数据库并发2万就跪了?你需要这份指导性的知识框架

如果各位看官的 SQL 数据库真有 2W+ 高并发,那真是要恭喜你。你已经比很多公司的 MIS 都要前卫得多。
2W 和 2K 差别有那么大吗?
嗯,真是有的。2K 并发的 MIS 系统也经常有无法访问,timeout 的异常,处理这些异常已经够很多朋友苦恼的了。2W+ 的并发那需要懂的知识框架就更复杂了。
笔者曾服务了 500W+ 用户的电商系统,7*24 小时的噩梦再也不想见。
前几年在一家拥有 500 多万直销顾问的团队做电商平台。平时的流量很平稳,基本都在千把,月底拼业绩才会冲一冲,来个 1W+ 的并发。
大部分的数据库开发人员在日常中还是没心没肺没压力的。但电商系统有个惯例,都是淘宝带出来的,会搞促销,类似于双 11. 一到这时间段,必须随时警惕流量是不是井喷,一旦跨越红线,系统就跟前期的 12306 一样,频频延迟。
随着 DBA 组的介入,才慢慢搞定这难题。本文的初衷也来自于这段经历的总结。
一、单实例数据库应用
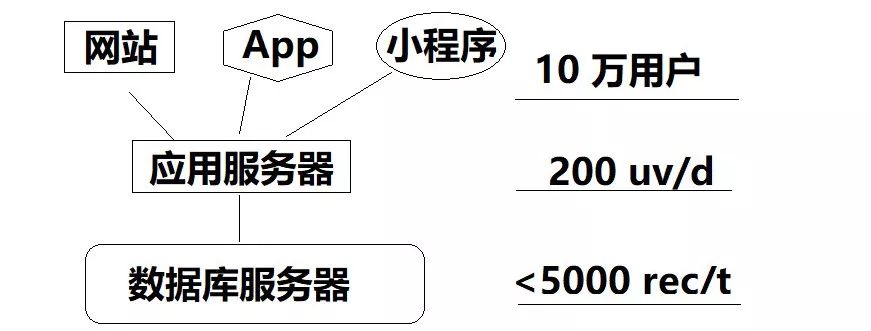
这种应用架构最简单,UI + 应用服务器 + 数据库服务器,所有的请求,无论读写都直接抛给数据库。
往往项目初期,为了迅速的证明自己的点子靠谱,拿到市场,我们会选择这样的架构来实现产品。此时往往 10 万用户注册了,但每天访问的人数刚过 200,每张数据库表的总数,最大也不会超过 5000 条。
这样的应用,开发能力强的,1 个人就可以搞定,业务复杂的需要分前端和后端。
但无论如何都属于基础项目,如果你工作 3,4 了还是停留在这种模式下,那该补补课了。
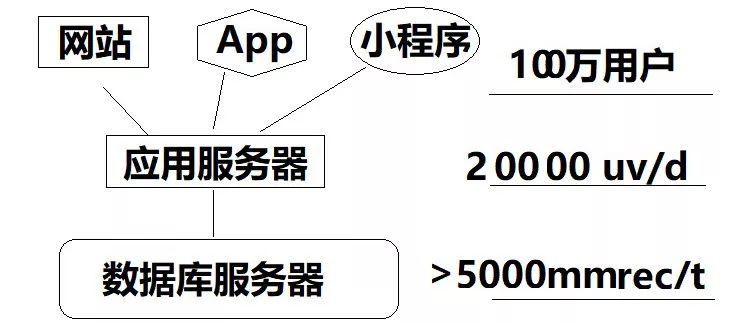
事物总是在发展之中的,只要系统正常运行,总有一天用户量会加大,随之而来的请求会超乎你的想象(前提你是做了 pv, uv 的数据分析),很快这种架构会遇到用户超过 100 万,日访问量超过 20 万,峰值并发 2 万,而数据库的表会趋近于亿级的量。
此时应用系统如果还是建立在当初的硬件基础上(比如 16GB,16 核,240GB 硬盘)应该会明显感觉得到拖卡慢的尴尬,增多的是用户的抱怨和投诉。
就像 12306 前期的购票一样,往往轮到你的时候,票没了。
二、多实例数据库
遇到流量起来的应用,如果压力确定是在数据库上了,那么分库是必然的事情了。
