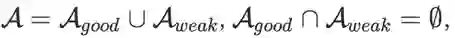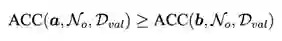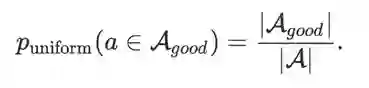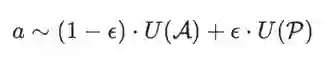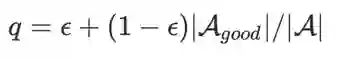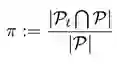本文介绍的是CVPR2020论文《GreedyNAS: Towards Fast One-Shot NAS withGreedy Supernet》,作者来自商汤。
![]()
论⽂地址:https://arxiv.org/abs/2003.11236
在CVPR 2020上,商汤移动智能事业群-3DAR-身份认证与视频感知组提出了基于贪心超网络的One-Shot NAS方法,显著提升了超网络直接在大规模数据集上的搜索训练效率,并在标准ImageNet数据集上取得了300M FLOPs量级的SOTA。GreedyNAS论文通过提出一种贪心的超网络结构采样训练方法,改善了训练得到的超网络对结构的评估能力,进而帮助搜索算法得到精度更高的结构。
在目前的神经结构搜索领域中,One-ShotNAS方法由于其搜索开销小被广泛应用,这些方法使用一个权重共享的超网络(supernet)作为不同网络结构的性能评估器,因此,supernet的训练对搜索结果的好坏至关重要。然而,目前的方法一般采用了一个基本的假设,即supernet中每一个结构是同等重要的,supernet应该对每个结构进行准确评估或相对排序。然而,supernet中所包含的结构量级(搜索空间的size)是非常巨大的(如7^{21} ),因此准确的评估对于supernet来说是非常困难的,导致supernet中结构的表现与其真实表现相关性很差 [1]。
在本篇论文中,我们提出一种贪心超网络来减轻supernet的评估压力,使得supernet更加贪心地注重于有潜力的好结构,而不是全体。具体而言,在supernet训练过程中,我们提出了一种多路径拒绝式采样方法(multi-path sampling with rejection)来进行路径滤波 (path filtering),使得有潜力的好结构得到训练。通过这种方法,supernet的训练从整个搜索空间贪心地缩小到了有潜力的结构组成的空间中,因此训练的效率得到了提升。同时,为了进一步增大有潜力结构的采样概率与提高训练效率,我们基于exploration and exploitation准则,使用一个经验池存储评估过的“好”结构,用来加强贪心度并为后续的搜索提供好的初始点。本论文搜索出的结构在ImageNet(mobile setting) 下取得了SOTA(state-of-the-art) 的结果。
巨大的搜索空间带来的评估压力使supernet难以准确地区分结构的好坏,由于所有结构的权重都是在supernet中高度共享的,如果一个差的结构被训练到了,好的结构的权重也会受到干扰。这样的干扰会削弱好网络的最终评估精度,影响网络的搜索结果。同时,对差的结构进行训练相当于对权重进行了没有必要的更新,降低supernet的训练效率。
1、多路径拒绝式采样
针对上述问题,一个直接的想法就是基于贪心策略,在训练过程中只训练好的结构。但很显然,我们并不知道一个随机初始化的搜索空间中哪些结构是好的。假设对于一个supernet,我们考虑其搜索空间A的一个完备划分,即:
![]()
搜索空间可以如上划分为好的空间与差的空间,且好空间中每一个结构的ACC均大于差空间,即
![]()
于是,一个理想的采样策略是直接在好空间中进行采样即可。然而根据上面的不等式,确定所有结构中哪些是来自好空间需要遍历整个搜索空间,计算开销是无法接受的。为了解决这个问题,我们首先考虑从全空间中进行的一个均匀采样,那么每个path来自好空间的概率为:
![]()
为了得到需要的来自于好空间的结构,我们进一步考虑一个多维的Bernoulli实验,那么有如下的结论:
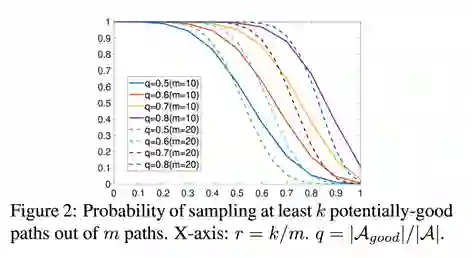
我们取m = 10和m = 20,对定理1的概率进行绘制,如Figure 2所示,可见这种采样下得到来自好空间中的path的概率是很高的。
![]()
于是,我们可以对采样到的多个结构进行评估筛选的方法提升采样到“好”结构的概率,即每次采样m个结构,从中选取评估指标最高的k个结构进行训练。但是,对结构进行评估需要在验证集上计算其ACC,这样会增加非常多计算量(我们的ImageNet验证集大小为50k)。为了减少评估网络的消耗,我们从验证集中随机选取了一小部分(如1000张图)组成小验证集,并使用在小验证集上的loss作为结构的排序指标。使用小验证集进行评估,在保证评估准确性的前提下,相较uniformsampling方法只增加了很少的计算代价,详见论文实验部分。
