开放域长格式问答系统的进步与挑战


发布人:Google Research 研究员 Aurko Roy
开放域长格式问答 (LFQA) 是自然语言处理 (NLP) 的一项基础挑战,涉及检索与给定问题相关的文档,并使用这些文档来生成一段详尽答案。在事实型开放域问答 (QA) 中,简单的短语或实体便足以回答问题。虽然我们近期在这一方面取得了显著进展,但在长格式问答领域中却做得远远不够。尽管如此,LFQA 仍是一项非常重要的任务,特别是它能提供一个测试平台来衡量生成文本模型的真实性。但是,当前的基准和评估指标真的能在 LFQA 方面取得进展吗?
在“在长格式问答领域取得进展的障碍”(Hurdles to Progress in Long-form Question Answering)(将在 NAACL 2021 会议上发表)中,我们介绍了一种新的开放域长格式问答系统,它利用了 NLP 的两项最新进展:
1. 最先进的稀疏注意力模型(例如 Routing Transformer(RT)),能够将基于注意力的模型扩展至长序列;
2. 基于检索的模型(例如 REALM),有助于检索与给定查询相关的维基百科文章。
Routing Transformer
https://www.mitpressjournals.org/doi/full/10.1162/tacl_a_00353
为获得更多的事实依据,对于检索到的与给定问题相关的一些维基百科文章,我们的系统会在答案生成之前将从中获得的信息结合起来 ELI5 是唯一一个可用于长格式问答的大规模公开数据集,我们的系统在该数据集上取得了突破性进展。
ELI5
https://ai.facebook.com/blog/longform-qa/
不过,虽然这个系统在公开排行榜上名列前茅,但我们发现 ELI5 数据集及其相关评估指标的一些趋势令人担忧。特别要强调的是,我们发现 1) 几乎没有证据表明模型实际使用了它们所要求的检索;2) 平凡基线(例如输入复制)击败了现代系统,如 RAG/BART+DPR;以及 3) 数据集中存在大量训练/验证重叠。我们的论文针对每一个问题提出了缓解策略。
输入复制
https://eval.ai/web/challenges/challenge-page/689/leaderboard/1908#leaderboardrank-6


NLP 模型的核心要件是 Transformer 架构,其序列中的每个 Token 都会关注序列中的其他所有 Toekn,从而形成一个随序列长度呈二次增长的模型。RT 模型引入了一种基于内容的动态稀疏注意力机制,将 Transformer 模型中的注意力复杂度从 n2 降到了 n1.5( 其中 n 是序列长度),使其能够扩展到长序列。这使得每个单词都可以关注整个文本中 任何地方的其他相关单词, 而不像 Transformer XL 等类似方法,一个单词只能关注其附近的单词。
RT 发挥作用的关键在于每个 Token 对其他 Token 的关注通常是冗余的,并且可以通过结合局部和全局注意力进行估算。局部注意力允许每个 Token 在模型的几个层上建立一个局部表征,其中每个 Token 关注一个局部邻域,从而达到局部的一致性和流畅性。作为对局部注意力的补充,RT 模型还使用了小批量 k-均值集群, 使每个 Token 只关注一组最相关的 Token 。
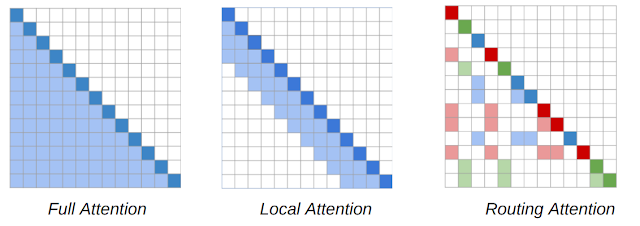
注意力地图(针对在 Routing Transformer 中使用的基于内容的稀疏注意力机制)。单词序列由对角深色方块表示。在 Transformer 模型中(左),每个Token 都关注其他 Token。阴影方块表示给定 Token(黑色方块)正在关注的序列中的 Token。RT 模型使用局部注意力机制(中),其中 Token 仅关注其局部邻域中的其他 Token;同时也使用路由注意力机制(右),其中 Token 仅关注上下文中与其相关性最强的 Token 集群。深红色、绿色和蓝色 Token 仅关注对应浅色的阴影 Token。
我们以语言建模为目标,使用 ProjectGutenberg(PG-19) 数据集预先训练了一个 RT 模型,即在给定前面所有单词的情况下,让该模型学会预测下一个单词,从而能够生成流利的段落长文本。
ProjectGutenberg(PG-19)
https://deepmind.com/blog/article/A_new_model_and_dataset_for_long-range_memory
为了证明 RT 模型在 LFQA 任务中的有效性,我们将其与 REALM 中检索到的内容结合使用。REALM 模型(Guu 等人于 2020 年发布)是基于检索的模型,使用最大内积搜索来检索与特定查询或问题相关的维基百科文章。我们对该模型进行了微调,以便根据自然问题数据集作出事实型问答。REALM 利用 BERT 模型学习问题的良好表征,并使用 SCANN 检索与问题表征具有高度主题相似性的维基百科文章。接着进行端到端训练,以最大程度地提高 QA 任务的对数似然值。
通过使用对比损失,我们进一步提高了 REALM 检索的质量。其背后的想法是让问题表征更靠近其基本事实答案,并与其他小批量答案有所不同。这样可以确保,当系统使用此问题表征检索相关项目时,会返回与基本事实答案“类似”的文章。我们称这种检索器为对比型-REALM 或 c-REALM。
对比损失
https://towardsdatascience.com/contrastive-loss-explaned-159f2d4a87ec

