R语言和表数据分析
【数萃大数据】公众号又开办了一个新栏目,之后我们每周末会为大家分享各种趣闻趣事名人好书。
我们将连续转载史春奇老师高品质的推文。感谢史春奇老师的授权以及对数萃大数据学院的大力支持!
R语言发展之快, 已经连续几年夺取数据分析第一把交椅!
最近几年, 对于表数据分析有一些常见的问题, 譬如: 缺失值(Missing), 奇异值(Outlier)(参考 “一个奇异值的江湖 -- 经典统计观” 和 “一个奇异值的江湖 -- 机器学习观”), 非平衡数据(Imbalanced)(参考 “非均衡数据处理--如何学习?” 和 “非均衡数据处理--如何评价?”),数据转换(Transformation) (参考 “数据变换”), 特征选择(Feature Selection)(参考 “特征选择, 经典三刀”)等等。
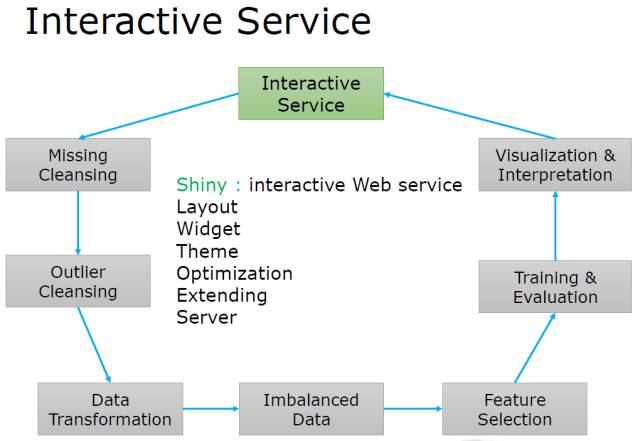
如何利用R语言, 把这些数据处理,分析,可视化的流程结合起来, 建立一个交互式数据分析平台? 为什么要一个交互式数据分析平台呢? 具体可以参考前面的讲述 “Shiny: R语言来建立开源交互式数据分析微服务的神器” !
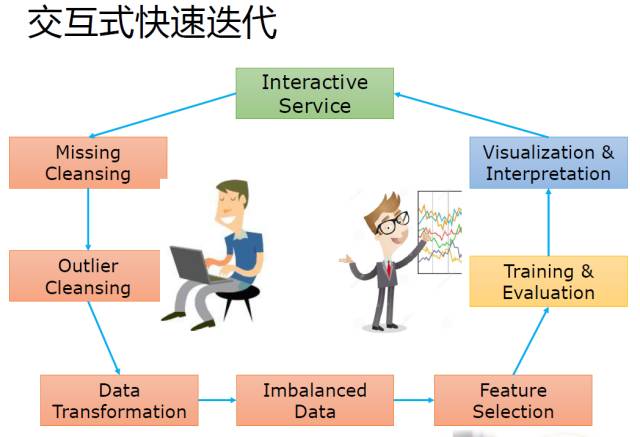
那么在整个过程中的每个步骤, 有哪些R语言包可以应用呢?
