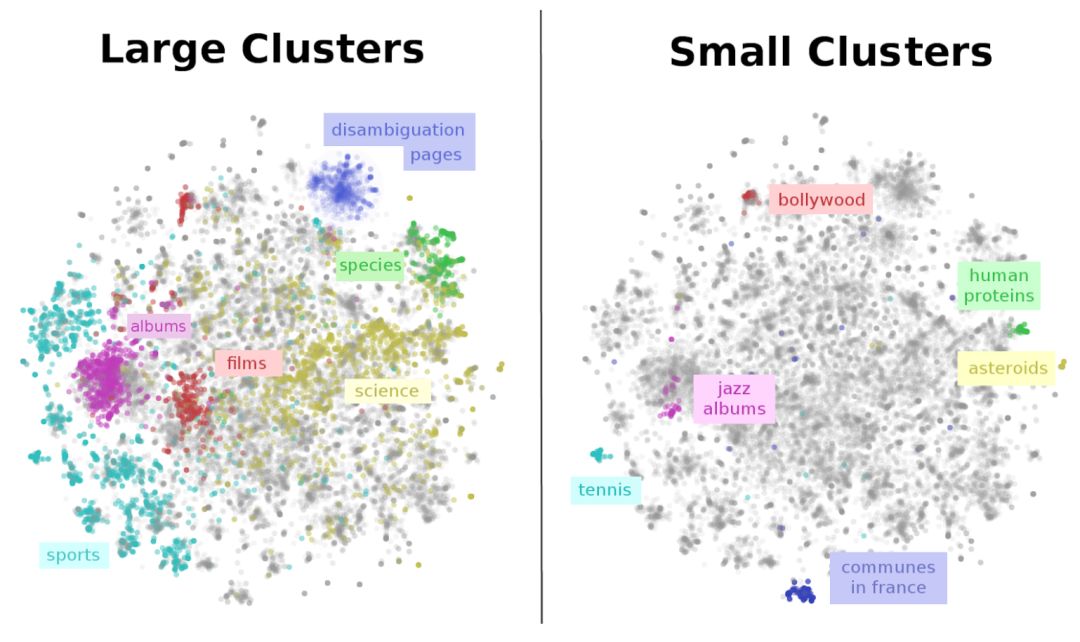
因此,通常来说,用神经网络来寻找模式并用 t-SNE 对它们进行可视化是好主意。
“特征空间”是更数学化的术语,用来表示由我们的神经网络的内部表示创建的高维度景观。我们可以认为 t-SNE 帮助我们绘制了该空间图。

与 2 维地图不可能真正代表我们的 3 维地球类似,2 维的 t-SNE 图不能把在更高维度发生的事情都展示给我们看。

但是,它仍然可以是我们探索浏览过程中非常有帮助的方法。

这里,我们已经从每个网格单元采样了一幅图,不透明度表示该单元中图的数量。

更简单的笑脸

带有长发的脸、带有短发的脸,或者没有头发的脸
我们简要回顾一下根据国家 / 地区代码进行平均的想法。

通过这个视图,我们可以用国家 / 地区代码进行过滤。我们可以快速浏览一下日本电源插座的图。

如果我们放大来看,可以看到主要的代表是“A 类型”的插座,具有两个垂直的孔。与平均值中的不同,我们也可以看到一些有趣的离散值,它们看起来已经被认为是力量举重,而不是电源插座。

左边:标准的“A 类型”插头,右边:力量举重
我们来看看另一个词:章鱼,并重新审视复杂性的想法。

我们可以将我们的图过滤为只有一笔画的章鱼图,并从这些区域采样。可能很容易想象在这样的情况下用一笔画来绘制章鱼。

如果我们把图过滤为所有复杂的章鱼图,这些图都超过 14 个笔画:

我们发现一个确实有趣的集群:

结论
人们绘图的不同方式就像不同的音符,词的谐音和我们已经探索过的集群是数千个陌生人和谐共处的结果。

合十图案(Namaste,表示感谢)
谢谢!

随机分配的老虎图案
阅读英文原文:
https://medium.com/@enjalot/machine-learning-for-visualization-927a9dff1cab







