GitHub最著名的20个Python机器学习项目

摘要: 开源是技术创新和快速发展的核心。这篇文章向你展示Python机器学习开源项目以及在分析过程中发现的非常有趣的见解和趋势。
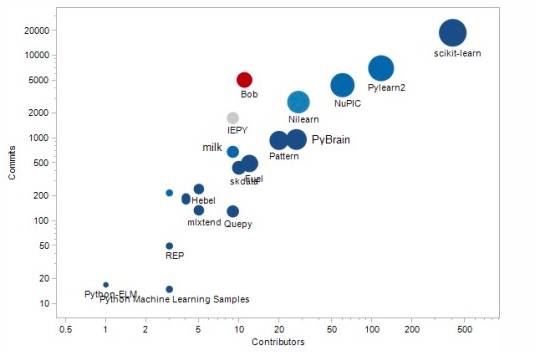
我们分析了GitHub上的前20名Python机器学习项目,发现scikit-Learn,PyLearn2和NuPic是贡献最积极的项目。让我们一起在Github上探索这些流行的项目!
Scikit-learn:Scikit-learn 是基于Scipy为机器学习建造的的一个Python模块,他的特色就是多样化的分类,回归和聚类的算法包括支持向量机,逻辑回归,朴素贝叶斯分类器,随机森林,Gradient Boosting,聚类算法和DBSCAN。而且也设计出了Python numerical和scientific libraries Numpy and Scipy
https://github.com/scikit-learn/scikit-learn
Pylearn2:Pylearn是一个让机器学习研究简单化的基于Theano的库程序。
https://github.com/lisa-lab/pylearn2
NuPIC:NuPIC是一个以HTM学习算法为工具的机器智能平台。HTM是皮层的精确计算方法。HTM的核心是基于时间的持续学习算法和储存和撤销的时空模式。NuPIC适合于各种各样的问题,尤其是检测异常和预测的流数据来源。
https://github.com/numenta/nupic
Nilearn:Nilearn 是一个能够快速统计学习神经影像数据的Python模块。它利用Python语言中的scikit-learn 工具箱和一些进行预测建模,分类,解码,连通性分析的应用程序来进行多元的统计。
https://github.com/nilearn/nilearn
PyBrain:Pybrain是基于Python语言强化学习,人工智能,神经网络库的简称。 它的目标是提供灵活、容易使用并且强大的机器学习算法和进行各种各样的预定义的环境中测试来比较你的算法。
https://github.com/pybrain/pybrain
Pattern:Pattern 是Python语言下的一个网络挖掘模块。它为数据挖掘,自然语言处理,网络分析和机器学习提供工具。它支持向量空间模型、聚类、支持向量机和感知机并且用KNN分类法进行分类。
https://github.com/clips/pattern
Fuel:Fuel为你的机器学习模型提供数据。他有一个共享如MNIST, CIFAR-10 (图片数据集), Google's One Billion Words (文字)这类数据集的接口。你使用他来通过很多种的方式来替代自己的数据。
http://www.github.com/mila-udem/fuel
Bob:Bob是一个免费的信号处理和机器学习的工具。它的工具箱是用Python和C++语言共同编写的,它的设计目的是变得更加高效并且减少开发时间,它是由处理图像工具,音频和视频处理、机器学习和模式识别的大量软件包构成的。
www.github.com/idiap/bob
Skdata:Skdata是机器学习和统计的数据集的库程序。这个模块对于玩具问题,流行的计算机视觉和自然语言的数据集提供标准的Python语言的使用。
www.github.com/jaberg/skdata
MILK:MILK是Python语言下的机器学习工具包。它主要是在很多可得到的分类比如SVMS,K-NN,随机森林,决策树中使用监督分类法。 它还执行特征选择。 这些分类器在许多方面相结合,可以形成不同的例如无监督学习、密切关系金传播和由MILK支持的K-means聚类等分类系统。
www.github.com/luispedro/milk
IEPY:IEPY是一个专注于关系抽取的开源性信息抽取工具。它主要针对的是需要对大型数据集进行信息提取的用户和想要尝试新的算法的科学家。
www.github.com/machinalis/iepy
Quepy:Quepy是通过改变自然语言问题从而在数据库查询语言中进行查询的一个Python框架。他可以简单的被定义为在自然语言和数据库查询中不同类型的问题。所以,你不用编码就可以建立你自己的一个用自然语言进入你的数据库的系统。现在Quepy提供对于Sparql和MQL查询语言的支持。并且计划将它延伸到其他的数据库查询语言。
www.github.com/machinalis/quepy
Hebel:Hebel是在Python语言中对于神经网络的深度学习的一个库程序,它使用的是通过PyCUDA来进行GPU和CUDA的加速。它是最重要的神经网络模型的类型的工具而且能提供一些不同的活动函数的激活功能,例如动力,涅斯捷罗夫动力,信号丢失和停止法。
www.github.com/hannes-brt/hebel
mlxtend:它是一个由有用的工具和日常数据科学任务的扩展组成的一个库程序。
www.github.com/rasbt/mlxtend
nolearn:这个程序包容纳了大量能对你完成机器学习任务有帮助的实用程序模块。其中大量的模块和scikit-learn一起工作,其它的通常更有用。
www.github.com/dnouri/nolearn
Ramp:Ramp是一个在Python语言下制定机器学习中加快原型设计的解决方案的库程序。他是一个轻型的pandas-based机器学习中可插入的框架,它现存的Python语言下的机器学习和统计工具(比如scikit-learn,rpy2等)Ramp提供了一个简单的声明性语法探索功能从而能够快速有效地实施算法和转换。
www.github.com/kvh/ramp
Feature Forge:这一系列工具通过与scikit-learn兼容的API,来创建和测试机器学习功能。这个库程序提供了一组工具,它会让你在许多机器学习程序使用中很受用。当你使用scikit-learn这个工具时,你会感觉到受到了很大的帮助。(虽然这只能在你使用不同的算法时起作用。)
www.github.com/machinalis/featureforge
REP:REP是以一种和谐、可再生的方式为指挥数据移动驱动所提供的一种环境。它有一个统一的分类器包装来提供各种各样的操作,例如TMVA, Sklearn, XGBoost, uBoost等等。并且它可以在一个群体以平行的方式训练分类器。同时它也提供了一个交互式的情节。
www.github.com/yandex/rep
Python 学习机器样本:用亚马逊的机器学习建造的简单软件收集。
www.github.com/awslabs/machine-learning-samples
Python-ELM:这是一个在Python语言下基于scikit-learn的极端学习机器的实现。
www.github.com/dclambert/Python-ELM
原文:https://www.kdnuggets.com/2015/06/top-20-python-machine-learning-open-source-projects.html