针对 LFQA 的 RT+c-REALM 组合系统
我们使用 ELI5 数据集对该模型进行了长格式问答测试。ELI5 数据集是 KILT 基准的一部分, 也是唯一 公开可用的大规模 LFQA 数据集。KILT 基准使用准确率 (R-Prec) 衡量文本检索质量,并使用 ROUGE-L 衡量文本生成质量。将这两项得分相加即可得出一个 KILT R-L 得分,该得分决定了模型在排行榜上的排名。在 KILT 的 ELI5 数据集上,我们对预先训练好的 RT 模型和 c-REALM 检索进行了微调。
我们提交的内容在 ELI5 长格式问答 KILT 排行榜上名列前茅,综合 KILT R-L 得分为 2.36。对比先前 BART + DPR 排行榜的排名(KILT R-L 得分为 1.9)有了提升,同时具有与排行榜上其他模型相似的参数数量。在文本生成质量方面,我们发现 Rouge-L 与 T5、BART + DPR 和 RAG 相比,得分分别提高了 4.11、5.78 和 9.14。
排行榜
https://eval.ai/web/challenges/challenge-page/689/leaderboard/1908
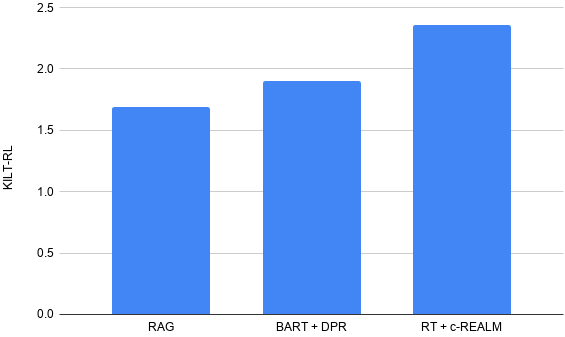
我们在 ELI5 长格式问答 KILT 排行榜上的结果
<<< 左右滑动查看更多 >>>
不过,虽然此处介绍的 RT 系统在公开排行榜中名列前茅,但对模型和 ELI5 数据库的详细分析仍揭示了一些令人担忧的趋势。
<<< 左右滑动查看更多 >>>
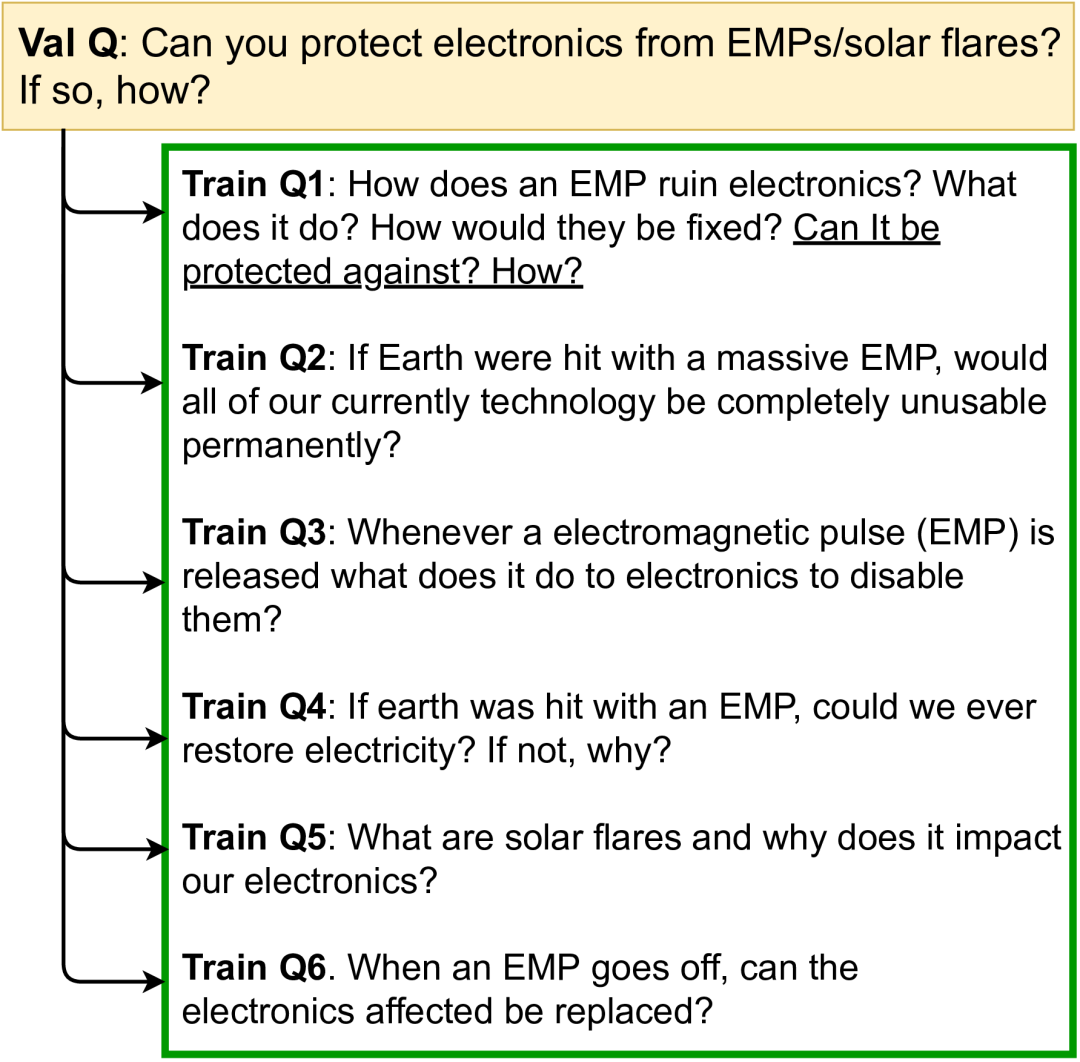


