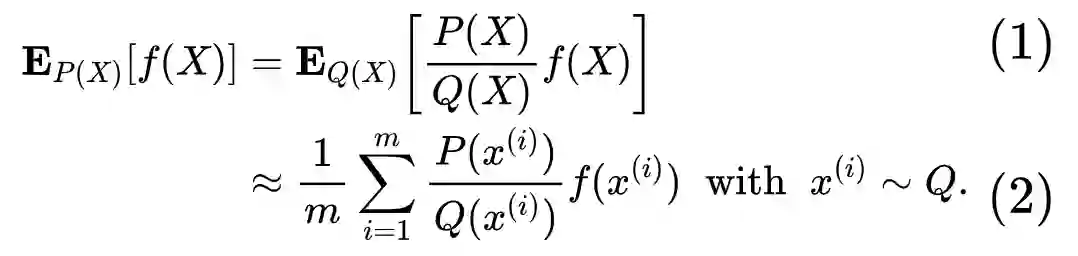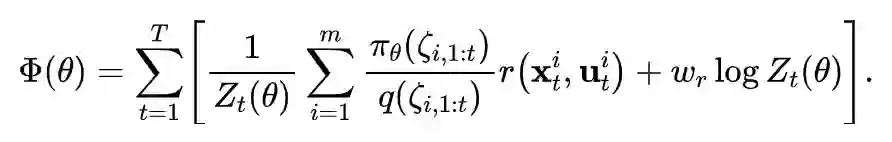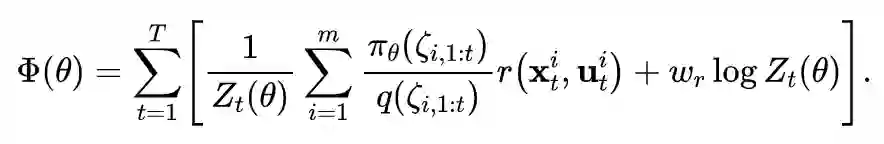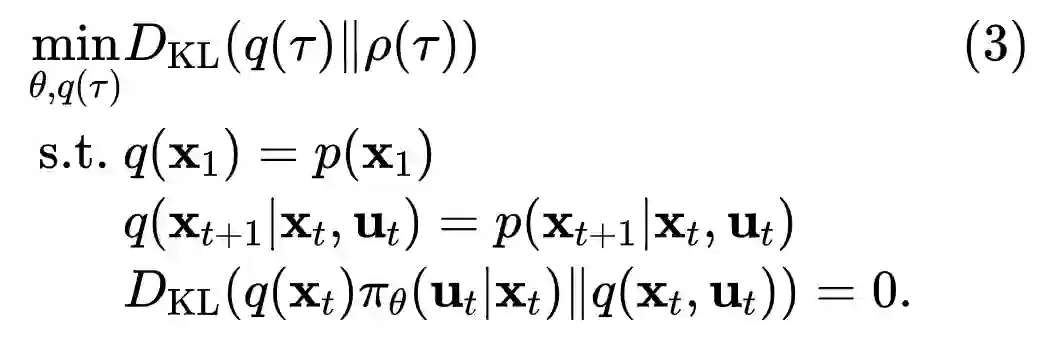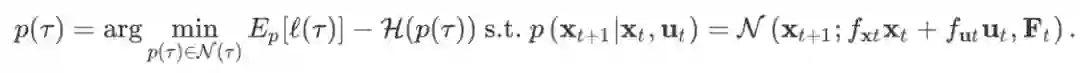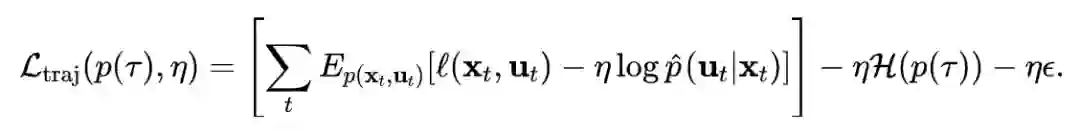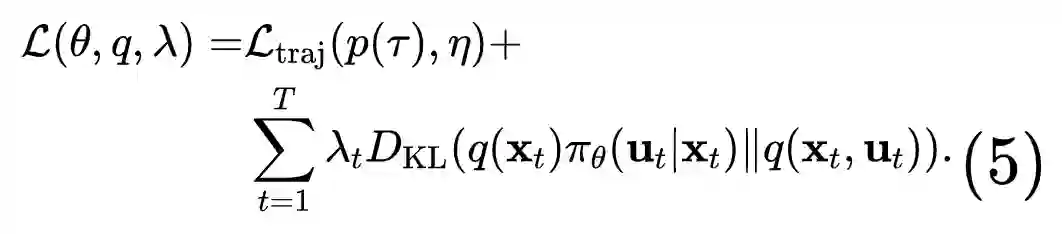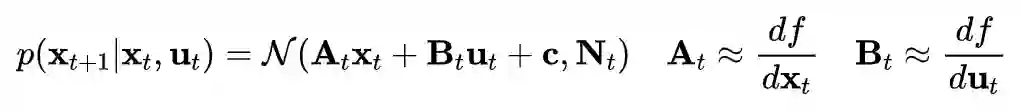Since each trajectory-centric teacher only needs to solve the task from a single initial state, it is faced with a much easier problem. The final policy is trained with supervised learning, which allows us to use a nonlinear, high-dimensional representation for this final policy, such as a multilayer neural network, in order to learn complex behaviors with good generalization.
A key component in guided policy search is adaptation between the trajectories produced by the teacher and the final policy. This adaptation ensures that, at convergence, the teacher does not take actions that the final policy cannot reproduce.
This is realized by an alternating optimization procedure, which iteratively optimizes the policy to match each teacher, while the teachers adapt to gradually match the behavior of the final policy.
参考文献
[1] Zhang, Marvin, et al. "Learning deep neural network policies with continuous memory states." 2016 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2016.[2] Levine, Sergey, and Vladlen Koltun. "Guided policy search." International Conference on Machine Learning. 2013.[3] Levine, Sergey, and Vladlen Koltun. "Learning complex neural network policies with trajectory optimization." International Conference on Machine Learning. 2014.[4] Levine, Sergey, and Pieter Abbeel. "Learning neural network policies with guided policy search under unknown dynamics." Advances in Neural Information Processing Systems. 2014.[5] Dvijotham, Krishnamurthy, and Emanuel Todorov. "Inverse optimal control with linearly-solvable MDPs." Proceedings of the 27th International Conference on Machine Learning (ICML-10). 2010.[6] Jie, Tang, and Pieter Abbeel. "On a connection between importance sampling and the likelihood ratio policy gradient." Advances in Neural Information Processing Systems. 2010.
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。