R语言包
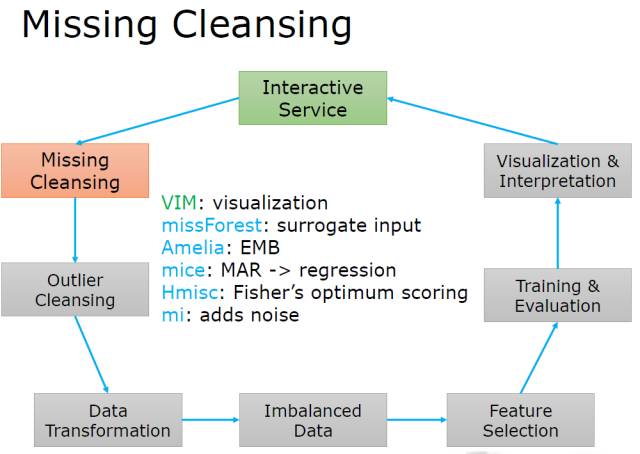
缺失值(Missing)
主要强调了常见方法的同时, 要注重缺失值的可视化! 这在对哪些缺失值, 和说服采集更多数据的时候特别有用。
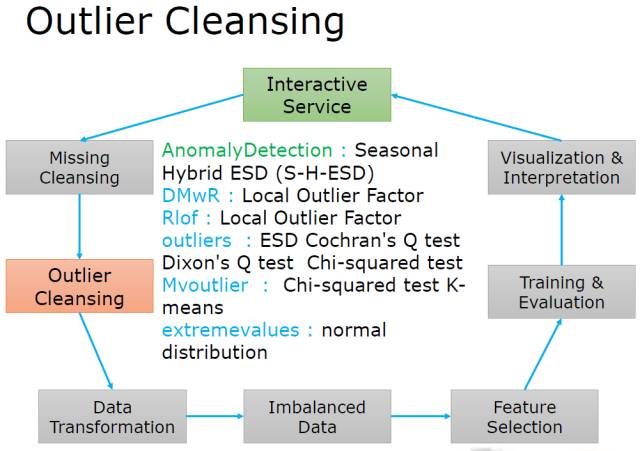
奇异值(Outlier)
特别强调统计的ESD方法, 或者说Grubbs' test的尝试。 当然分组数据的异常要利用Dixon‘ Q Test。
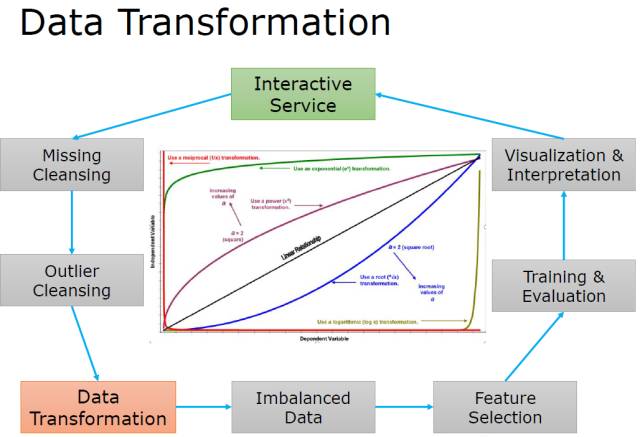
数据转换(Transformation)
强调一个经验公式, 根据数据频率分布和转换函数的对称性(y=x对称)选择处理函数。
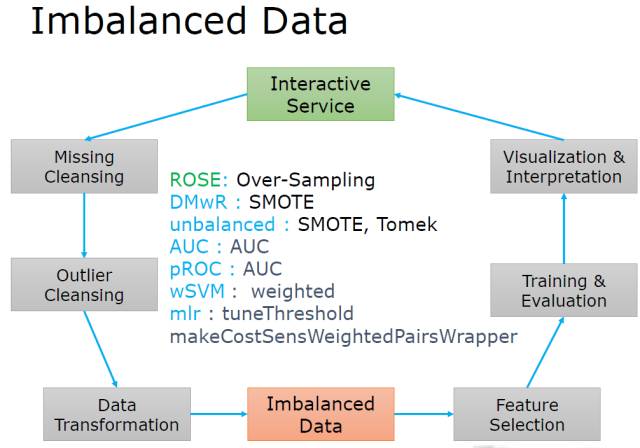
非平衡数据(Imbalanced)
强调样本方法和Cost-Sensitive算法同时尝试!
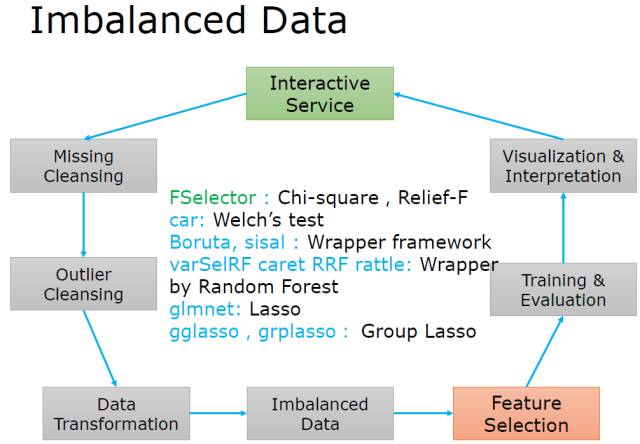
特征选择(Feature Selection)
强调三刀都要砍一砍!