我们发现,几乎没有任何证据表明模型会将其文本生成实际定位到检索文档中。与 Wikipedia 中的随机检索搭配使用的微调 RT 模型(例如,随机检索 + RT),几乎与 c-REALM + RT 模型(24.2 与 24.4 ROUGE-L)表现得一样好。在训练、验证和测试 ELI5 数据集时,我们还发现了很多的重叠(几个问题相互解释),因此可能不再需要检索。KILT 基准会单独衡量检索和生成的质量,但不确定文本生成是否会在实际情况中使用检索。
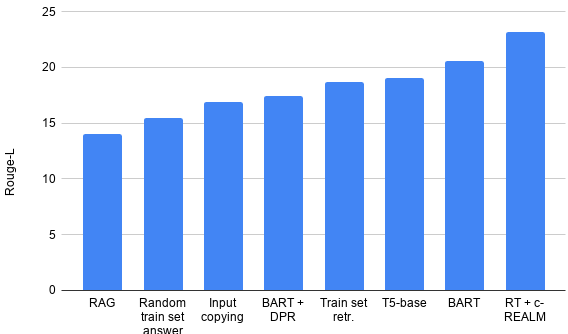
与 RAG 和 BART + DPR 相比,平凡基线会获得更高的 Rouge-L 分数
此外,在使用 Rouge-L 指标和平凡无意义基线(如随机训练集答案和输入复制)来评估文本生成质量的过程中,我们发现了一些问题,并导致 Rouge-L 分数相对较高(甚至超过了 BART + DPR 和 RAG)。
我们为基于 Routing Transformers 和 REALM 的长格式问答推出了一个系统,该系统在关于 ELI5 的 KILT 排行榜中名列前茅。但是,详细的分析揭示了存在的一些问题,即无法使用基准来显示有意义的建模进展。我们希望社区共同合作,一起解决这些问题,以便研究人员向正确的高峰攀登,在这个充满挑战但十分重要的任务中取得有意义的进展。
Routing Transformer 是 Aurko Roy、Mohammad Saffar、Ashish Vaswani 和 David Grangier 等人进行团队协作的结果。有关开放域长格式问答的后续工作是由 Kalpesh Krishna、Aurko Roy 和 Mohit Iyyer 协作完成的。我们要感谢 Vidhisha Balachandran、Niki Parmar 和 Ashish Vaswani 提供的多条实用意见,感谢 REALM 团队 (Kenton Lee、Kelvin Guu、Ming-Wei Chang 和 Zora Tung) 在代码库方面提供的帮助以及多条实用意见,这些意见帮助我们进一步完善了实验。我们非常感谢 Tu Vu 针对 QQP 分类器提供的帮助,这些分类器用于在 ELI5 训练集和测试集中检测解释。感谢 Jules Gagnon-Marchand 和 Sewon Min 对检查 ROUGE-L 边界提供的有用实验建议。最后,感谢 Shufan Wang、Andrew Drozdov、Nader Akoury 以及 UMass NLP 小组的其他成员针对项目的不同阶段提出的实用意见和建议。

点击“阅读原文”访问 TensorFlow 官网

不要忘记“一键三连”哦~

分享

点赞

在看