2、基于exploration and exploitation策略的路径候选池
![]()
在前面提到的路径滤波中,我们通过评估可以区分出较好的结构,为了进一步提升训练效率,受蒙特卡洛树搜索(Monte Carlo tree search)[4] 和 deep Q-learning[5] 中常用的exploration and exploitation策略启发,我们提出使用一个路径候选池用于存放训练过程中评估过的“好”结构,并进行重复利用。具体而言,候选池可以看作是一个固定大小的有序队列,其只会存储所有评估过结构中得分前n(候选池大小) 的结构。
有了候选池的帮助,我们可以选择从搜索空间中或候选池中采样结构。从候选池中采样的结构是好结构的概率更高,但可能会牺牲结构的多样性。为了平衡exploration与exploitation,我们采用ϵ-采样策略,即以一定的概率从整个搜索空间A或候选池P中采样结构α:
![]()
在网络刚开始训练时评估过的结构较少,候选池中存储的结构是好结构的可信度不高,因此从候选池中采样的概率ϵ在开始时设为0,并线性增加至一个较高的值(在实验中,我们发现0.8是一个较优的值)。若候选池中的结构都来自好空间,通过使用候选池,定理1中好网络的采样概率q提升为:
![]()
因此,采样10个结构,至少有5个好结构的概率由88.38%提升至99.36% 。
![]()
候选池的更新为supernet的训练情况提供了一个很好的参考。若候选池发生的更新(顺序变换、进出)较少,可以认为超网络中较好的网络维持着一个相对稳定的排序,这也说明此时的supernet已经是一个较好的性能评估器,因此训练进程可以提前结束,而不需要训练至网络完全收敛。
在实际使用中,我们会比较当前候选池P与t轮迭代前的候选池P_t的差异度,若差异度低于某个数值(我们的实验使用0.08),训练停止。差异度的定义如下:
![]()
![]()
4、基于候选池的搜索策略
Supernet训练结束后,我们可以使用验证集的ACC评估结构的好坏。本文使用NSGA-II 进化算法[3] 进行结构搜索。我们在进化算法中使用候选池中的结构进行population的初始化,相较于随机初始化,借助于候选池能够使进化算法有一个更好的初始,提升搜索效率及最终的精度。
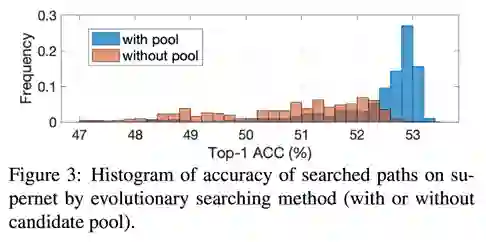
如 Figure 3 所示,我们在同一个训练好的supernet上使用了随机初始化与候选池初始化两种方式进行搜索,使用候选池初始化搜索到的结构的准确率平均会比随机初始化要高。
![]()
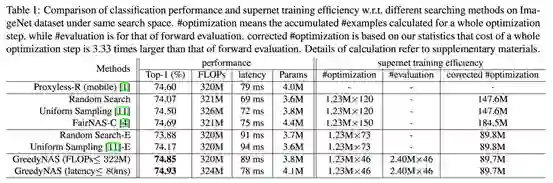
为了与目前的one-shot方法进行对比,我们首先在与 ProxylessNAS[6] 一样的 MobileNetV2 搜索空间上进行结构搜索,结果见 Table 1 。
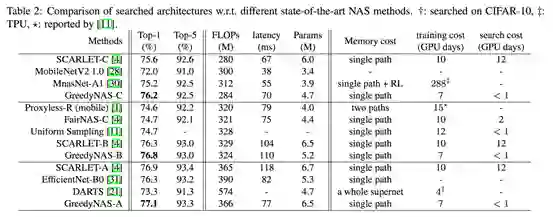
同时为了进一步提升网络性能,我们在加入了SE的更大搜索空间上进行搜索,结果见 Table 2 。
![]()
我们对随机初始化、uniformsampling、greedy方法训练得到的supernet下的小验证集指标与完整验证集ACC相关性进行了评估,如 Table 3 所示。可见在小验证集上使用loss相比ACC会得到更高的相关性,我们的贪心方法训练出的supernet有着更好的相关性。
![]()
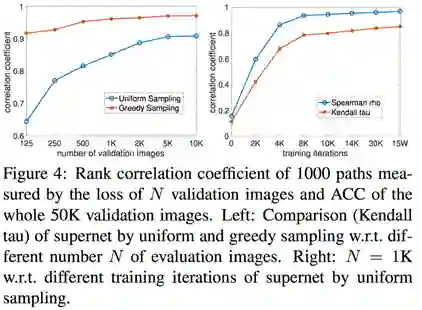
我们对不同大小小验证集与完整验证集的相关性进行了评估(Figure 4 左图),同时对uniform-sampling算法在不同迭代轮数下的相关性作了评估(Figure 4 右图)。可以看出我们的算法在较小的验证集大小上仍能保持较高的相关性,在精度与效率的权衡下,我们最终选取 1000 作为小验证集大小。
![]()
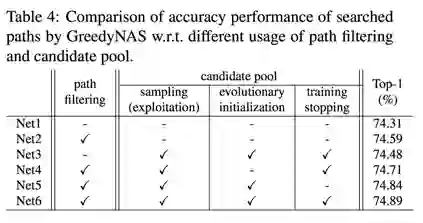
我们在MobileNetV2的search space下评估了多路径贪心采样及候选池的效果,如 Table 4 所示。
![]()
超网络训练是单分支One-ShotNAS 方法的关键。与目前方法的对所有分支一视同仁不同,我们的方法贪心地注重于有潜力的好分支的训练。这种贪心地分支滤波可以通过我们提出的多分支采样策略被高效地实现。我们提出的 GreedyNAS 在准确率和训练效率上均展现出了显著的优势。
![]()