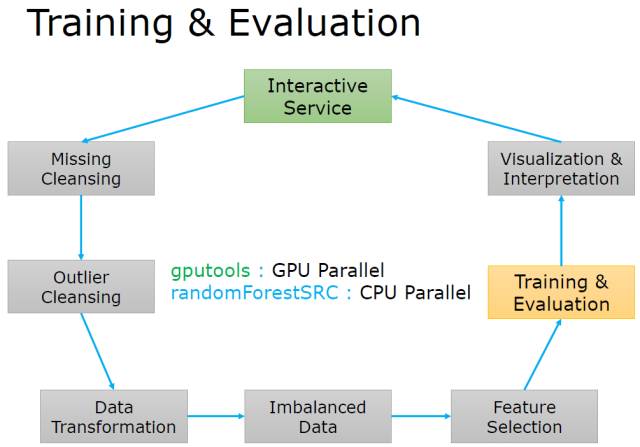
训练和评价(Training & Evaluation)
强调大数据之大, 不光光是数据量大, 也可能是计算量大, 如何利用好平行来提速, CPU并行和GPU并行,解决计算量大的问题!
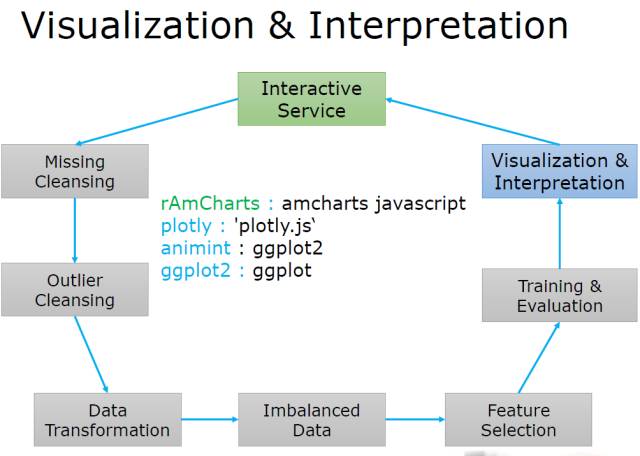
可视化和解释(Visualization & Interpretation)
强调利用一些基于javascript的交互式可视化, 可以做到重点突出和层次感!
交互服务 (Interactive Service)
基于Shiny可以创建一个交互式服务!从前台到后台, 一应俱全~
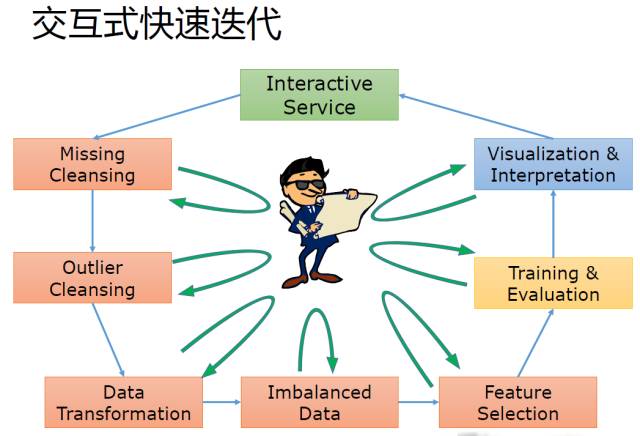
快的交互!
最后强调, 基于Shingy 交互的目的之一就是快(容易理解), 天下武功, 无坚不摧, 唯快不破!
更为详细的解释(50页PPT)请点击下方 “阅读原文”
小结, 给出了一个表数据分析的流程中可以选择的R语言包, 让你快速的构建一个数据分析微服务。 让老板觉得你的快,就是他的钱!




欢迎参加【杭州站】Python大数据分析培训
8月18日-22日
扫描下方二维码了解更多