将一个大库拆成若干小库,保持数据库对象都一致,这样每个小库分摊掉一部分流量,应用终将回归第一种简单架构上来,将用户服务好。
以现在的硬件服务 4000 个并发,对于不复杂的商用没有问题。具体能负责多少看系统上线后的 baseline (基线)监测,这里我们假定 4000 并发。所以分成 5 个相同的库,来做分库。这样同时写入 4000 并发够用。
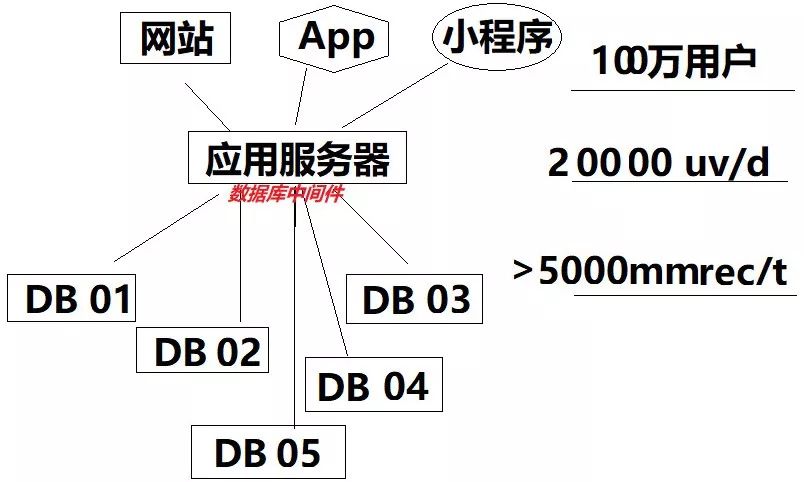
这里会遇到一个技术细节,就是分库路由。
如何将流量均摊到每个库里,是需要研制算法的。比如已知全国用户分布均衡,即华东、华北、华西、华南和华中,各有 4000 用户。
我们依据地理位置分成 5 个库,根据用户身份证哈希成 5 个散列值,分别对应了这 5 台数据库,用户就被分流了。
只要用户不是剧烈增长,老板也满意这种小而美的生意,这样的架构可以一直沿用下去。基本不会有瓶颈。顶多就是时间长了,表数据越来越大了,我们用分库的思想进行分表就可以了。
当前年份(月份)数据放在主表里面,而历史数据就归档到聚合表里;或者索性每月,每年分成子表存储,而跨时间段的查询用视图来控制。
但用户的行为始终是不可控的,我么必须做一系列的事情来满足和留住用户。比如促销、打折、团购等等。
这个时候,用户的行为不仅仅是下个单买杯咖啡这么简单了。他们会大量查询他们的数据,带来的是读请求远远大于写入请求。
众所周知,读请求即使不影响写入请求(比如 MVVC),但也会耗尽服务器的 CPU\IO\Network 资源。那么我们必须更进入一层,读写分离。
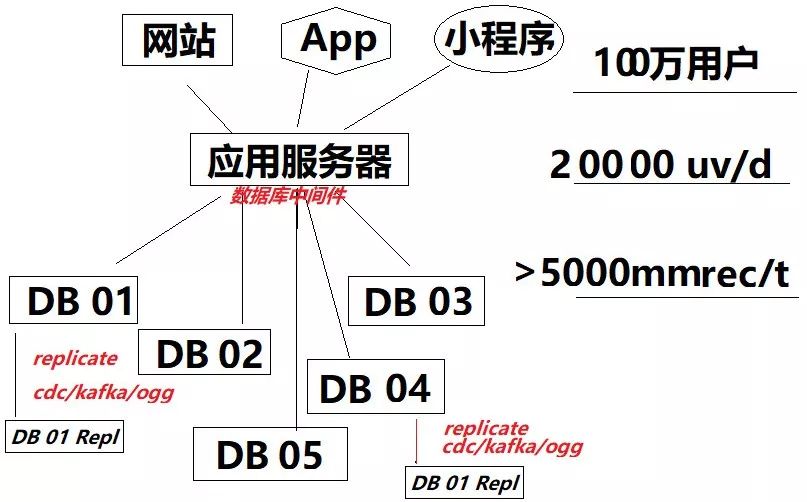
三、读写分离
读写分离是另一种分库,但与前面的分库意图不一样。分出来的库和源库一模一样,且只读不接收用户的写入请求。实现细节每个数据库都不一样,也可以使用实时同步工具做,详情可以参考《Designing Data-Intensive Applications》这本书。不仅仅给出了指导思想,更有每种数据库的读写分离组件指南。
作者:Lenis
来源:有关SQL订阅号(ID:SQLHub)
dbaplus社群欢迎广大技术人员投稿,投稿邮箱:editor@dbaplus.cn

掌握数据库管理新思路,获得更优操作启发
不妨来DAMS学点独家技能
↓↓扫码可了解更多详情及报名↓↓
2019 DAMS中国数据智能管理峰会-上海站






